

概率校准曲线¶
在进行分类时,不仅要预测类标签,还要预测相关概率。这种概率给了预测某种程度的信心。此示例演示了如何显示预测概率的校准效果,以及如何校准未校准的分类器。
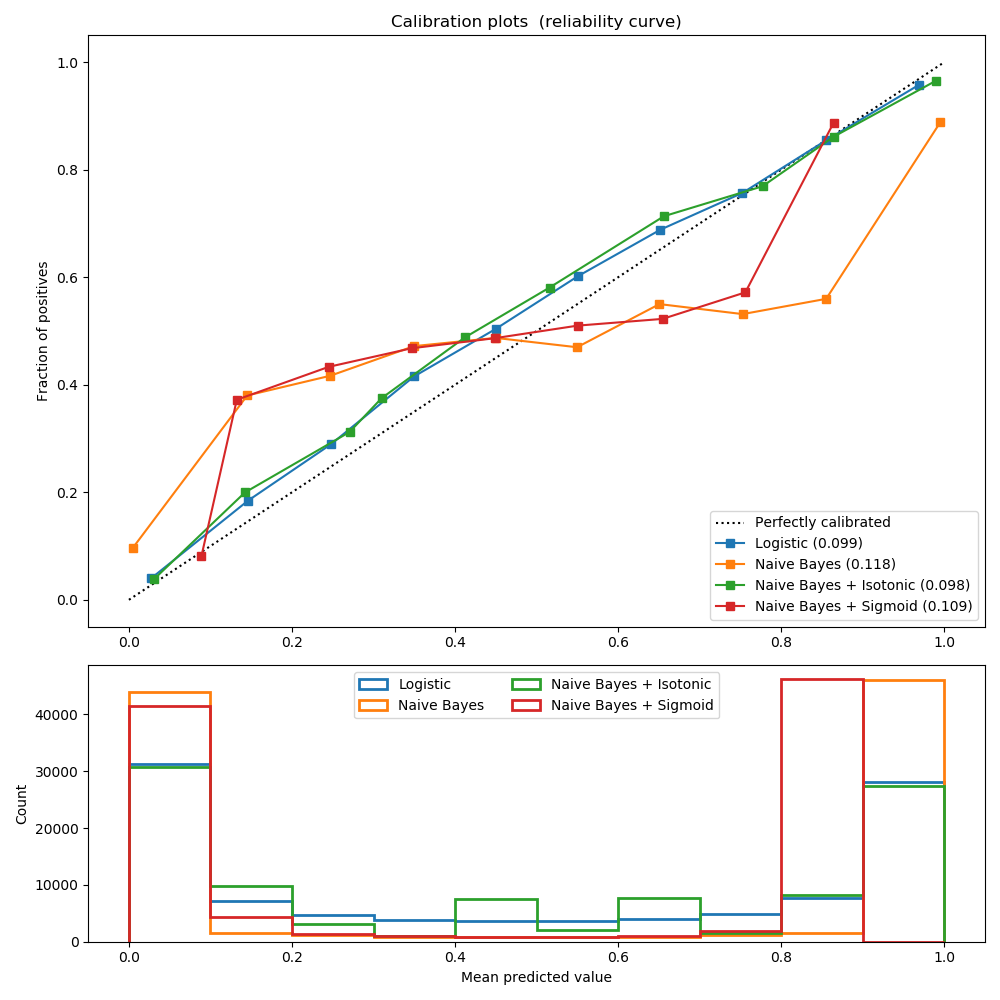
实验是在一个二分类的人工数据集上进行的,该数据集包含100000个样本(其中1000个用于模型拟合),共20个特征。在这20个特性中,只有2个是信息丰富的,10个是冗余的。第一幅图显示了通过Logistic回归、高斯朴素贝叶斯、 isotonic校准的高斯朴素贝叶斯和sigmoid校准的高斯朴素贝叶斯得到的估计概率。校准性能用Brier评分进行评估,在图例中有报道(越小越好)。这里可以看到,Logistic回归是很好的校准,而原始高斯朴素贝叶斯表现很差。这是因为冗余特征违背了特征无关的假设,导致分类器过于自信,这可以通过transposed-sigmoid曲线表明。
用 isotonic校准的高斯朴素贝叶斯的概率校准可以解决这一问题,这也可以从对角校准曲线可以看出这一点。sigmoid也略微提高了Brier评分,尽管不如非参数的isotonic回归那么强。这可以归因于这样一个事实:我们有大量的校准数据,以至于可以利用非参数模型的更大的灵活性。
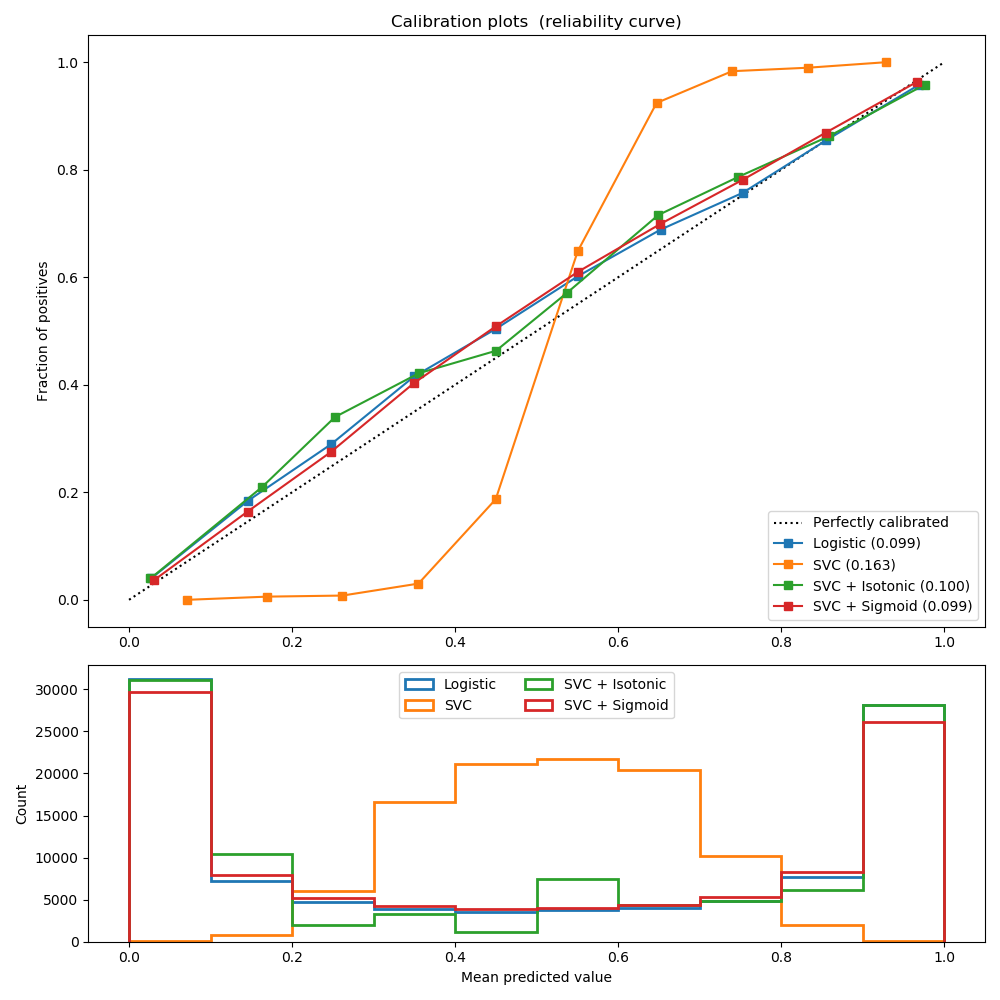
第二个图显示了线性支持向量分类器(LinearSVC)的校准曲线。LinearSVC显示了与高斯朴素贝叶斯相反的行为:校准曲线有一条sigmoid曲线,这是欠自信分类器的典型特征。在LinearSVC的情况下,这是由hinge损失的边缘特性引起的,这使得模型关注于接近决策边界的硬样本(支持向量)。
这两种校准方法都可以解决这个问题,并得到几乎相同的结果。这表明,Sigmoid校准可以处理基本分类器的校准曲线为Sigmoid的情况(例如,LinearSVC),而不能处理transposed-sigmoid(例如,高斯朴素贝叶斯)的情况。
Logistic:
Brier: 0.099
Precision: 0.872
Recall: 0.851
F1: 0.862
Naive Bayes:
Brier: 0.118
Precision: 0.857
Recall: 0.876
F1: 0.867
Naive Bayes + Isotonic:
Brier: 0.098
Precision: 0.883
Recall: 0.836
F1: 0.859
Naive Bayes + Sigmoid:
Brier: 0.109
Precision: 0.861
Recall: 0.871
F1: 0.866
Logistic:
Brier: 0.099
Precision: 0.872
Recall: 0.851
F1: 0.862
SVC:
Brier: 0.163
Precision: 0.872
Recall: 0.852
F1: 0.862
SVC + Isotonic:
Brier: 0.100
Precision: 0.853
Recall: 0.878
F1: 0.865
SVC + Sigmoid:
Brier: 0.099
Precision: 0.874
Recall: 0.849
F1: 0.861
print(__doc__)
# Author: Alexandre Gramfort <alexandre.gramfort@telecom-paristech.fr>
# Jan Hendrik Metzen <jhm@informatik.uni-bremen.de>
# License: BSD Style.
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (brier_score_loss, precision_score, recall_score,
f1_score)
from sklearn.calibration import CalibratedClassifierCV, calibration_curve
from sklearn.model_selection import train_test_split
# Create dataset of classification task with many redundant and few
# informative features
X, y = datasets.make_classification(n_samples=100000, n_features=20,
n_informative=2, n_redundant=10,
random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.99,
random_state=42)
def plot_calibration_curve(est, name, fig_index):
"""Plot calibration curve for est w/o and with calibration. """
# Calibrated with isotonic calibration
isotonic = CalibratedClassifierCV(est, cv=2, method='isotonic')
# Calibrated with sigmoid calibration
sigmoid = CalibratedClassifierCV(est, cv=2, method='sigmoid')
# Logistic regression with no calibration as baseline
lr = LogisticRegression(C=1.)
fig = plt.figure(fig_index, figsize=(10, 10))
ax1 = plt.subplot2grid((3, 1), (0, 0), rowspan=2)
ax2 = plt.subplot2grid((3, 1), (2, 0))
ax1.plot([0, 1], [0, 1], "k:", label="Perfectly calibrated")
for clf, name in [(lr, 'Logistic'),
(est, name),
(isotonic, name + ' + Isotonic'),
(sigmoid, name + ' + Sigmoid')]:
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
if hasattr(clf, "predict_proba"):
prob_pos = clf.predict_proba(X_test)[:, 1]
else: # use decision function
prob_pos = clf.decision_function(X_test)
prob_pos = \
(prob_pos - prob_pos.min()) / (prob_pos.max() - prob_pos.min())
clf_score = brier_score_loss(y_test, prob_pos, pos_label=y.max())
print("%s:" % name)
print("\tBrier: %1.3f" % (clf_score))
print("\tPrecision: %1.3f" % precision_score(y_test, y_pred))
print("\tRecall: %1.3f" % recall_score(y_test, y_pred))
print("\tF1: %1.3f\n" % f1_score(y_test, y_pred))
fraction_of_positives, mean_predicted_value = \
calibration_curve(y_test, prob_pos, n_bins=10)
ax1.plot(mean_predicted_value, fraction_of_positives, "s-",
label="%s (%1.3f)" % (name, clf_score))
ax2.hist(prob_pos, range=(0, 1), bins=10, label=name,
histtype="step", lw=2)
ax1.set_ylabel("Fraction of positives")
ax1.set_ylim([-0.05, 1.05])
ax1.legend(loc="lower right")
ax1.set_title('Calibration plots (reliability curve)')
ax2.set_xlabel("Mean predicted value")
ax2.set_ylabel("Count")
ax2.legend(loc="upper center", ncol=2)
plt.tight_layout()
# Plot calibration curve for Gaussian Naive Bayes
plot_calibration_curve(GaussianNB(), "Naive Bayes", 1)
# Plot calibration curve for Linear SVC
plot_calibration_curve(LinearSVC(max_iter=10000), "SVC", 2)
plt.show()
脚本的总运行时间:(0分2.485秒)

