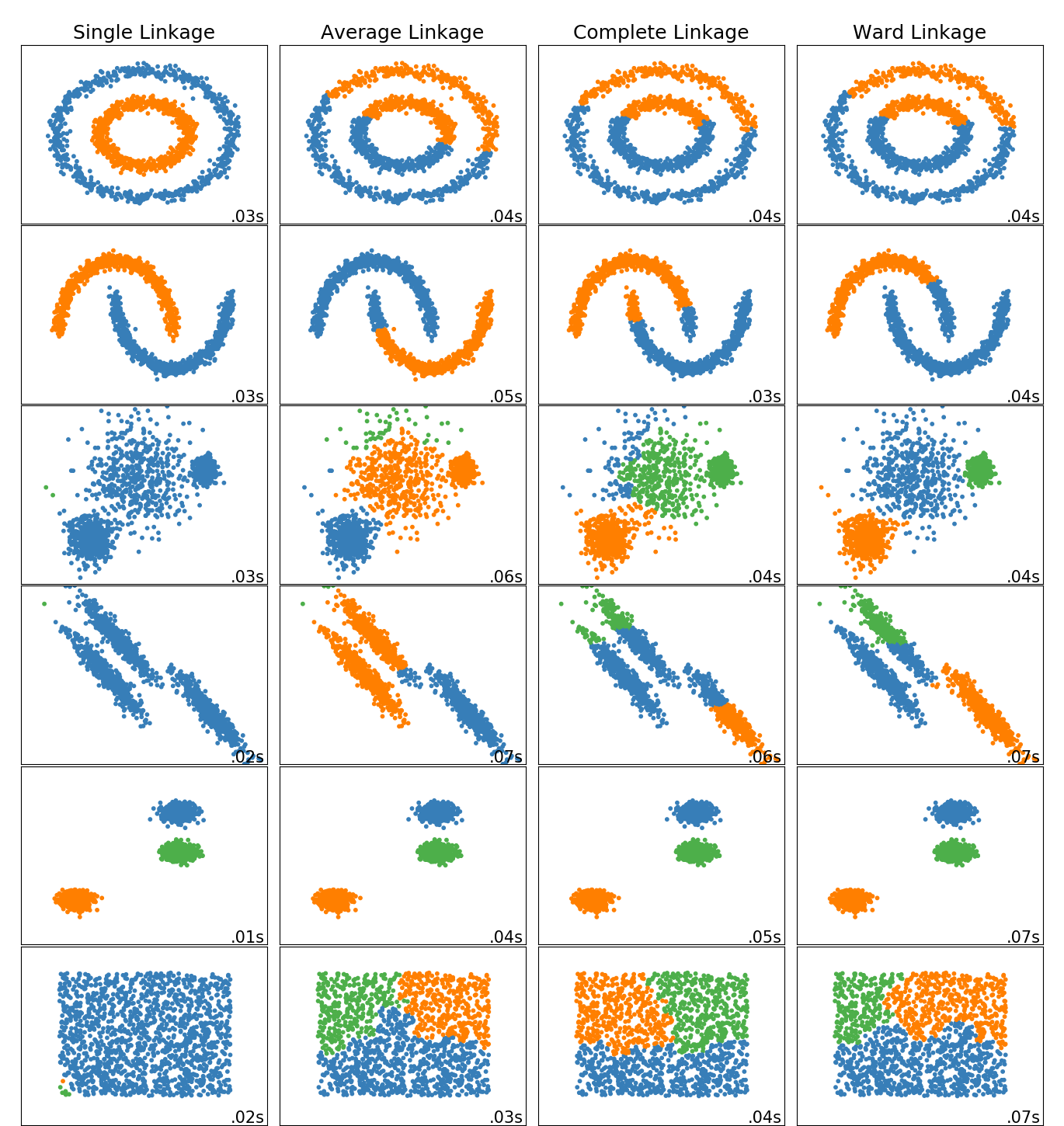
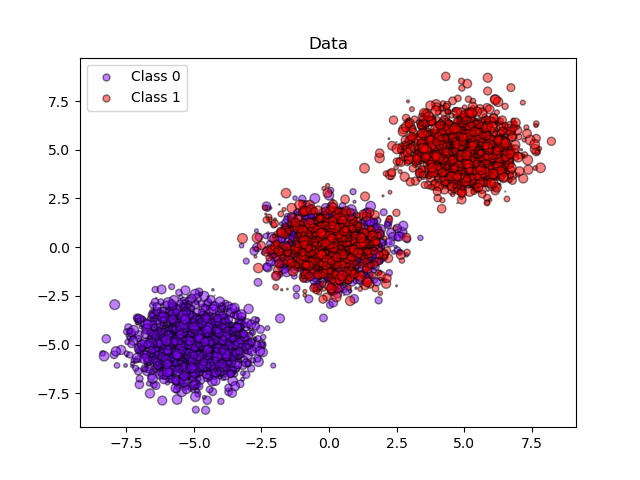
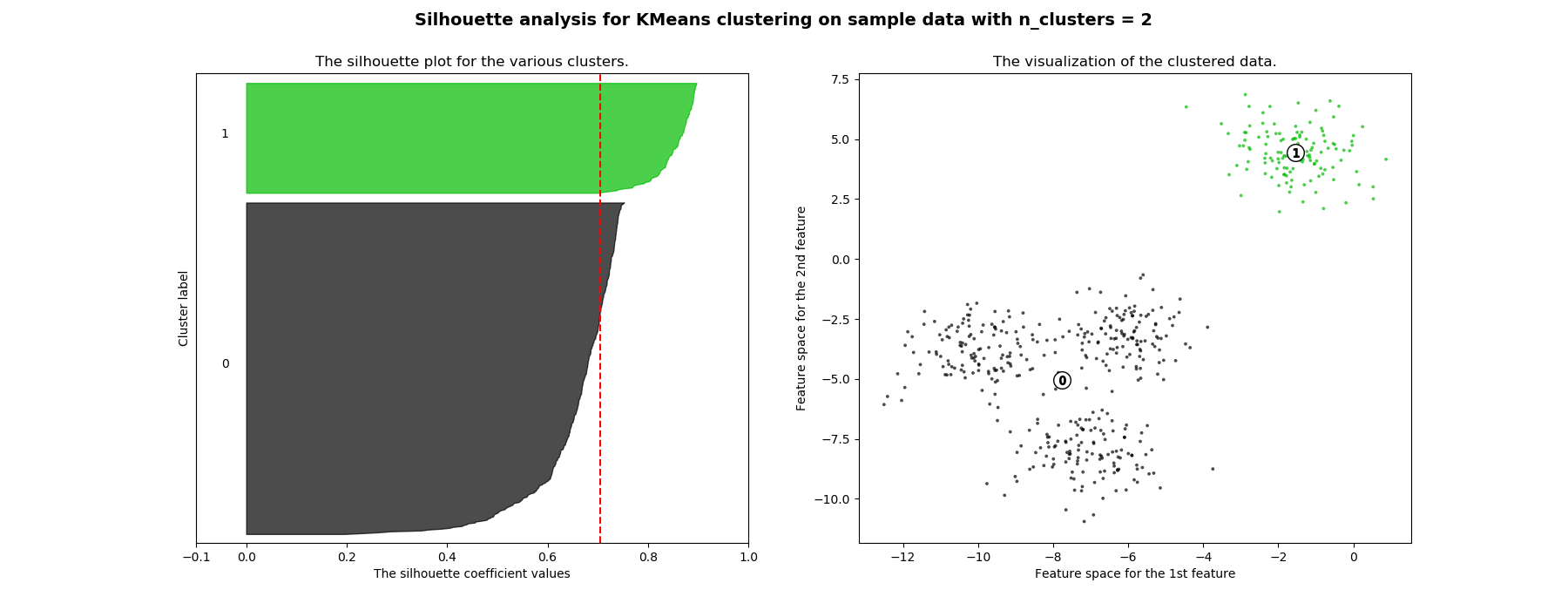
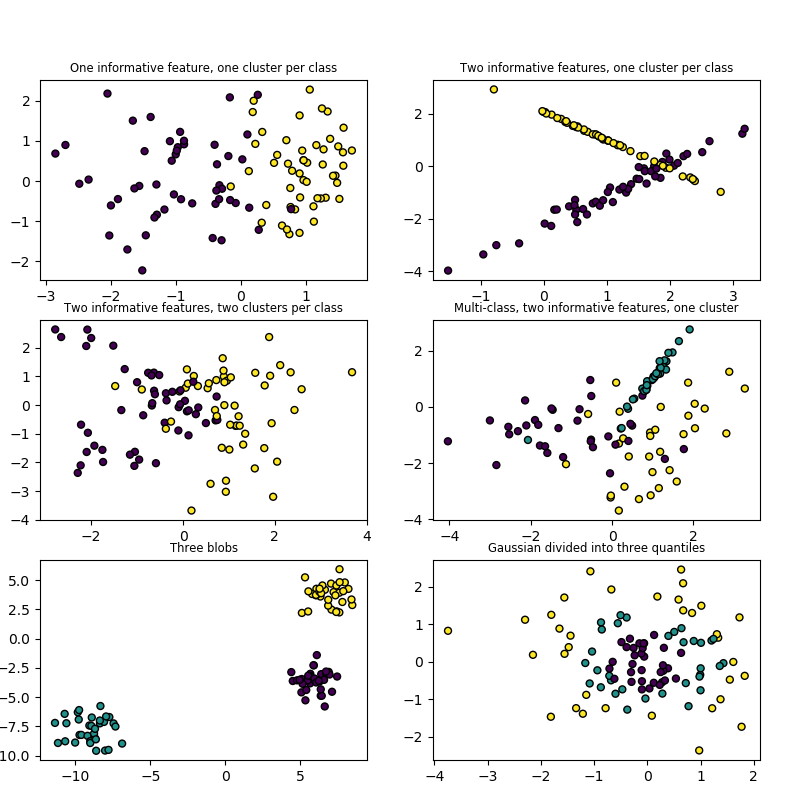
sklearn.datasets.make_blobs¶
sklearn.datasets.make_blobs(n_samples=100, n_features=2, *, centers=None, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None, return_centers=False)
生成各向同性的高斯Blob进行聚类。
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| n_samples | int or array-like, optional (default=100) 如果为int,则为在簇之间平均分配的点总数。如果为阵列状,则序列的每个元素表示每个簇的样本数。 v0.20版中进行了更改:现在可以将类似数组的参数传递给n_samples参数 |
| n_features | int, optional (default=2) 每个样本的特征数量。 |
| centers | int or array of shape [n_centers, n_features], optional (default=None)要生成的中心数或固定的中心位置。如果n_samples是一个int且center为None,则生成3个中心。如果n_samples类似于数组,则中心必须为None或长度等于n_samples长度的数组。 |
| cluster_std | float or sequence of floats, optional (default=1.0) 群集的标准偏差。 |
| center_box | pair of floats (min, max), optional (default=(-10.0, 10.0)) 随机生成中心时每个聚类中心的边界框。 |
| shuffle | boolean, optional (default=True) shuffle样本 |
| random_state | int, RandomState instance, default=None 确定用于生成数据集的随机数生成。为多个函数调用传递可重复输出的int值。请参阅词汇表。 |
| return_centers | bool, optional (default=False) 如果为True,则返回每个群集的中心 0.23版中的新功能。 |
| 返回值 | 说明 |
|---|---|
| X | array of shape [n_samples, n_features] 生成的样本。 |
| y | array of shape [n_samples] 每个样本的群集成员的整数标签。 |
| centers | array, shape [n_centers, n_features] 每个群集的中心。 仅在return_centers = True时返回。 |
另见
更复杂的变体
示例
>>> from sklearn.datasets import make_blobs
>>> X, y = make_blobs(n_samples=10, centers=3, n_features=2,
... random_state=0)
>>> print(X.shape)
(10, 2)
>>> y
array([0, 0, 1, 0, 2, 2, 2, 1, 1, 0])
>>> X, y = make_blobs(n_samples=[3, 3, 4], centers=None, n_features=2,
... random_state=0)
>>> print(X.shape)
(10, 2)
>>> y
array([0, 1, 2, 0, 2, 2, 2, 1, 1, 0])