sklearn.linear_model.BayesianRidge¶
class sklearn.linear_model.BayesianRidge(*, n_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, alpha_init=None, lambda_init=None, compute_score=False, fit_intercept=True, normalize=False, copy_X=True, verbose=False)
贝叶斯岭回归。
拟合贝叶斯山脊模型。有关此实现以及正则化参数lambda(权重的精度)和alpha(噪声的精度)的优化的详细信息,请参见“注释”部分。
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| n_iter | int, default=300 最大迭代次数。应该大于或等于1。 |
| tol | float, default=1e-3 如果w收敛,则停止算法。 |
| alpha_1 | float, default=1e-6 超参数:高于alpha参数的Gamma分布的形状参数。 |
| alpha_2 | float, default=1e-6 超参数:优先于alpha参数的Gamma分布的反比例参数(速率参数)。 |
| lambda_1 | float, default=1e-6 超参数:高于lambda参数的Gamma分布的形状参数。 |
| lambda_2 | float, default=1e-6 超参数:优先于lambda参数的Gamma分布的反比例参数(速率参数)。 |
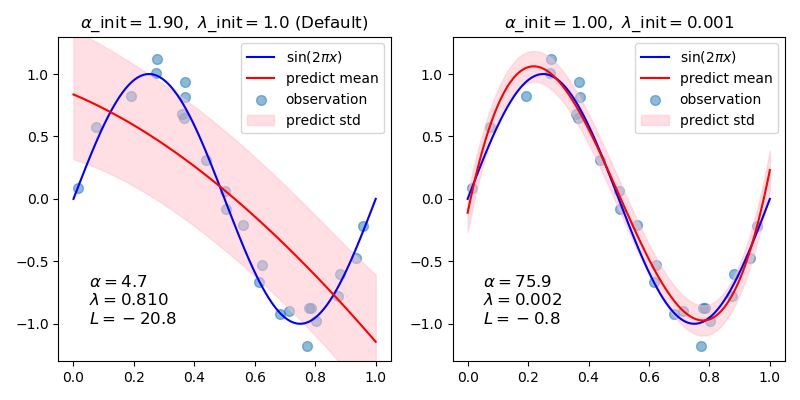
| alpha_init | float, default=None alpha的初始值(噪声的精度)。如果未设置,则alpha_init为1 / Var(y)。 0.22版中的新功能。 |
| lambda_init | float, default=None Lambda的初始值(权重的精度)。如果未设置,则lambda_init为1。 0.22版中的新功能。 |
| compute_score | bool, default=False 如果为True,则计算模型每一步的目标函数。 |
| fit_intercept | bool, default=True 是否计算该模型的截距。如果设置为false,则在计算中将不使用截距(即,数据应居中)。 |
| normalize | bool, default=Falsefit_intercept设置为False 时,将忽略此参数。如果为True,则在回归之前通过减去均值并除以l2-范数来对回归变量X进行归一化。如果你希望标准化,请先使用 sklearn.preprocessing.StandardScaler,然后调用fit 估算器并设置normalize=False。 |
| copy_X | bool, default=True 如果为True,将复制X;否则X可能会被覆盖。 |
| verbose | bool, default=False 拟合模型时的详细模式。 |
| 属性 | 说明 |
|---|---|
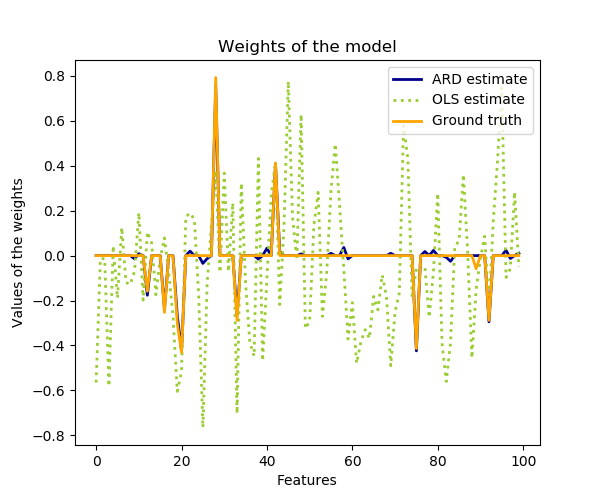
| coef_ | array-like of shape (n_features,) 回归模型的系数(分布的均值) |
| intercept_ | float 决策函数中的截距。如果 fit_intercept = False则设置为0.0 。 |
| alpha_ | float 估计的噪声精度。 |
| lambda_ | array-like of shape (n_features,) 权重的估计精度。 |
| sigma_ | array-like of shape (n_features, n_features) 权重的估计方差-协方差矩阵 |
| scores_ | array-like of shape (n_iter_+1,) 如果calculated_score为True,则在每次优化迭代时的对数边际似然值(待最大化)。该数组从alpha和lambda的初始值获得的对数边际似然值开始,以alpha和lambda的估计值获得的值结束。 |
| n_iter_ | int 达到停止标准的实际迭代次数。 |
注
进行贝叶斯岭回归有几种方法。此实现基于附录A(Tipping,2001)中描述的算法,其中正则化参数的更新按照(MacKay,1992)中的建议进行。请注意,根据自动相关性确定的新观点(Wipf和Nagarajan,2008年),这些更新规则不能保证在连续两次优化迭代之间边际似然增加。
参考
D. J. C. MacKay, Bayesian Interpolation, Computation and Neural Systems, Vol. 4, No. 3, 1992.
M. E. Tipping, Sparse Bayesian Learning and the Relevance Vector Machine, Journal of Machine Learning Research, Vol. 1, 2001.
示例
>>> from sklearn import linear_model
>>> clf = linear_model.BayesianRidge()
>>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2])
BayesianRidge()
>>> clf.predict([[1, 1]])
array([1.])
方法
| 方法 | 说明 |
|---|---|
fit(X, y[, sample_weight]) |
拟合模型。 |
get_params([deep]) |
获取此估计量的参数。 |
predict(X[, return_std]) |
使用线性模型进行预测。 |
score(X, y[, sample_weight]) |
返回预测的确定系数R ^ 2。 |
set_params(**params) |
设置此估算器的参数。 |
__init__(*, n_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, alpha_init=None, lambda_init=None, compute_score=False, fit_intercept=True, normalize=False, copy_X=True, verbose=False)
初始化self, 请参阅help(type(self))以获得准确的说明。
fit(X, y, sample_weight=None)
[源码]
拟合模型。
| 参数 | 说明 |
|---|---|
| X | ndarray of shape (n_samples, n_features) 训练数据。 |
| y | ndarray of shape (n_samples,) 目标值(整数)。如有必要,将强制转换为X的数据类型。 |
| sample_weight | ndarray of shape (n_samples,), default=None 每个样本的权重 0.20版中的新功能: BayesianRidge支持sample_weight参数。 |
| 返回值 | 说明 |
|---|---|
| self | returns an instance of self. |
get_params(deep=True)
[源码]
获取此估计量的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估算器和所包含子对象的参数。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名称映射到其值。 |
predict(X, return_std=False)
[源码]
使用线性模型进行预测。
除了预测分布的平均值外,还可以返回其标准偏差。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 样本数据 |
| return_std | bool, default=False 是否返回后验预测的标准差。 |
| 返回值 | 说明 |
|---|---|
| y_mean | array-like of shape (n_samples,) 查询点的预测分布平均值。 |
| y_std | array-like of shape (n_samples,) 查询点的预测分布的标准偏差。 |
score(X, y, sample_weight=None)
[源码]
返回预测的确定系数R ^ 2。
系数R ^ 2定义为(1- u / v),其中u是残差平方和((y_true-y_pred)** 2).sum(),而v是总平方和((y_true- y_true.mean())** 2).sum()。可能的最高得分为1.0,并且也可能为负(因为该模型可能会更差)。一个常数模型总是预测y的期望值,而不考虑输入特征,得到的R^2得分为0.0。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 测试样本。对于某些估计量,这可以是预先计算的内核矩阵或通用对象列表,形状为(n_samples,n_samples_fitted),其中n_samples_fitted是用于拟合估计器的样本数。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真实值。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重。 |
| 返回值 | 说明 |
|---|---|
| score | float 预测值与真实值的R^2。 |
注
调用回归器中的score时使用的R2分数,multioutput='uniform_average'从0.23版开始使用 ,与r2_score默认值保持一致。这会影响多输出回归的score方法( MultiOutputRegressor除外)。
set_params(**params)
[源码]
设置此估计器的参数。
该方法适用于简单的估计器以及嵌套对象(例如管道)。后者具有形式为 <component>__<parameter>的参数,这样就可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估计器参数。 |
| 返回值 | 说明 |
|---|---|
| self | object 估计器实例。 |