sklearn.preprocessing.StandardScaler¶
class sklearn.preprocessing.StandardScaler(*, copy=True, with_mean=True, with_std=True)
通过去除均值并将其缩放为单位方差来标准化特征样本x的标准得分计算为:
z = (x - u) / s
其中u是训练样本的平均值,如果with_mean = False,则为零; s是训练样本的标准偏差,如果with_std = False,则为1。
通过计算训练集中样本的相关统计信息,对每个特征进行独立的居中和缩放。然后将平均值和标准偏差存储起来,以使用变换在以后的数据上使用。
数据集的标准化是许多机器学习估计器的普遍要求:如果各个特征看起来或多或少不像标准正态分布数据(例如均值和单位方差为0的高斯),则它们可能表现不佳。
例如,在学习算法的目标函数中使用的许多元素(例如支持向量机的RBF内核或线性模型的L1和L2正则化器)都假定所有特征都围绕0居中并且具有相同顺序的方差。如果某个特征的方差比其他特征大几个数量级,则它可能会支配目标函数并使估计器无法按预期从其他特征中正确学习。
还可以通过传递with_mean = False来将此缩放器应用于稀疏CSR或CSC矩阵,以避免破坏数据的稀疏性结构。
阅读更多内容参见用户指南。
| 参数 | 说明 |
|---|---|
| copy | boolean, optional, default True 如果为False,请尝试避免复制并改为就地缩放。不能保证总是在原地工作;例如,如果数据不是NumPy数组或scipy.sparse CSR矩阵,则可能仍会返回副本。 |
| with_mean | boolean, True by default 如果为True,则在缩放之前将数据居中。尝试使用稀疏矩阵时,这不起作用(并且会引发异常),因为将它们居中需要建立一个密集的矩阵,在通常的使用情况下,该矩阵可能太大而无法容纳在内存中。 |
| with_std | boolean, True by default 如果为True,则将数据缩放到单位方差(或等效地,单位标准偏差)。 |
| 属性 | 说明 |
|---|---|
| scale_ | ndarray or None, shape (n_features,) 每个要素的数据相对缩放。这是使用np.sqrt(var)计算的。当with_std = False时等于无。 0.17版中的新功能:scale |
| mean_ | ndarray or None, shape (n_features,) 训练集中每个特征的平均值。当with_mean = False时等于无。 |
| var_ | ndarray or None, shape (n_features,) 训练集中每个要素的方差。用于计算scale_。当with_std = False时等于无。 |
| n_samples_seen_ | int or array, shape (n_features,) 估计器为每个要素处理的样本数。如果不缺少样本,则n_samples_seen将为整数,否则将为数组。将在新的调用中重置为fit,但在partial_fit调用中递增。 |
另见:
没有估算器API的等效函数。
进一步删除带有'whiten = True'的特征之间的线性相关性。
注释
NaN被视为缺失值:忽略适合度,并保持变换值。
对于标准偏差,我们使用偏差估算器,它等于numpy.std(x,ddof = 0)。请注意,选择ddof不太可能影响模型性能。
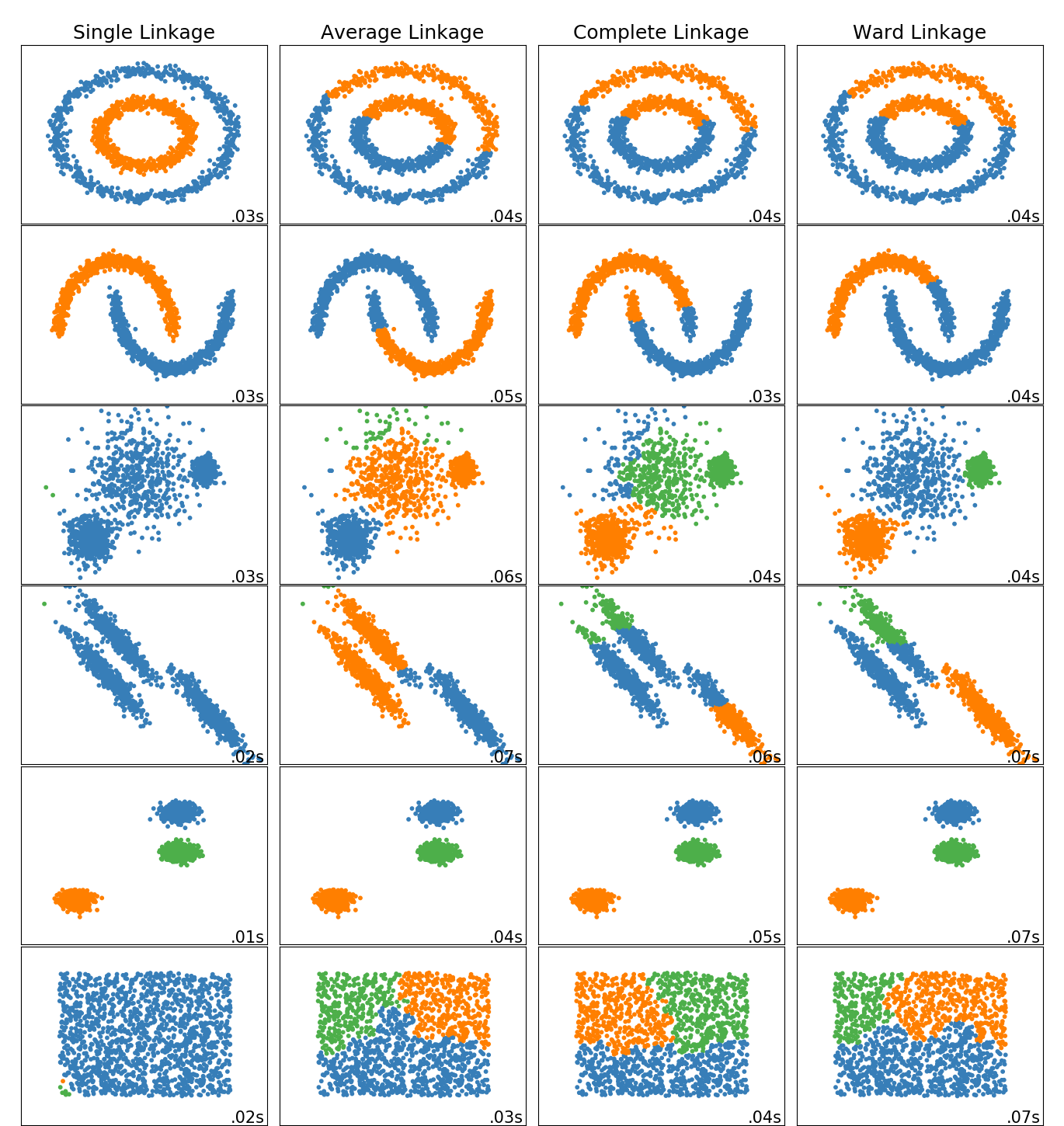
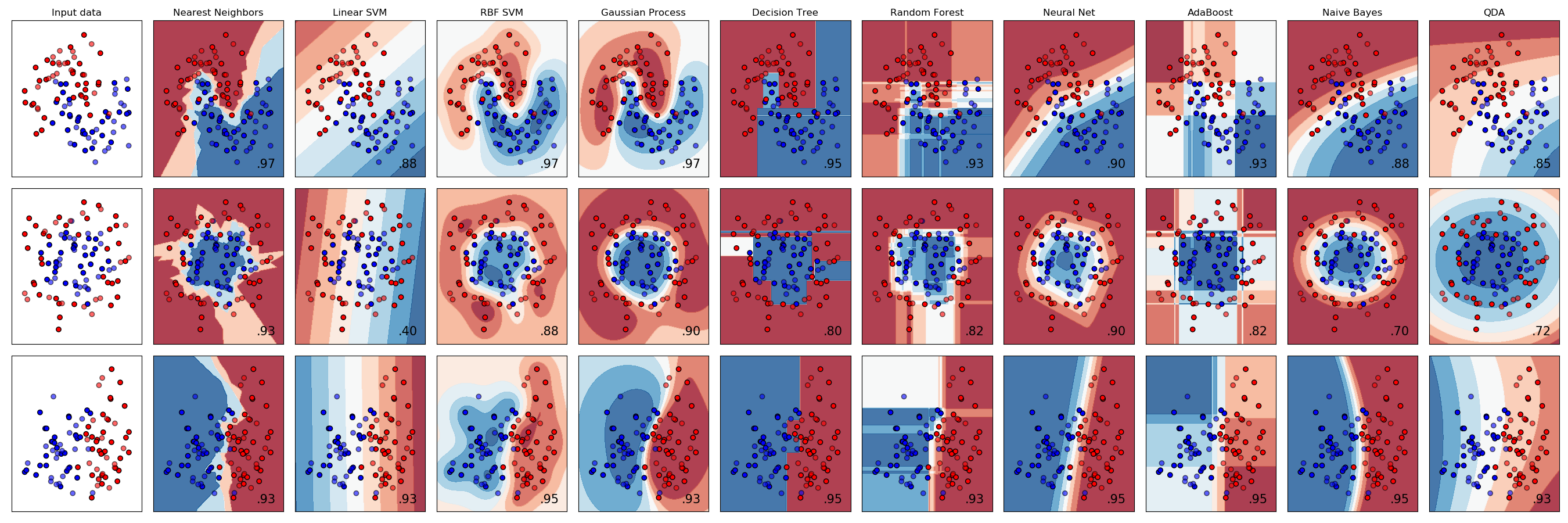
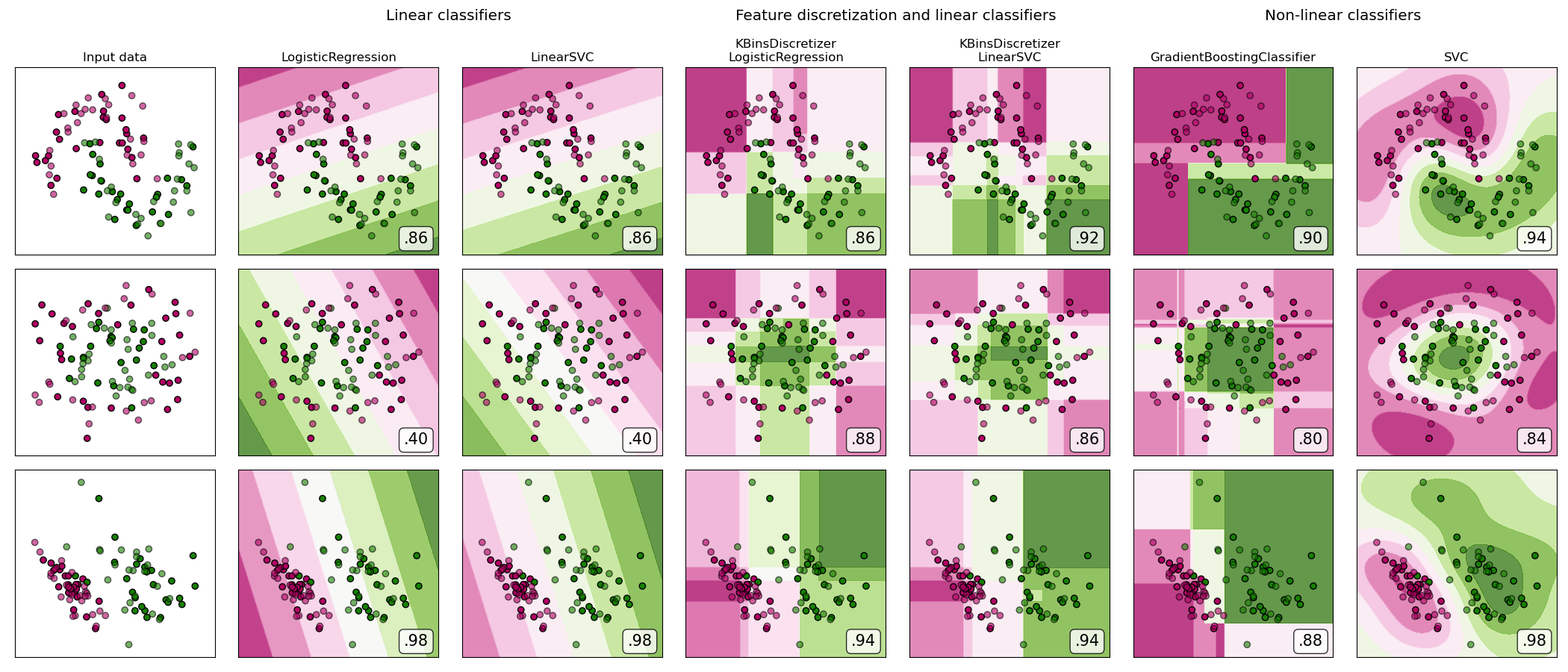
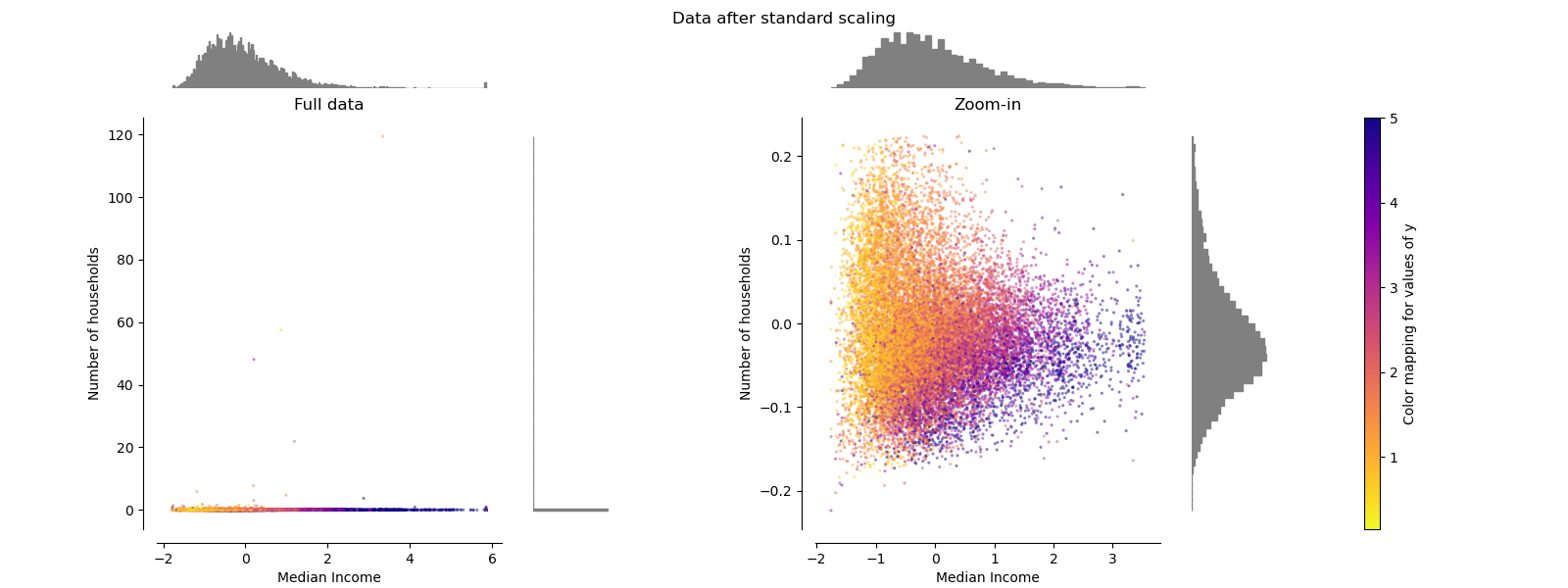
有关不同缩放器,转换器和规范化器的比较,请参阅examples/preprocessing/plot_all_scaling.py。
示例
>>> from sklearn.preprocessing import StandardScaler
>>> data = [[0, 0], [0, 0], [1, 1], [1, 1]]
>>> scaler = StandardScaler()
>>> print(scaler.fit(data))
StandardScaler()
>>> print(scaler.mean_)
[0.5 0.5]
>>> print(scaler.transform(data))
[[-1. -1.]
[-1. -1.]
[ 1. 1.]
[ 1. 1.]]
>>> print(scaler.transform([[2, 2]]))
[[3. 3.]]
方法
| 方法 | 说明 |
|---|---|
fit(X[, y]) |
计算平均值和标准差,以用于以后的标度。 |
fit_transform(X[, y]) |
拟合数据,然后对其进行转换。 |
get_params([deep]) |
获取此估计量的参数。 |
inverse_transform(X[, copy]) |
将数据按比例缩小到原始表示形式 |
partial_fit(X[, y]) |
在线计算X上的均值和标准差,以便以后缩放。 |
set_params(**params) |
设置此估算器的参数。 |
transform(X[, copy]) |
通过居中和缩放执行标准化 |
__init__(*, copy=True, with_mean=True, with_std=True)
始化self,有关准确的签名,请参见help(type(self))。
fit(X, y=None)
计算均值和标准差以用于以后的缩放。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix}, shape [n_samples, n_features] 用于计算平均值和标准偏差的数据,这些平均值和标准偏差用于以后沿特征轴缩放。 |
| y | None 忽略。 |
fit_transform(X, y=None, **fit_params)
拟合数据,然后对其进行转换。
使用可选参数fit_params将转换器拟合到X和y,并返回X的转换版本。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix, dataframe} of shape (n_samples, n_features) |
| y | ndarray of shape (n_samples,), default=None 目标值。 |
| **fit_params | dict 其他拟合参数。 |
| 返回值 | 说明 |
|---|---|
| X_new | ndarray array of shape (n_samples, n_features_new) 转换后的数组。 |
get_params(deep=True)
获取此估计量的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估算器和作为估算器的所包含子对象的参数。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名称映射到其值。 |
inverse_transform(X, copy=None)
将数据按比例缩小到原始表示形式
| 参数 | 说明 |
|---|---|
| X | array-like, shape [n_samples, n_features] 用于沿要素轴缩放的数据。 |
| copy | bool, optional (default: None) 是否复制输入X。 |
| 返回值 | 说明 |
|---|---|
| X_tr | array-like, shape [n_samples, n_features] 转换后的数组。 |
partial_fit(X, y=None)
在线计算X上的均值和标准差,以便以后缩放。
所有X都作为一个批处理。这适用于由于n_sample数量过多或从连续流中读取X而无法进行拟合的情况。
Chan,Tony F.,Gene H.Golub和Randall J.LeVeque的公式1.5a,b中给出了增量均值和std的算法。“计算样本方差的算法:分析和建议。”美国统计学家37.3(1983):242-247:
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix}, shape [n_samples, n_features] 用于计算平均值和标准偏差的数据,这些平均值和标准偏差用于以后沿特征轴缩放。 |
| y | None 忽略。 |
| 返回值 | 说明 |
|---|---|
| self | object 变压器实例。 |
set_params(**params)
设置此估算器的参数。
该方法适用于简单的估计器以及嵌套对象(例如管道)。后者的参数形式为<component>__<parameter>这样就可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估算器参数。 |
| 返回值 | 说明 |
|---|---|
| self | object 估算器实例。 |
transform(X, copy=None)
通过居中和缩放执行标准化
| 参数 | 说明 |
|---|---|
| X | array-like, shape [n_samples, n_features] 用于沿要素轴缩放的数据。 |
| 返回值 | 说明 |
|---|---|
| X_out | bool, optional (default: None) 是否复制输入X。 |