sklearn.datasets.make_classification¶
sklearn.datasets.make_classification(n_samples=100, n_features=20, *, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None)
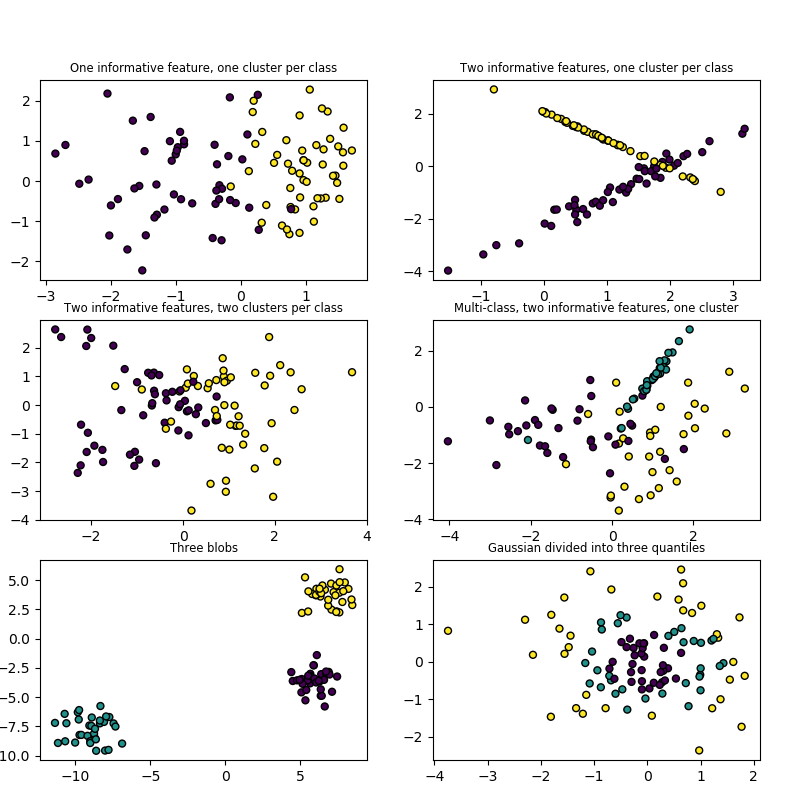
生成随机的n类分类问题。
最初,这将创建一个边长为2 * class_sep的正态分布(std=1)在n_informative维超立方体的顶点周围的点的聚类,并为每个类分配相等数量的聚类。它引入了这些功能之间的相互依赖性,并为数据增加了各种类型的进一步噪声。
在不进行shuffle的情况下,X按以下顺序水平堆叠特征:主要的n_informative特征,然后是n_redundant线性的信息特征组合,然后是n_repeated副本,从信息和冗余特征中随机替换。其余功能充满了随机噪声。因此,没有shuffle时,所有有用的功能都包含在列X [:,:n_informative + n_redundant + n_repeated]中。
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| n_samples | int, optional (default=100) 样本数。 |
| n_features | int, optional (default=20) 功能总数。这些包括随机绘制的n_informative信息特征,n_redundant冗余特征,n_repeated重复特征和n_features-n_informative-n_redundant-n_repeated无用特征。 |
| n_informative | int, optional (default=2) 信息特征的数量。每个类都由多个高斯簇组成,每个簇围绕着超立方体的顶点位于n_informative维子空间中。对于每个聚类,独立于N(0,1)绘制信息特征,然后在每个聚类内随机线性组合以增加协方差。 然后将簇放置在超立方体的顶点上。 |
| n_redundant | int, optional (default=2) 冗余特征的数量。 这些特征是作为信息特征的随机线性组合生成的。 |
| n_repeated | int, optional (default=0) 从信息性和冗余性特征中随机抽取的重复性特征的数量。 |
| n_classes | int, optional (default=2) 分类问题的类(或标签)数。 |
| n_clusters_per_class | int, optional (default=2) 每个类的簇数。 |
| weights | array-like of shape (n_classes,) or (n_classes - 1,), (default=None) 分配给每个类别的样本比例。 如果为None,则类是平衡的。 请注意,如果len(weights)== n_classes-1,则自动推断最后一个类的权重。如果weights之和超过1,则可能返回多于n_samples个样本。 |
| flip_y | float, optional (default=0.01) 类别随机分配的样本比例。 较大的值会在标签中引入噪音,并使分类任务更加困难。 请注意,在某些情况下,默认设置flip_y> 0可能导致y中的类少于n_class。 |
| class_sep | float, optional (default=1.0) 超立方体大小乘以的因子。 较大的值分散了群集/类,并使分类任务更加容易。 |
| hypercube | boolean, optional (default=True) 如果为True,则将簇放置在超立方体的顶点上。 如果为False,则将簇放置在随机多面体的顶点上。 |
| shift | float, array of shape [n_features] or None, optional (default=0.0) 按指定值移动特征。 如果为None,则将特征移动[-class_sep,class_sep]中绘制的随机值。 |
| scale | float, array of shape [n_features] or None, optional (default=1.0) 将特征乘以指定值。如果为None,则将按[1,100]中绘制的随机值缩放要素。请注意,缩放发生在移位之后。 |
| shuffle | shuboolean, optional (default=True) shuffle样本和特征。 |
| random_state | int, RandomState instance, default=None 确定用于生成数据集的随机数生成。 为多个函数调用传递可重复输出的int值。 请参阅词汇表。 |
| 返回值 | 说明 |
|---|---|
| X | array of shape [n_samples, n_features] 生成的样本。 |
| y | array of shape [n_samples] 每个样本的类成员的整数标签。 |
另见
简化变体
make_multilabel_classification
多标签任务的无关生成器
注
该算法改编自Guyon [1],旨在生成“ Madelon”数据集。
参考
I. Guyon, “Design of experiments for the NIPS 2003 variable selection benchmark”, 2003.