sklearn.datasets.load_digits¶
sklearn.datasets.load_digits(*, n_class=10, return_X_y=False, as_frame=False)
加载并返回数字数据集(分类)。
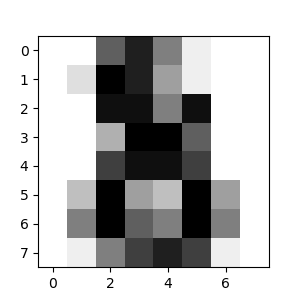
每个数据点都是一个8x8的数字图像。
| 类 | 10 |
|---|---|
| 每类的样本数 | ~180 |
| 样本总数 | 1797 |
| 维度 | 64 |
| 特征 | integers 0-16 |
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| n_class | integer, between 0 and 10, optional (default=10) 返回的类数。 |
| return_X_y | bool, default=False. 如果为True,则返回(data, target)而不是Bunch对象。 有关data和target对象的更多信息,请参见下文。 版本0.18中的新功能。 |
| as_frame | bool, default=False 如果为True,则数据为pandas DataFrame,其中包含具有适当dtypes(numeric)的列。 根据目标列的数量,目标是pandas DataFrame或Series。 如果return_X_y为True,则(data,target)将是pandas DataFrame或Series,如下所述。 0.23版中的新功能。 |
| 返回值 | 说明 |
|---|---|
| data | Bunch类字典对象,具有以下属性。 - data{ndarray, dataframe} of shape (1797, 64) 展平的数据矩阵。 如果as_frame = True,则数据将为pandas DataFrame。 - target: {ndarray, Series} of shape (1797,) 分类目标。 如果as_frame = True,target将是pandas系列。 - feature_names: list 数据集列的名称。 - target_names: list 目标类的名称。 0.20版中的新功能。 - frame: DataFrame of shape (1797, 65) 仅在as_frame = True时存在。 具有data和target的DataFrame。 0.23版中的新功能。 - images: {ndarray} of shape (1797, 8, 8) 原始图像数据。 - DESCR: str 数据集的完整描述。 |
| (data, target) | tuple if return_X_y is True版本0.18中的新功能。 |
这是UCI ML手写数字数据集测试集的副本
https://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
示例
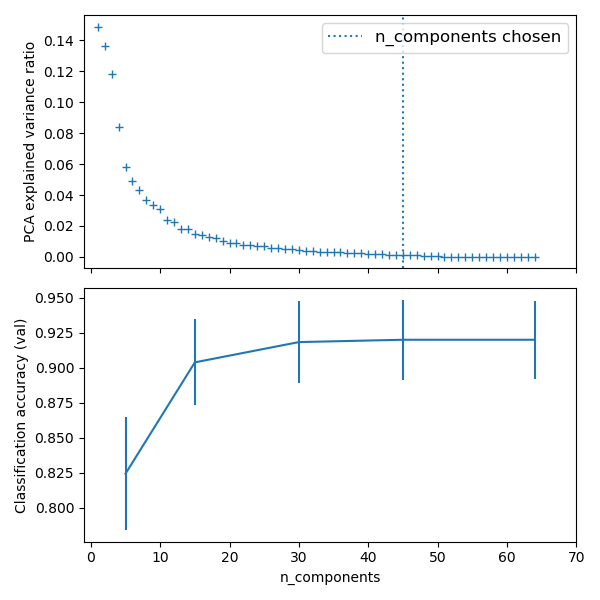
加载数据并可视化图像:
>>> from sklearn.datasets import load_digits
>>> digits = load_digits()
>>> print(digits.data.shape)
(1797, 64)
>>> import matplotlib.pyplot as plt
>>> plt.gray()
>>> plt.matshow(digits.images[0])
>>> plt.show()