sklearn.tree.DecisionTreeClassifier¶
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort='deprecated', ccp_alpha=0.0)
一个构造决策树的类。
想了解更多请看 用户指南.
| 参数 | 说明 |
|---|---|
| criterion | {“gini”, “entropy”}, default=”gini” 这个参数是用来选择使用何种方法度量树的切分质量的。当criterion取值为“gini”时采用 基尼不纯度(Gini impurity)算法构造决策树,当criterion取值为 “entropy” 时采用信息增益( information gain)算法构造决策树. |
| splitter | {“best”, “random”}, default=”best” 此参数决定了在每个节点上拆分策略的选择。支持的策略是“best” 选择“最佳拆分策略”, “random” 选择“最佳随机拆分策略”。 |
| max_depth | int, default=None 树的最大深度。如果取值为None,则将所有节点展开,直到所有的叶子都是纯净的或者直到所有叶子都包含少于min_samples_split个样本。 |
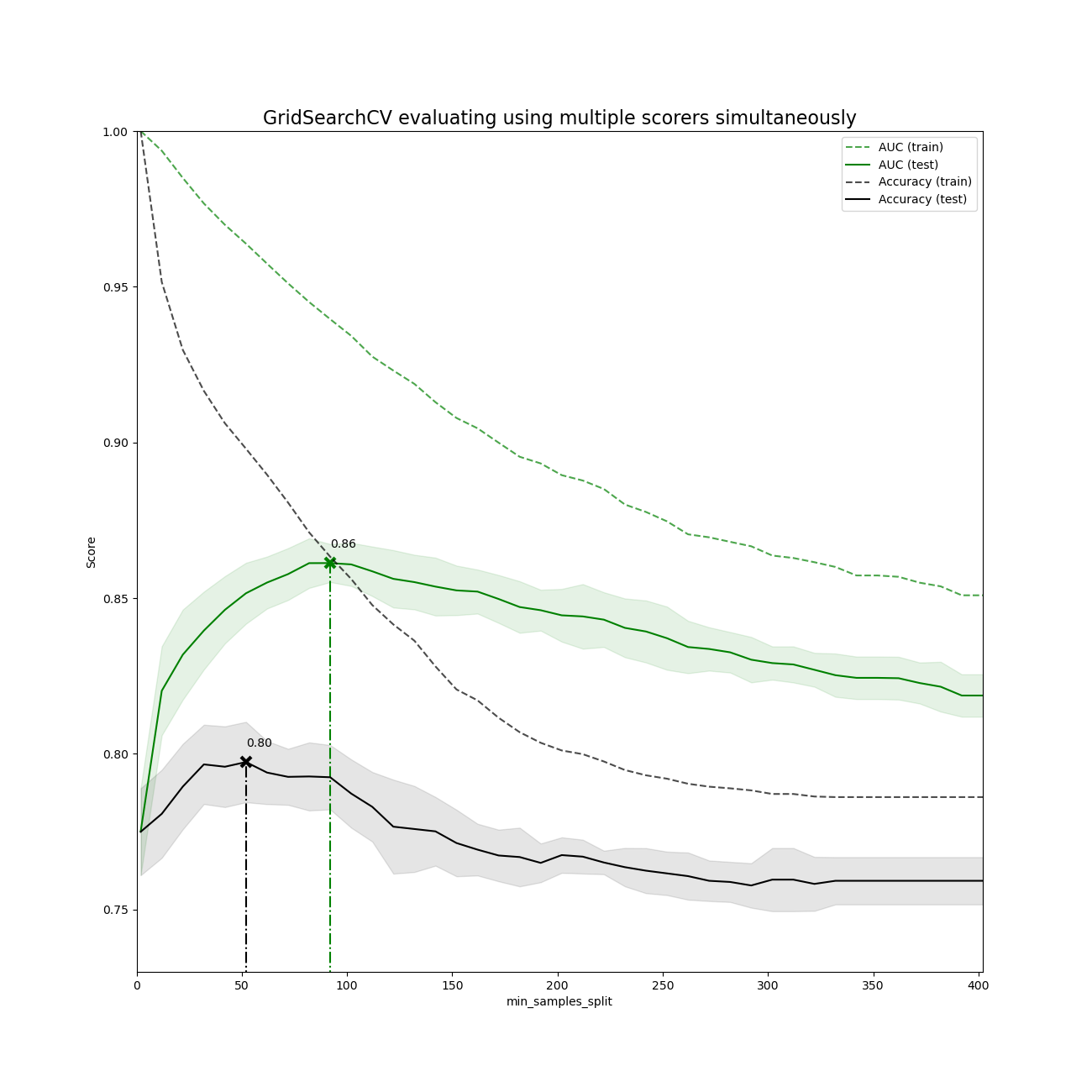
| min_samples_split | int or float, default=2 拆分内部节点所需的最少样本数: · 如果取值 int , 则将 min_samples_split视为最小值。· 如果为float,则 min_samples_split是一个分数,而ceil(min_samples_split * n_samples)是每个拆分的最小样本数。-注释 在版本0.18中更改:增加了分数形式的浮点值。 |
| min_samples_leaf | int or float, default=1 在叶节点处所需的最小样本数。 仅在任何深度的分裂点在左分支和右分支中的每个分支上至少留有 min_samples_leaf个训练样本时,才考虑。 这可能具有平滑模型的效果,尤其是在回归中。· 如果为int,则将 min_samples_leaf视为最小值· 如果为float,则 min_samples_leaf是一个分数,而ceil(min_samples_leaf * n_samples)是每个节点的最小样本数。- 注释: 在版本0.18中发生了更改:添加了分数形式的浮点值。 |
| min_weight_fraction_leaf | float, default=0.0 在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。 如果未提供 sample_weight,则样本的权重相等。 |
| max_features | int, float or {“auto”, “sqrt”, “log2”}, default=None 寻找最佳分割时要考虑的特征数量: - 如果为 int,则在每次拆分时考虑max_features功能。- 如果为 float,则max_features是一个分数,而int(max_features * n_features)是每个分割处的特征数量。- 如果为 “auto”,则max_features = sqrt(n_features)。- 如果为 “sqrt”,则max_features = sqrt(n_features)。 - 如果为 “log2”,则max_features = log2(n_features)。- 如果为 None,则max_features = n_features。注意:直到找到至少一个有效的节点样本分区,分割的搜索才会停止,即使它需要有效检查的特征数量多于 max_features也是如此。 |
| random_state | int, RandomState instance, default=None 此参数用来控制估计器的随机性。即使分割器设置为“最佳”,这些特征也总是在每个分割中随机排列。当 max_features <n_features时,该算法将在每个拆分中随机选择max_features,然后再在其中找到最佳拆分。但是,即使max_features = n_features,找到的最佳分割也可能因不同的运行而有所不同。 就是这种情况,如果标准的改进对于几个拆分而言是相同的,并且必须随机选择一个拆分。 为了在拟合过程中获得确定性的行为,random_state必须固定为整数。 有关详细信息,请参见词汇表。 |
| max_leaf_nodes | int, default=None 优先以最佳方式生成带有 max_leaf_nodes的树。 最佳节点定义为不纯度的相对减少。 如果为None,则叶节点数不受限制。 |
| min_impurity_decrease | float, default=0.0 如果节点分裂会导致不纯度的减少大于或等于该值,则该节点将被分裂。 加权不纯度减少方程如下: N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity) 其中 N是样本总数,N_t是当前节点上的样本数,N_t_L是左子节点中的样本数,N_t_R是右子节点中的样本数。如果给 sample_weight传了值,则N , N_t , N_t_R 和 N_t_L均指加权总和。在 0.19 版新增 。 |
| min_impurity_split | float, default=0 树模型停止生长的阈值。如果节点的不纯度高于阈值,则该节点将分裂,否则为叶节点。 警告: 从版本0.19开始被弃用: min_impurity_split在0.19中被弃用,转而支持min_impurity_decrease。min_impurity_split的默认值在0.23中从1e-7更改为0,在0.25中将被删除。使用min_impurity_decrease代替。 |
| class_weight | dict, list of dict or “balanced”, default=None 以 {class_label: weight}的形式表示与类别关联的权重。如果取值None,所有分类的权重为1。对于多输出问题,可以按照y的列的顺序提供一个字典列表。注意多输出(包括多标签) ,应在其自己的字典中为每一列的每个类别定义权重。例如:对于四分类多标签问题, 权重应为[{0:1、1:1:1],{0:1、1:5},{0:1、1:1:1},{0:1、1: 1}],而不是[{1:1},{2:5},{3:1},{4:1}]。 “平衡”模式使用y的值自动将权重与输入数据中的类频率成反比地调整为 n_samples /(n_classes * np.bincount(y))。对于多输出,y的每一列的权重将相乘。 请注意,如果指定了 sample_weight,则这些权重将与sample_weight(通过fit方法传递)相乘。 |
| presort | deprecated, default=’deprecated’ 此参数已弃用,并将在v0.24中删除。 注意:从0.22版开始已弃用。 |
| ccp_alpha | non-negative float, default=0.0 用于最小化成本复杂性修剪的复杂性参数。 将选择成本复杂度最大且小于ccp_alpha的子树。 默认情况下,不执行修剪。 有关详细信息,请参见最小成本复杂性修剪。 |
| 属性 | 说明 |
|---|---|
| classes_ | ndarray of shape (n_classes,) or list of ndarray 类标签(单输出问题)或类标签数组的列表(多输出问题)。 |
| feature_importances_ | ndarray of shape (n_features,) 返回特征重要程度数据。 |
| max_features_ | intmax_features 的推断值。 |
| n_classes_ | int or list of int 整数的类别数(单输出问题),或者一个包含所有类别数量的列表(多输出问题)。 |
| n_features_ | int 执行模型拟合训练时的特征数量。 |
| n_outputs_ | int 执行模型拟合训练时的输出数量。 |
| tree_ | Tree 基础的Tree对象。请通过 help(sklearn.tree._tree.Tree)查看Tree对象的属性,并了解决策树的结构以了解这些属性的基本用法。 |
另见
DecisionTreeRegressor一个回归决策树.
注意
控制树模型规模的默认的参数值(例如 max_depth, min_samples_leaf, 等)会导致树的完全生长和未修剪,在某些数据集上树的复杂度可能非常大。 为了减少内存消耗,应通过设置这些参数值来控制树的复杂性和大小。
参考文献
1、https://en.wikipedia.org/wiki/Decision_tree_learning
2、L. Breiman, J. Friedman, R. Olshen, and C. Stone, “Classification and Regression Trees”, Wadsworth, Belmont, CA, 1984.
3、T. Hastie, R. Tibshirani and J. Friedman. “Elements of Statistical Learning”, Springer, 2009.
4、L. Breiman, and A. Cutler, “Random Forests”, https://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm
示例
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import cross_val_score
>>> from sklearn.tree import DecisionTreeClassifier
>>> clf = DecisionTreeClassifier(random_state=0)
>>> iris = load_iris()
>>> cross_val_score(clf, iris.data, iris.target, cv=10)
... # doctest: +SKIP
...
array([ 1. , 0.93..., 0.86..., 0.93..., 0.93...,
0.93..., 0.93..., 1. , 0.93..., 1. ])
方法
| 方法 | 说明 |
|---|---|
apply(X[, check_input]) |
返回每个叶子节点上被预测样本的索引。 |
cost_complexity_pruning_path(X, y[, …]) |
在最小化成本复杂性修剪期间计算修剪路径 。 |
decision_path(X[, check_input]) |
返回决策树的决策路径。 |
fit(X, y[, sample_weight, check_input, …]) |
根据训练集(X,y)建立决策树分类器。 |
get_depth() |
返回决策树的深度 。 |
get_n_leaves() |
返回决策树的叶子数。 |
get_params([deep]) |
获取此估算器的参数。 |
predict(X[, check_input]) |
预测X的类别或回归值。 |
predict_log_proba(X) |
预测输入样本X的类对数概率。 |
predict_proba(X[, check_input]) |
预测输入样本X的类别概率。 |
score(X, y[, sample_weight]) |
返回给定测试数据和标签上的平均准确度。 |
set_params(**params) |
设置此估算器的参数。 |
__init__(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort='deprecated', ccp_alpha=0.0)
初始化自身对象。获取准确信息可以使用代码help(type(self)) 查看。
apply(X, check_input=True)
返回每个叶子节点上被预测样本的索引。
新增于 0.17 版。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。 在内部,它将转换为 dtype = np.float32,并且如果提供给稀疏矩阵将转化为csc_matrix。 |
| check_input | bool, default=True 允许绕过多个输入检查。 除非您知道自己要做什么,否则请勿使用此参数。 |
| 返回值 | |
|---|---|
| X_leaves | array-like of shape (n_samples,) 对于X中的每个数据点x,返回以x结尾的叶子的索引。叶子在 [0; self.tree_.node_count)范围中,可能在编号上有间隔。 |
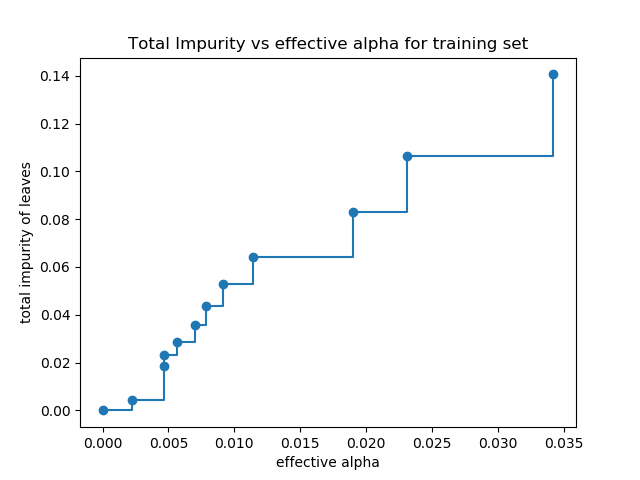
cost_complexity_pruning_path(X, y, sample_weight=None)
在最小化成本复杂性修剪期间计算修剪路径 。
有关修剪过程的详细信息,请参见 Minimal Cost-Complexity Pruning 。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 训练输入样本。 在内部,它将转换为 dtype = np.float32,并且如果提供给稀疏矩阵将转化为csc_matrix。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) 目标值(类标签)为整数或字符串。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重。如果为None,则对样本进行平均加权。 在每个节点中搜索拆分时,将忽略创建净值为零或负权重的拆分子节点。 如果拆分会导致任何单个类在任一子节点中都负权重,则也将忽略拆分。 |
| 返回值 | 说明 |
|---|---|
| ccp_path | Bunch类字典对象,具有以下属性。 |
| ccp_alphas | ndarray 修剪期间子树的有效Alpha。 |
| impurities | ndarray 子树中不纯度的总和将用于 ccp_alphas中的相应alpha值。 |
decision_path(X, check_input=True)
返回树中的决策路径。
版本0.18中的新功能。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。在内部,它将转换为 dtype = np.float32,并且如果提供给稀疏矩阵将转化为csc_matrix。 |
| check_input | bool, default=True 允许绕过多个输入检查。 除非您知道自己要做什么,否则请勿使用此参数。 |
| 返回值 | 说明 |
|---|---|
| indicator | sparse matrix of shape (n_samples, n_nodes) 返回节点指示符CSR矩阵,其中非零元素表示样本通过节点。 |
property feature_importances_
返回特征的重要性。
特征的重要性计算为该特征带来的标准的(标准化)总缩减。 这也被称为基尼重要性。
警告:基于不纯度的特征重要性可能会误导高基数特征(许多唯一值)。另请参见sklearn.inspection.permutation_importance 。
| 返回值 | 说明 |
|---|---|
| feature_importances_ | ndarray of shape (n_features,) 按照特征(基尼重要性)对规则减少总和做正则化处理 |
fit(X, y, sample_weight=None, check_input=True, X_idx_sorted=None)
从训练集(X, y)构建决策树分类器。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入的训练集。在内部,它将转换为 dtype = np.float32,并且如果提供给稀疏矩阵将转化为csc_matrix。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) 目标值(类标签)为整数或字符串。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重,如果为None,那么样本的权重相等。 当在每个节点中搜索分割时,将忽略创建具有净零权值或负权值的子节点的分割。如果分割会导致任何一个类在任一子节点中具有负权值,那么分割也将被忽略。 |
| check_input | bool, default=True 允许绕过多个输入检查。 除非您知道自己要做什么,否则不要使用此参数。 |
| X_idx_sorted | array-like of shape (n_samples, n_features), default=None 分类后的训练输入样本的索引。如果同一数据集上生长了许多树,那么就允许在树之间缓存顺序。如果没有,数据将在这里排序。除非你知道怎么做,否则不要使用这个参数。 |
| 返回值 | 说明 |
|---|---|
| self | DecisionTreeClassifier 拟合估计器。 |
get_depth()
[源码]
返回决策树的深度。
一棵树的深度是根与任何叶子之间的最大距离。
| 返回值 | 说明 |
|---|---|
| self.tree_.max_depth | int 树的最大深度 |
get_n_leaves()
[源码]
返回决策树的叶子数。
| 返回值 | 说明 |
|---|---|
| self.tree_.n_leaves | int 叶子的数量 |
get_params(deep=True)
[源码]
获取这个估计器的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为真,将返回此估计器的参数以及包含的作为估计器的子对象。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名称与参数值的映射 |
predict(X, check_input=True)
[源码]
预测X的类或回归值。
对于分类模型,返回X中每个样本的预测类。对于回归模型,返回基于X的预测值。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。 在内部,它将被转换为 dtype = np.float32,并且如果将稀疏矩阵提供给稀疏的csr_matrix。 |
| check_input | bool, default=True 允许绕过多个输入检查。 除非您知道自己要做什么,否则不要使用此参数。 |
| 返回值 | 说明 |
|---|---|
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) 预测的类或预测值。 |
predict_log_proba(X)
[源码]
预测输入样本X的类对数概率。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。 在内部,它将被转换为 dtype = np.float32,并且如果将稀疏矩阵提供给稀疏的csr_matrix。 |
| 返回值 | 说明 |
|---|---|
| proba | ndarray of shape (n_samples, n_classes) or list of n_outputs such arrays if n_outputs > 1 输入样本的对数概率。类的顺序对应于属性classes_中的顺序。 |
predict_proba(X, check_input=True)
[源码]
预测输入样本X的类别概率。
预测的类别概率是叶子中相同类别的样本的分数。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。 在内部,它将被转换为 dtype = np.float32,并且如果将稀疏矩阵提供给稀疏的csr_matrix。 |
| check_input | bool, default=True 允许绕过多个输入检查。 除非您知道自己要做什么,否则不要使用此参数 |
| 返回值 | 说明 |
|---|---|
| proba | ndarray of shape (n_samples, n_classes) or list of n_outputs such arrays if n_outputs > 1 输入样本的类型概率。类的顺序对应于属性classes_中的顺序。 |
score(X, y, sample_weight=None)
[源码]
返回给定测试数据在对应标签上的平均准确度。
在多标签分类中,返回的是精度子集,这是一个苛刻的指标,因为你需要对每个样本正确预测每个标签的精度。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 测试样本 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真实标签 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重 |
| 返回值 | 说明 |
|---|---|
| score | floatself.predict(X) wrt. y的平均准确度 |
set_params(**params)
[源码]
设置这个估计器的参数。
该方法适用于简单的估计器以及嵌套对象(例如管道)。 后者具有形式上的参数<component> __ <parameter>,以便可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估计器参数 |
| 返回值 | 说明 |
|---|---|
| self | object 估计器实例 |