

绘制验证曲线¶
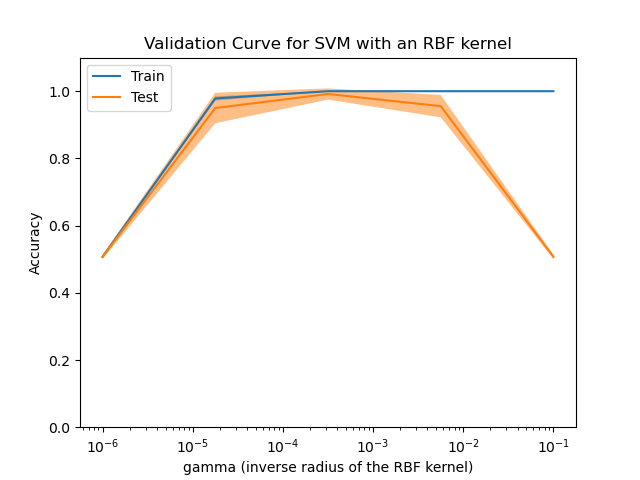
在此图中,你可以看到针对核参数gamma的不同值的SVM的训练得分和验证得分。 你可以看到,对于非常低的gamma值,训练分数和验证分数都较低,这被称为欠拟合。中等的伽玛值将导致两个得分都较高,即分类器的效果相当好。如果伽玛值太高,则分类器将过拟合,这意味着训练得分不错,但验证得分很差。
输入:
print(__doc__)
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
X, y = load_digits(return_X_y=True)
param_range = np.logspace(-6, -1, 5)
train_scores, test_scores = validation_curve(
SVC(), X, y, param_name="gamma", param_range=param_range,
scoring="accuracy", n_jobs=1)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.title("Validation Curve with SVM")
plt.xlabel(r"$\gamma$")
plt.ylabel("Score")
plt.ylim(0.0, 1.1)
lw = 2
plt.semilogx(param_range, train_scores_mean, label="Training score",
color="darkorange", lw=lw)
plt.fill_between(param_range, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.2,
color="darkorange", lw=lw)
plt.semilogx(param_range, test_scores_mean, label="Cross-validation score",
color="navy", lw=lw)
plt.fill_between(param_range, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.2,
color="navy", lw=lw)
plt.legend(loc="best")
plt.show()
脚本的总运行时间:0分钟16.011秒

