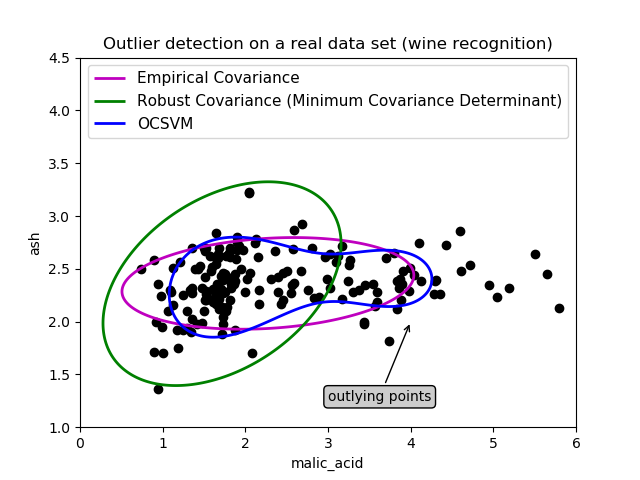
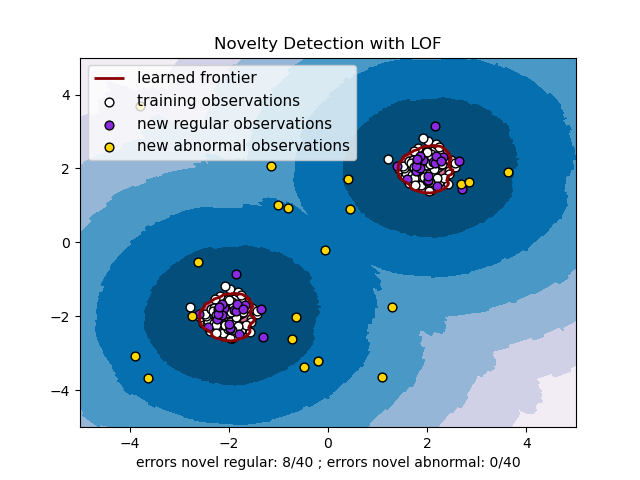
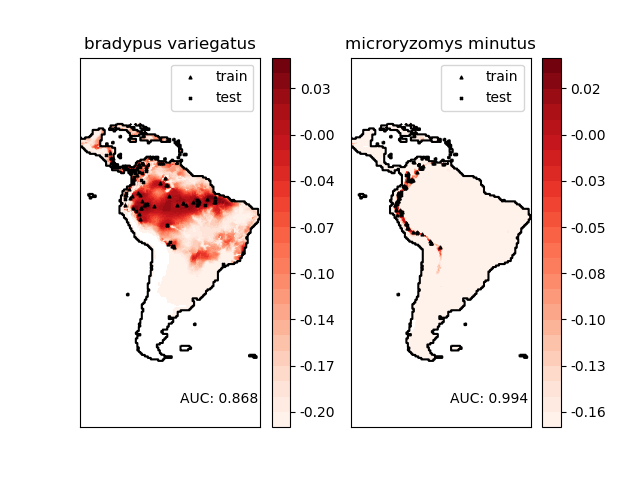
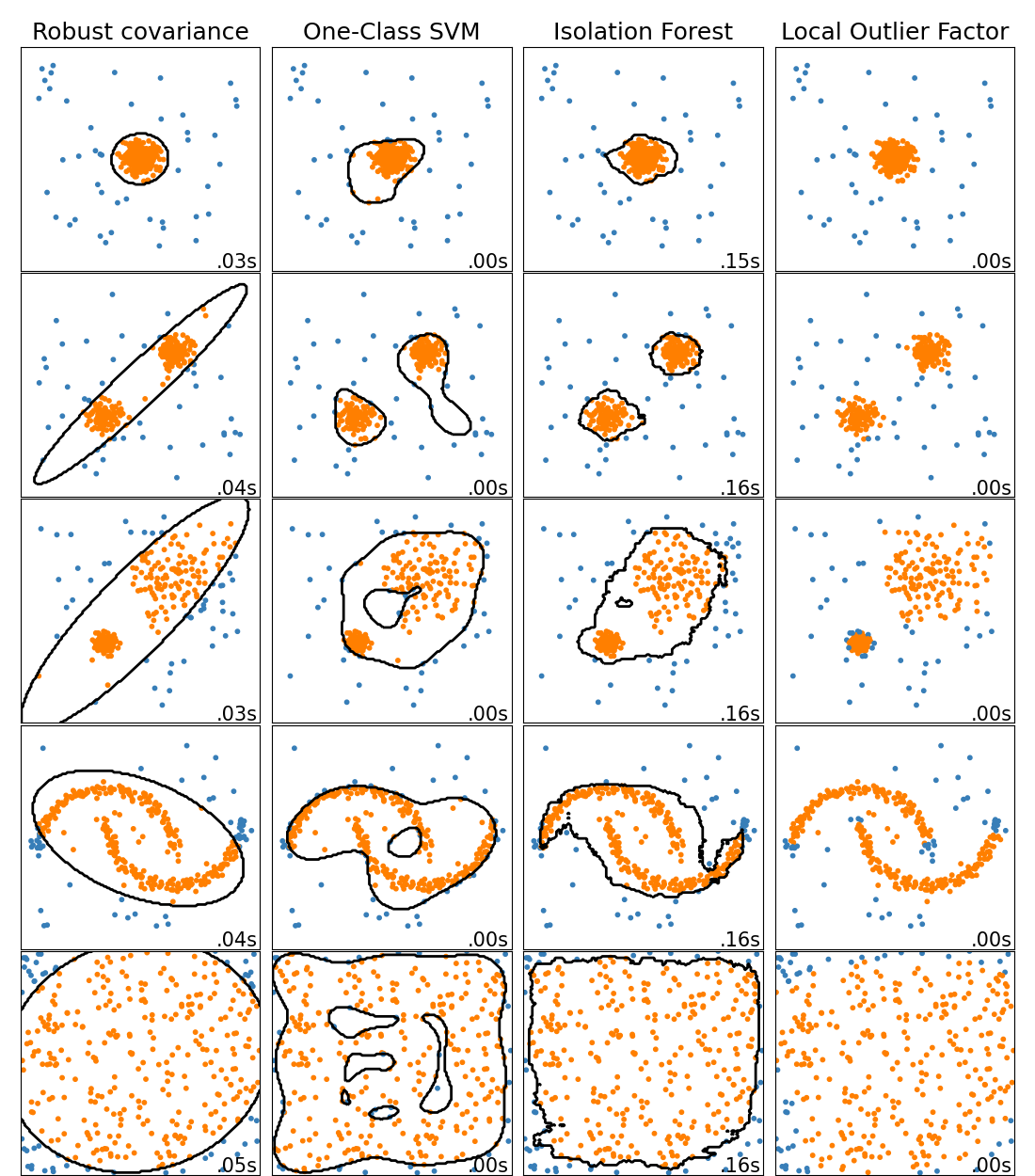
sklearn.svm.OneClassSVM¶
class sklearn.svm.OneClassSVM(*, kernel='rbf', degree=3, gamma='scale', coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1)
无监督异常值检测。
估计高维分布的支持。
该实现基于libsvm。
更多信息请参阅 使用指南.
| 参数 | 说明 |
|---|---|
| kernel | {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, 默认=’rbf’ 指定算法中使用的内核类型。它必须是“linear”,“poly”,“rbf”,“sigmoid”,“precomputed”或者“callable”中的一个。如果没有给出,将默认使用“rbf”。如果给定了一个可调用函数,则用它来预先计算核矩阵。 |
| degree | 整数型,默认=3 多项式核函数的次数(' poly ')。将会被其他内核忽略。 |
| gamma | 浮点数或者{‘scale’, ‘auto’} , 默认=’scale’ 核系数包含‘rbf’, ‘poly’ 和‘sigmoid’ 如果gamma='scale'(默认),则它使用1 / (n_features * X.var())作为gamma的值, 如果是auto,则使用1 / n_features。 在0.22版本有改动:默认的gamma从“auto”改为“scale”。 |
| coef0 | 浮点数,默认=0.0 核函数中的独立项。它只在' poly '和' sigmoid '中有意义。 |
| tol | 浮点数,默认=1e-3 残差收敛条件。 |
| nu | 浮点数,默认=0.5 边界误差分数的上限和支持向量分数的下限。区间限定在(0,1)内。默认情况下取0.5。 |
| shrinking | 布尔值,默认=True 是否使用缩小启发式,参见使用指南. |
| cache_size | 浮点数,默认=200 指定内核缓存的大小(以MB为单位)。 |
| verbose | 布尔值,默认=False 是否启用详细输出。 请注意,此参数针对liblinear中运行每个进程时设置,如果启用,则可能无法在多线程上下文中正常工作。 |
| max_iter | 整数型,默认=-1 对求解器内的迭代进行硬性限制,或者为-1(无限制时)。 |
| 属性 | 说明 |
|---|---|
| support_ | 形如(n_SV,)的数组 支持向量的指标。 |
| support_vectors_ | 形如(n_SV, n_features)的数组 支持向量 |
| dual_coef_ | 形如(n_class-1, n_SV)的数组 决策函数中支持向量的系数。 |
| coef_ | 形如(n_class * (n_class-1) / 2, n_features)的数组 分配给特征的权重(原始问题的系数),仅在线性内核的情况下可用。 coef_是一个继承自raw_coef_的只读属性,它遵循liblinear的内部存储器布局。 |
| intercept_ | 形如(n_class * (n_class-1) / 2,)的数组 决策函数中的常量。 |
| offset_ | 浮点型 用于从原始分数定义决策函数的偏移量。我们有这样的关系:decision_function = score_samples - offset_。偏移量与intercept_相反,是为了与其他离群点检测算法保持一致而提供的。 此部分新增在版本0.20。 |
| fit_status_ | 整数型 如果拟合无误,则为0;如果算法未收敛,则为1。 |
示例:
>>> from sklearn.svm import OneClassSVM
>>> X = [[0], [0.44], [0.45], [0.46], [1]]
>>> clf = OneClassSVM(gamma='auto').fit(X)
>>> clf.predict(X)
array([-1, 1, 1, 1, -1])
>>> clf.score_samples(X)
array([1.7798..., 2.0547..., 2.0556..., 2.0561..., 1.7332...])
方法:
decision_function(X) |
返回各样本点到超平面的函数距离 |
|---|---|
fit(X, y[, sample_weight]) |
根据给定的训练数据拟合支持向量机模型。 |
fit_predict(X[, y]) |
对X拟合并返回X的标签。 |
get_params([deep]) |
获取这个估计器的参数。 |
predict(X) |
在X中对样本进行分类 |
score_samples(X) |
样本的原始评分功能。 |
set_params(**params) |
设置这个估计器的参数。 |
__init__(*, kernel='rbf', degree=3, gamma='scale', coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1)
初始化self。请参阅help(type(self)获取准确的说明。
decision_function
返回各样本点到超平面的函数距离(signed distance),正的为正常样本,负的为异常样本
| 参数 | 说明 |
|---|---|
| X | 形如(n_samples, n_features)的数组 数据矩阵 |
| 返回值 | 说明 |
|---|---|
| dec | 形如(n_samples,)的数组 返回模型中每个类的样本决策函数。 |
fit(X, y=None, sample_weight=None, **params)
检测样本集合X的软边界。
| 参数 | 说明 |
|---|---|
| X | 形如(n_samples, n_features) 的数组或者稀疏矩阵 训练向量,其中n_samples为样本数量,n_features为特征数量。 |
| sample_weight | 形如(n_samples,)的数组,默认=None 样本的权重。每个样品重新定标C。较高的权重将使分类器更加注重这些样本点。 |
| y | 可忽略 未使用,按惯例提供API一致性。 |
| 返回值 | 说明 |
|---|---|
| self | object |
注:
如果X不是C-ordered的连续数组,则将其复制。
fit_predict(X, y=None)
对X进行拟合并返回X的标签
对于离群值返回-1,否则返回1
| 参数 | 说明 |
|---|---|
| X | 形如(n_samples, n_features) 的数组或者稀疏矩阵 |
| y | 可忽略 未使用,按惯例提供API一致性。 |
get_params(deep=True)
获取当前估计量的参数
| 参数 | 说明 |
|---|---|
| deep | bool, default = True 如果为真,则将返回此估计器和其所包含子对象的参数 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名被映射至他们的值 |
predict(X)
对X中的样本执行分类。
对于返回值为+1或-1的one-class模型
| 参数 | 说明 |
|---|---|
| X | 形如(n_samples, n_features) 或者 (n_samples_test, n_samples_train)的数组或者稀疏矩阵 对于内核=“precomputed”,X的预期形状为(n_samples_test,n_samples_train)。 |
| 返回值 | 说明 |
|---|---|
| y_pred | 形如(n_sample, )的数组 X中样本的类别标签。 |
score_samples(X)
样本的原始评分功能。
| 参数 | 说明 |
|---|---|
| X | 形如(n_samples, n_features)的数组 数据矩阵 |
| 返回值 | 说明 |
|---|---|
| score_samples | 形如(n_samples, )的数组 返回样本的(未移位)评分函数。 |
set_params(self, **params)
设置当前估计量的参数。
该方法适用于简单估计量和嵌套对象(如pipline)。后者具有形式为<component>_<parameter>的参数,这样就让更新嵌套对象的每个组件成为了可能。
| 参数 | 说明 |
|---|---|
| **params | dict 量参数 |
| 返回值 | 说明 |
|---|---|
| self | object 估计器实例 |