

scikit-learn 0.23中的发布要点¶
我们很高兴地宣布, 发布了 scikit-learn 0.23!许多bug被修复及改进,以及一些新的关键特性。我们将在下面详细介绍这个版本的几个主要特性。有关所有更改的详尽清单,请参阅发布说明。
若要安装最新版本(使用pip),请执行以下操作:
pip install --upgrade scikit-learn
或者使用conda
conda install scikit-learn
1.1.1 广义线性模型和梯度提升的泊松损失
等待已久的具有非正常损失函数的广义线性模型现在可用了.特别是,实现了三个新的回归器:PoissonRegressor、 GammaRegressor和TweedieRegressor。泊松回归(Poisson regressor )可以用来模拟正整数计数或相对频率。在用户指南中阅读更多内容。此外,HistGradientBoostingRegressor也支持一个新的‘泊松’损失( ‘poisson’ loss)。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import PoissonRegressor
from sklearn.experimental import enable_hist_gradient_boosting # noqa
from sklearn.ensemble import HistGradientBoostingRegressor
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X = rng.randn(n_samples, n_features)
# positive integer target correlated with X[:, 5] with many zeros:
y = rng.poisson(lam=np.exp(X[:, 5]) / 2)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=rng)
glm = PoissonRegressor()
gbdt = HistGradientBoostingRegressor(loss='poisson', learning_rate=.01)
glm.fit(X_train, y_train)
gbdt.fit(X_train, y_train)
print(glm.score(X_test, y_test))
print(gbdt.score(X_test, y_test))
# 输出
0.35776189065725783
0.42425183539869415
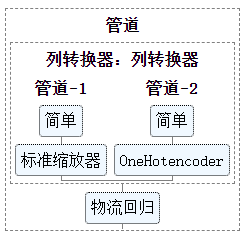
1.1.2 估计器的丰富视觉呈现
现在,通过启用display='diagram'选项,可以在笔记本中可视化估计器。这特别有助于总结管道(pipelines)和其他复合估计器的结构,并具有交互性以提供详细信息。单击下面的示例图像以展开管道元素。有关如何使用此功能,请参见可视化组合估计器。
from sklearn import set_config
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import make_column_transformer
from sklearn.linear_model import LogisticRegression
set_config(display='diagram')
num_proc = make_pipeline(SimpleImputer(strategy='median'), StandardScaler())
cat_proc = make_pipeline(
SimpleImputer(strategy='constant', fill_value='missing'),
OneHotEncoder(handle_unknown='ignore'))
preprocessor = make_column_transformer((num_proc, ('feat1', 'feat3')),
(cat_proc, ('feat0', 'feat2')))
clf = make_pipeline(preprocessor, LogisticRegression())
clf
1.1.3 对KMeans的可扩展性和稳定性的改进
KMeans估计器是完全重新写的,现在它更快,更稳定。此外,Elkan算法现在与稀疏矩阵兼容。估计器使用的是基于OpenMP的并行性,而不是依赖于jowb,因此 n_jobs 参数不再起作用。有关如何控制线程数量的详细信息,请参阅我们的并行性说明。
import scipy
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import completeness_score
rng = np.random.RandomState(0)
X, y = make_blobs(random_state=rng)
X = scipy.sparse.csr_matrix(X)
X_train, X_test, _, y_test = train_test_split(X, y, random_state=rng)
kmeans = KMeans(algorithm='elkan').fit(X_train)
print(completeness_score(kmeans.predict(X_test), y_test))
# 输出
0.7571304089239168
1.1.4 基于直方图的梯度提升估计器的改进
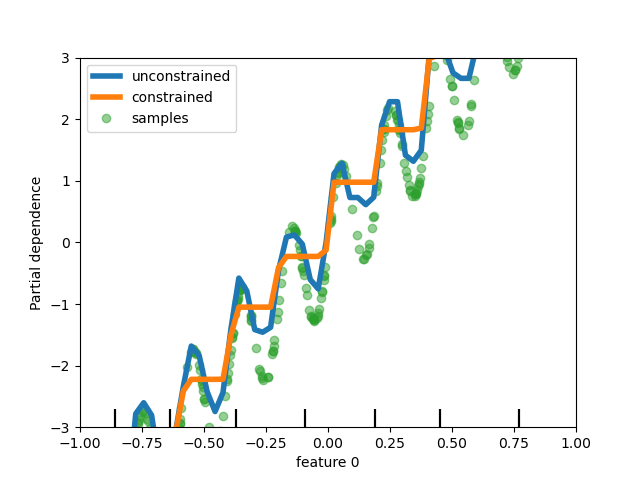
对HistGradientBoostingClassifier 和 HistGradientBoostingRegressor。作了不同的改进。在上述泊松损失的基础上,这些估计器现在支持样本权重。此外,还添加了一个自动早期停止标准:当样本数超过10k时,默认情况下启用早期停止。最后,用户现在可以定义单调约束来根据特定特征的变化来约束预测。在下面的例子中,我们构造了一个通常与第一个特征正相关的目标,其中含有一些噪声。应用单目标约束条件,预测可以捕捉第一个特征的全局效应,而不是对噪声进行拟合。
1.1.5 Lasso和ElasticNet支持样本权重
两个线性回归器Lasso 和 ElasticNet现在支持样本权重。
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression
from sklearn.linear_model import Lasso
import numpy as np
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X, y = make_regression(n_samples, n_features, random_state=rng)
sample_weight = rng.rand(n_samples)
X_train, X_test, y_train, y_test, sw_train, sw_test = train_test_split(
X, y, sample_weight, random_state=rng)
reg = Lasso()
reg.fit(X_train, y_train, sample_weight=sw_train)
print(reg.score(X_test, y_test, sw_test))
# 输出
0.999791942438998
脚本的总运行时间:(0分1.299秒)

