sklearn.feature_selection.f_regression¶
sklearn.feature_selection.f_regression(X, y, *, center=True)
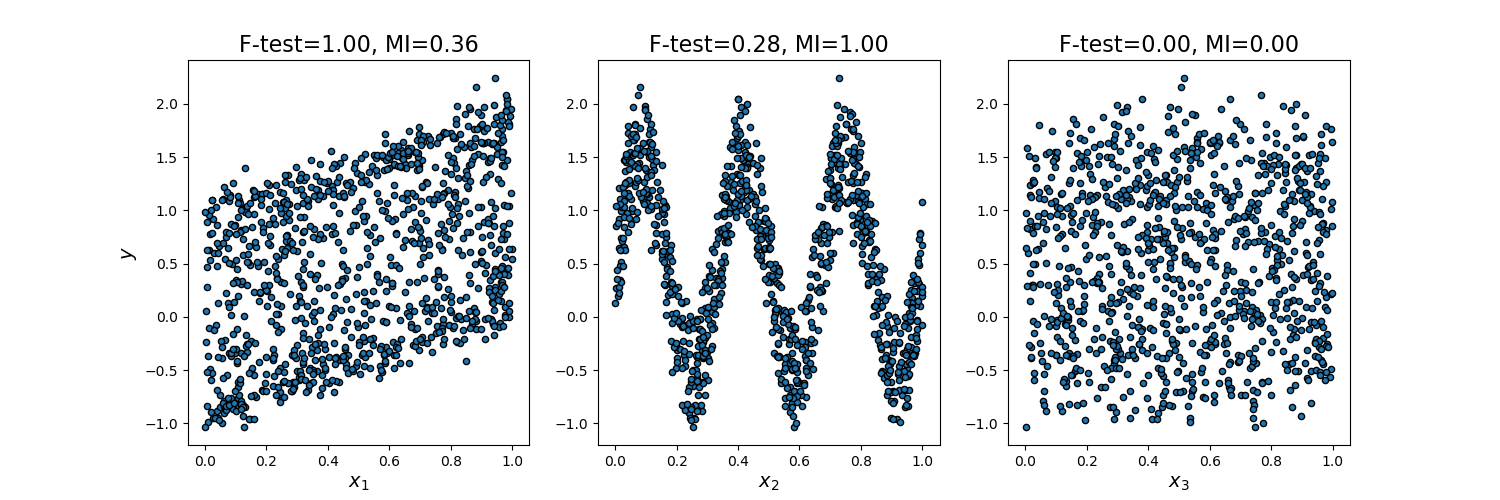
单变量线性回归测试。
一种线性模型,用于测试多个回归因子中每一个的单独效果。这是用于特征选择程序的评分函数,而不是独立的特征选择程序。
分两个步骤完成:
计算每个回归变量与目标之间的相关性,即(((X [:, i]-mean(X [:, i]))(y-mean_y))/(std(X [:, i] ) std(y))。 将其转换为F分数,然后转换为p值。
有关使用的更多信息,请参见用户指南。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} shape = (n_samples, n_features) 将依次测试的一组回归变量集合。 |
| y | array of shape(n_samples). 数据矩阵。 |
| center | True, bool, 如果为true,则X和y将居中。 |
| 返回值 | 说明 |
|---|---|
| F | array, shape=(n_features,) 特征的F值。 |
| pval | array, shape=(n_features,) F得分的p值。 |
另见
共同目标的共同信息。
标签与特征之间的ANOVA F值,用于分类任务。
分类任务的非负特征的卡方统计。
根据k个最高分数选择特征。
根据误报率测试选择特征。
根据估计的错误发现率选择特征。
根据多重比较错误率选择特征。
根据最高分数的百分位数选择特征。