sklearn.decomposition.PCA¶
class sklearn.decomposition.PCA(n_components=None, *, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)
主成分分析(PCA)。
利用数据的奇异值分解将其投射到较低维空间的线性降维。在应用SVD之前,输入数据是居中的,但没有针对每个特征进行缩放。
根据输入数据的形状和提取的分量的数量,它使用LAPACK实现的完整SVD或随机截断的SVD Halko et al. 2009的方法。
它也可以使用scipy.sparse。linalg ARPACK的截断SVD实现。
请注意,这个类不支持稀疏输入。请参阅TruncatedSVD了解稀疏数据的替代方法。
在用户指南中阅读更多内容
| 参数 | 说明 |
|---|---|
| n_components | int, float, None or str 要保存的样本数量。如果没有设置n_components,则保留所有样本: n_components == min(n_samples, n_features) 如果 n_components == 'mle' and svd_solver == 'full', 则使用Minka’s MLE 来猜测维数. 使用n_components == 'mle' 讲把 svd_solver == 'auto' 解释为 svd_solver == 'full'.如果 0 < n_components < 1 and svd_solver == 'full', 则选择样本的数量,以便需要解释的方差量大于n_components指定的百分比。如果 svd_solver == 'arpack', 则组件的数量必须严格小于n_features和n_samples的最小值。因此,None case的结果是: n_components == min(n_samples, n_features) - 1 |
| copy | bool, default=True 如果为False,传递给fit的数据将被覆盖,运行fit(X).transform(X)将不会产生预期的结果,使用fit_transform(X)代替。 |
| whiten | bool, optional (default False) 当为真(默认为假)时,components_向量乘以n_samples的平方根,然后除以奇异值,以确保输出与单位分量方差不相关。 白化将从转换信号中去除一些信息(组件的相对方差尺度),但有时可以通过使下游估计器的数据尊重一些硬连接的假设来提高其预测精度。 |
| svd_solver | str {‘auto’, ‘full’, ‘arpack’, ‘randomized’} If auto : 根据基于X的默认策略选择求解器。shape和n_components:如果输入数据大于500x500,并且要提取的组件数量小于数据最小维数的80%,那么就启用了更有效的“随机化”方法。否则,精确的完整SVD将被计算,然后选择性地截断。 If full : 通过scipy.linalg调用标准的LAPACK求解器运行精确的全SVD。svd和选择组件的后处理 If arpack : 通过sci . sparsee .linalg.svds调用ARPACK求解器来运行截断为n_components的SVD。它严格要求0 < n_components < min(X.shape) If randomized : 使用Halko等的方法进行随机化SVD。 |
| tol | float >= 0, optional (default .0) svd_solver == ' arpack '计算的奇异值的容忍度。 新版本0.18.0。 |
| iterated_power | int >= 0, or ‘auto’, (default ‘auto’) svd_solver计算的幂次法的迭代次数== ' random '。 新版本0.18.0。 |
| random_state | int, RandomState instance, default=None 当 svd_solver == ' arpack '或' randomver '时使用。在多个函数调用中传递可重复的结果。详见术语表。新版本0.18.0。 |
| 属性 | 说明 |
|---|---|
| components_ | array, shape (n_components, n_features) 特征空间的主轴,表示数据中方差最大的方向。样本按 explained_variance_排序。 |
| explained_variance_ | array, shape (n_components,) 所选择的每个分量所解释的方差量。 等于X的协方差矩阵的n个最大特征值。 新版本0.18。 |
| explained_variance_ratio_ | array, shape (n_components,) 所选择的每个组成部分所解释的方差百分比。 如果没有设置 n_components,那么将存储所有组件,并且比率的总和等于1.0。 |
| singular_values_ | array, shape (n_components,) 对应于每个选定分量的奇异值。奇异值等于低维空间中 n_component变量的2-范数。新版本为0.19。 |
| mean_ | array, shape (n_features,) 每个特征的经验平均数,从训练集估计。 等于 X.mean(axis=0). |
| n_components_ | int 估计的组件数量。当n_components设置为' mle '或0到1之间的数字(with svd_solver == ‘full’)时,该数字是从输入数据估计的。否则等于参数 n_components,或者如果n_components为None,则等于n_features和n_samples的较小值。 |
| n_features_ | int 训练数据中的特征数。 |
| n_samples_ | int 训练数据中的样本数。 |
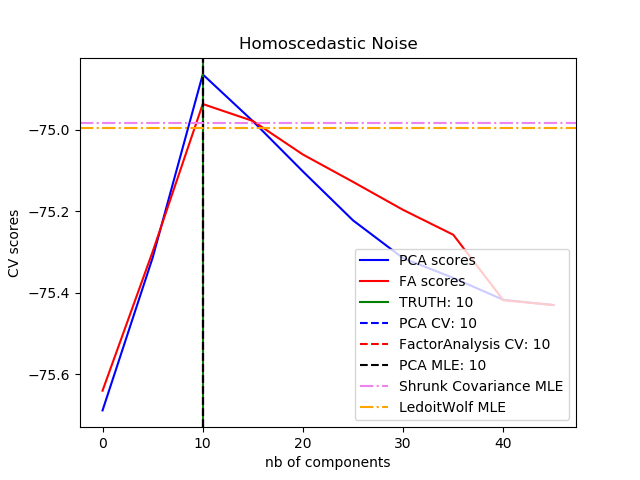
| noise_variance_ | float 根据Tipping和Bishop 1999年的概率PCA模型估计的噪声协方差。参见C. Bishop的“模式识别和机器学习”,12.2.1页,574或http://www.miketipping.com/papers/met-mppca.pdf。需要计算估计数据协方差和样本评分。 等于X的协方差矩阵的最小特征值 (min(n_features, n_samples) - n_components)的平均值。 |
另见:
Kernel Principal Component Analysis.
Sparse Principal Component Analysis.
Dimensionality reduction using truncated SVD.
Incremental Principal Component Analysis.
参考资料:
For n_components == ‘mle’, this class uses the method of Minka, T. P. “Automatic choice of dimensionality for PCA”. In NIPS, pp. 598-604
Implements the probabilistic PCA model from: Tipping, M. E., and Bishop, C. M. (1999). “Probabilistic principal component analysis”. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61(3), 611-622. via the score and score_samples methods. See http://www.miketipping.com/papers/met-mppca.pdf
For svd_solver == ‘arpack’, refer to scipy.sparse.linalg.svds.
For svd_solver == ‘randomized’, see: Halko, N., Martinsson, P. G., and Tropp, J. A. (2011). “Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions”. SIAM review, 53(2), 217-288. and also Martinsson, P. G., Rokhlin, V., and Tygert, M. (2011). “A randomized algorithm for the decomposition of matrices”. Applied and Computational Harmonic Analysis, 30(1), 47-68.
>>> import numpy as np
>>> from sklearn.decomposition import PCA
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> pca = PCA(n_components=2)
>>> pca.fit(X)
PCA(n_components=2)
>>> print(pca.explained_variance_ratio_)
[0.9924... 0.0075...]
>>> print(pca.singular_values_)
[6.30061... 0.54980...]
>>>
>>> pca = PCA(n_components=2, svd_solver='full')
>>> pca.fit(X)
PCA(n_components=2, svd_solver='full')
>>> print(pca.explained_variance_ratio_)
[0.9924... 0.00755...]
>>> print(pca.singular_values_)
[6.30061... 0.54980...]
>>>
>>> pca = PCA(n_components=1, svd_solver='arpack')
>>> pca.fit(X)
PCA(n_components=1, svd_solver='arpack')
>>> print(pca.explained_variance_ratio_)
[0.99244...]
>>> print(pca.singular_values_)
[6.30061...]
方法
| 方法 | 说明 |
|---|---|
fit(X[, y]) |
用X拟合模型。 |
fit_transform(X[, y]) |
用X拟合模型,对X进行降维。 |
get_covariance() |
用生成模型计算数据协方差。 |
get_params([deep]) |
获取这个估计器的参数。 |
get_precision() |
利用生成模型计算数据精度矩阵。 |
inverse_transform(X) |
将数据转换回其原始空间。 |
score(X[, y]) |
返回所有样本的平均对数似然值。 |
score_samples(X) |
返回每个样本的对数似然值。 |
set_params(**params) |
设置这个估计器的参数。 |
transform(X) |
对X应用维数约简。 |
__init__(n_components=None, *, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None)
初始化self. See 请参阅help(type(self))以获得准确的说明。
fit(X, y=None)
用X拟合模型,对X进行降维。
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 训练向量,其中样本数量中的n_samples和n_features为feature的数量。 |
| y | Ignored |
| 返回值 | 说明 |
|---|---|
| X_new | ndarray array of shape (n_samples, n_features_new) 转换的数组 |
注意:
此方法返回一个按fortran顺序排列的数组。要将其转换为c顺序数组,请使用“np. ascontinuity array”。
get_covariance()
用生成模型计算数据协方差。
cov = components_.T * S**2 * components_ + sigma2 * eye(n_features) S**2包含被解释的方差,sigma2包含噪声方差。
| 返回值 | 说明 |
|---|---|
| cov | array, shape=(n_features, n_features) 数据的估计协方差。 |
get_params(deep=True)
利用生成模型计算数据精度矩阵。
等于协方差的逆,但为了效率,用矩阵逆引理计算。
| 返回值 | 说明 |
|---|---|
| precision | **array, shape=(n_features, n_features)**** 数据的估计精度。 |
inverse_transform(X)
将数据转换回其原始空间。
换句话说,返回一个转换为X的输入X_original。
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_components) 新数据,其中n_samples是样本的数量,n_components是组件的数量。 |
| 返回值 | 说明 |
|---|---|
| X_original array-like, shape (n_samples, n_features) | 略 |
注意:
如果启用了白化,inverse_transform将计算精确的反运算,其中包括反向白化。
score(X, y=None)
返回所有样本的平均对数似然值。
另见:
“Pattern Recognition and Machine Learning” by C. Bishop, 12.2.1 p. 574 or http://www.miketipping.com/papers/met-mppca.pdf
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 数据 |
| y | None 忽略的变量。 |
| 返回值 | 说明书 |
|---|---|
| II | float 样本在当前模型下的对数似然平均数。 |
score_samples(X)
返回每个样本的对数似然值。
另见:
“Pattern Recognition and Machine Learning” by C. Bishop, 12.2.1 p. 574 or http://www.miketipping.com/papers/met-mppca.pdf
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 数据 |
| 返回值 | 说明书 |
|---|---|
| II | array, shape (n_samples,) 样本在当前模型下的对数似然平均数。 |
set_params(**params)
设置这个估计器的参数。
该方法适用于简单估计量和嵌套对象。后者具有形式为<component>_<parameter>的参数,这样就让更新嵌套对象的每个组件成为了可能。
| 参数 | 说明 |
|---|---|
| **params | dict 估计器参数。 |
| 返回值 | 说明书 |
|---|---|
| self | object 估计器参数。 |
transform(X)
对X应用维数约简。
X被投影到之前从训练集中提取的第一个主成分上。
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 新数据,其中n_samples为样本数量,n_features为特征数量。 |
| 返回值 | 说明书 |
|---|---|
| X_new | array-like, shape (n_samples, n_components) |
示例:
>>> import numpy as np
>>> from sklearn.decomposition import IncrementalPCA
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> ipca = IncrementalPCA(n_components=2, batch_size=3)
>>> ipca.fit(X)
IncrementalPCA(batch_size=3, n_components=2)
>>> ipca.transform(X) # doctest: +SKIP