

平衡模型的复杂性和交叉验证的分数¶
本案例通过在最佳准确性得分的1个标准偏差内找到适当的准确性,同时使PCA组件的数量最小化来平衡模型的复杂性和交叉验证的得分[1]。
该图显示了交叉验证得分和PCA组件数量之间的权衡。 平衡情况是n_components = 10且精度= 0.88,该范围落在最佳精度得分的1个标准偏差之内。
[1] Hastie, T., Tibshirani, R.,, Friedman, J. (2001). Model Assessment and Selection. The Elements of Statistical Learning (pp. 219-260). New York, NY, USA: Springer New York Inc..
输出:
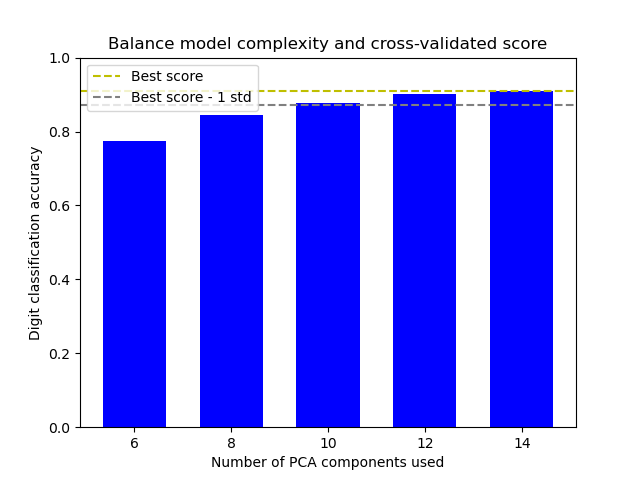
The best_index_ is 2
The n_components selected is 10
The corresponding accuracy score is 0.88
输入:
# 作者: Wenhao Zhang <wenhaoz@ucla.edu>
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.svm import LinearSVC
def lower_bound(cv_results):
"""
计算最佳mean_test_scores的1个标准偏差内的下限。
参数
----------
cv_results : 掩码多维数组组成的字典
同时查看GridSearchCV的属性cv_results_
返回
-------
浮点数
最佳mean_test_scores的1个标准偏差内的下限。
"""
best_score_idx = np.argmax(cv_results['mean_test_score'])
return (cv_results['mean_test_score'][best_score_idx]
- cv_results['std_test_score'][best_score_idx])
def best_low_complexity(cv_results):
"""
平衡交叉验证的得分与模型的复杂性
参数
----------
cv_results : 掩码多维数组组成的字典
同时查看GridSearchCV的属性cv_results_
返回值
------
整数值
PCA组件最少的模型的索引
其测试分数在bestmean_test_score的1个标准偏差之内
"""
threshold = lower_bound(cv_results)
candidate_idx = np.flatnonzero(cv_results['mean_test_score'] >= threshold)
best_idx = candidate_idx[cv_results['param_reduce_dim__n_components']
[candidate_idx].argmin()]
return best_idx
pipe = Pipeline([
('reduce_dim', PCA(random_state=42)),
('classify', LinearSVC(random_state=42, C=0.01)),
])
param_grid = {
'reduce_dim__n_components': [6, 8, 10, 12, 14]
}
grid = GridSearchCV(pipe, cv=10, n_jobs=1, param_grid=param_grid,
scoring='accuracy', refit=best_low_complexity)
X, y = load_digits(return_X_y=True)
grid.fit(X, y)
n_components = grid.cv_results_['param_reduce_dim__n_components']
test_scores = grid.cv_results_['mean_test_score']
plt.figure()
plt.bar(n_components, test_scores, width=1.3, color='b')
lower = lower_bound(grid.cv_results_)
plt.axhline(np.max(test_scores), linestyle='--', color='y',
label='Best score')
plt.axhline(lower, linestyle='--', color='.5', label='Best score - 1 std')
plt.title("Balance model complexity and cross-validated score")
plt.xlabel('Number of PCA components used')
plt.ylabel('Digit classification accuracy')
plt.xticks(n_components.tolist())
plt.ylim((0, 1.0))
plt.legend(loc='upper left')
best_index_ = grid.best_index_
print("The best_index_ is %d" % best_index_)
print("The n_components selected is %d" % n_components[best_index_])
print("The corresponding accuracy score is %.2f"
% grid.cv_results_['mean_test_score'][best_index_])
plt.show()
脚本的总运行时间:(0分钟5.453秒)

