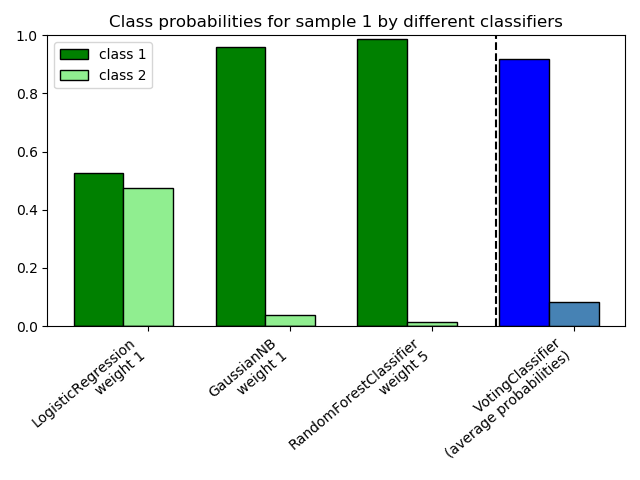
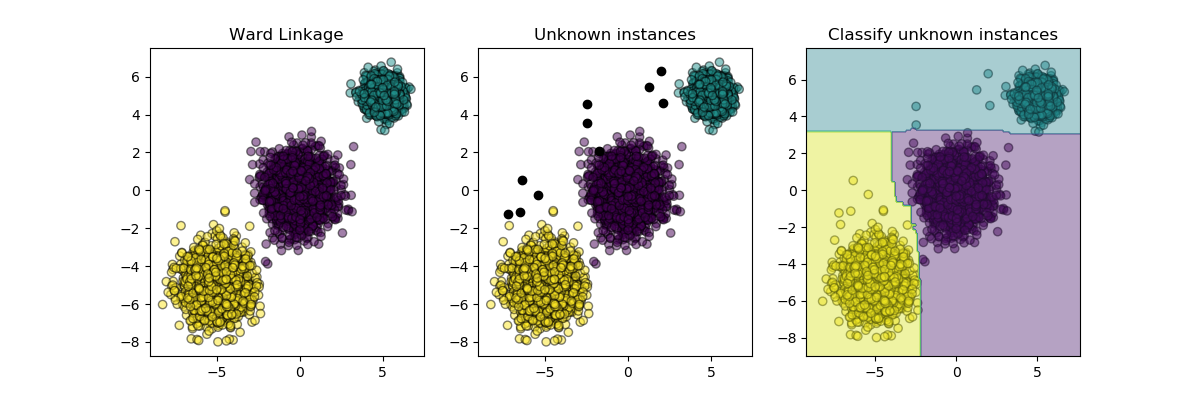
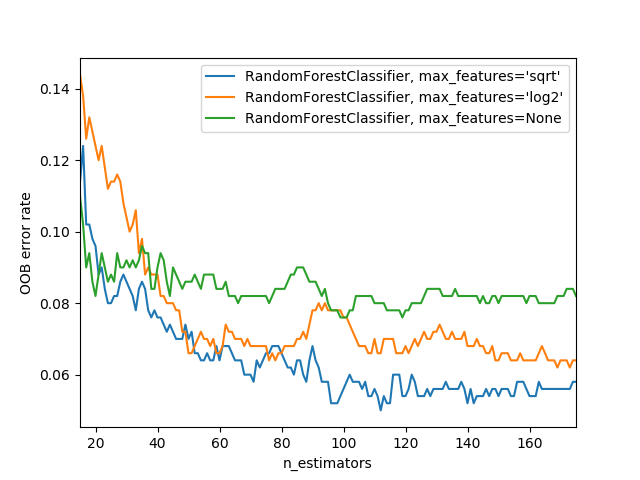
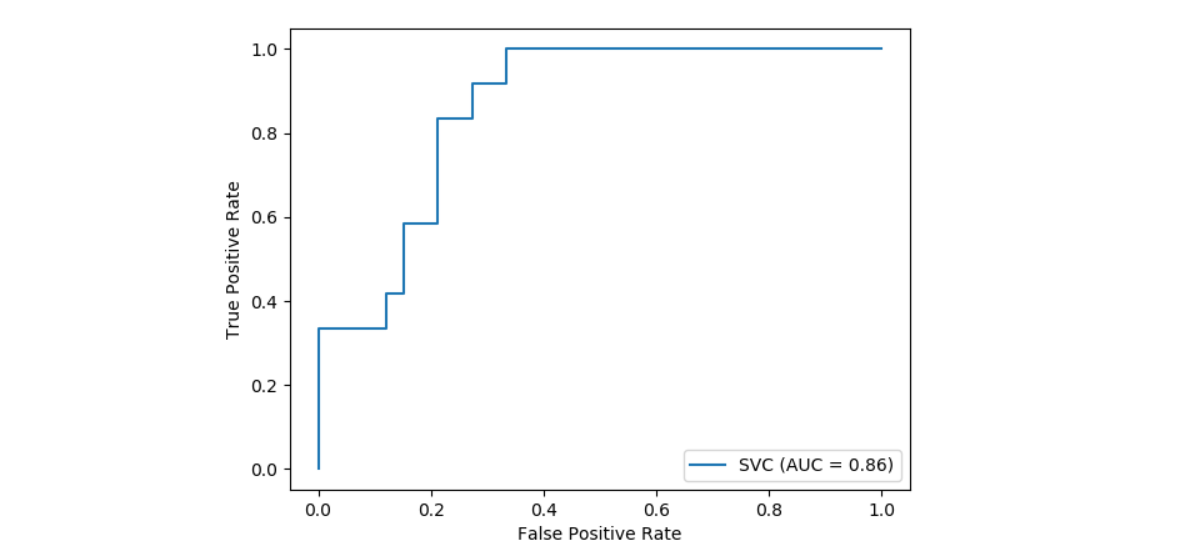
sklearn.ensemble.RandomForestClassifier¶
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
一个随机森林分类器。
随机森林是一种元估计器,它在数据集的不同子样本上匹配许多决策树分类器,并使用平均来提高预测精度和控制过拟合。如果bootstrap=True(默认),则使用max_samples参数控制子样本的大小,否则将使用整个数据集来构建每棵树。
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| n_estimators | int, default=100 森林中树木的数量。 在版本0.22中更改:默认值 n_estimators在0.22中从10更改为100。 |
| criterion | {“gini”, “entropy”}, default=”gini” 衡量分割质量的功能。支持对基尼杂质进行评价的"gini系数"和衡量信息增益的“熵” 注:这个参数是树特有的。 |
| max_depth | int, default=None 树的最大深度。如果为None,则将节点展开,直到所有叶子都是纯净的,或者直到所有叶子都包含少于min_samples_split个样本。 |
| min_samples_split | int or float, default=2 拆分内部节点所需的最少样本数: - 如果为int,则认为 min_samples_split是最小值。- 如果为float, min_samples_split则为分数, 是每个拆分的最小样本数。ceil(min_samples_split * n_samples)在版本0.18中更改:添加了分数的浮点值。 |
| min_samples_leaf | int or float, default=1 在叶节点处需要的最小样本数。仅在任何深度的分裂点在 min_samples_leaf左分支和右分支中的每个分支上至少留下训练样本时才会被考虑。同时,这种情况可能具有平滑模型的效果,尤其是在回归中。- 如果为int,则认为 min_samples_leaf是最小值。- 如果为float, min_samples_leaf则为分数, 是每个节点的最小样本数。ceil(min_samples_leaf * n_samples)在版本0.18中更改:添加了分数的浮点值。 |
| min_weight_fraction_leaf | float, default=0.0 一个叶节点上所需的(所有输入样本的)总权重的最小加权分数。如果未提供sample_weight,则样本的权重相等。 |
| max_features | {“auto”, “sqrt”, “log2”}, int or float, default=”auto” 寻找最佳分割时要考虑的功能数量: - 如果为int,则 max_features在每个分割处考虑特征。- 如果为float, max_features则为小数,并 在每次拆分时考虑要素。- 如果为auto,则为 max_features=sqrt(n_features)。- 如果是sqrt,则 max_features=sqrt(n_features)。- 如果为log2,则为 max_features=log2(n_features)。- 如果为None,则 max_features=n_features。注意:直到找到至少一个有效的节点样本分区,分割的搜索才会停止,即使它需要有效检查多于 max_features个数的要素也是如此。 |
| max_leaf_nodes | int, default=Nonemax_leaf_nodes以最好的方式进行“种树”。杂质的相对减少的节点被当作最佳节点。如果为None,则叶节点数不受限制。 |
| min_impurity_decrease | float, default=0.0 如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。 加权减少杂质的方程式如下: N_t / N * (impurity - N_t_R / N_t * right_impurity - N_t_L / N_t * left_impurity)其中, N是样本总数,N_t是当前节点上N_t_L的样本数,是左子节点中的样本N_t_R数,是右子节点中的样本数。N,N_t,N_t_R并且N_t_L都指的是加权和,如果sample_weight获得通过。版本0.19中的新功能。 |
| min_impurity_split | float, default=None 树提升提前停止的阈值。如果节点的杂质高于阈值,则该节点将分裂,否则为叶。 - 从版本0.19 min_impurity_split开始不推荐使用:在版本0.19中不再推荐使用 min_impurity_decrease。的默认值 min_impurity_split在0.23中从1e-7更改为0,并将在0.25中删除。使用min_impurity_decrease代替。 |
| bootstrap | bool, default=False 创建树时是否使用引导程序样本。如果为False,则将整个数据集用于构建每棵树。 |
| oob_score | bool, default=False 是否使用袋外样本估计泛化精度。 |
| n_jobs | int, default=None 要并行运行的作业的数量。 fit, predict, decision_path 和 apply都在树中并行化。除非在一个joblib.parallel_backend的内容中,否则None在joblib中的表示是1。-1表示使用所有处理器。有关更多详细信息,请参见Glossary。 |
| random_state | int, RandomState, default=None 控制3个随机性来源: - 构建树木时使用的示例的引导程序(如果 bootstrap=True)- 在每个节点上寻找最佳分割时要考虑的特征采样(如果 max_features < n_features)- 绘制每个 max_features的分割有关更多详细信息,请参见Glossary。 |
| verbose | int, default=0 在拟合和预测时控制冗余程度。 |
| warm_start | bool, default=False 当设置为True时,重用前面调用的解决方案来适应并向集成添加更多的评估器,否则,只会拟合完整的新森林。有关更多详细信息,请参见Glossary。 |
| class_weight | {“balanced”, “balanced_subsample”}, dict or list of dicts, default=None 以 {class_label: weight}的形式与类关联的权重。如果没有给出,所有类的权重都应该是1。对于多输出问题,可以按照y的列的顺序提供一个dict列表。multioutput注意(包括multilabel)权重的每一列应该为每个类定义自己的东西。例如,对于四级multilabel分类权重应该({0,1,1:1},{0,1,1:5},{0,1,1:1},{0:1,1:1}]不是[{1:1},{2:5},{3},{1})。 “平衡”模式使用y的值自动调整输入数据中与类频率成反比的权重,如 n_samples / (n_classes * np.bincount(y))。“balanced_subsample”模式与“balanced”模式相同,只是权重是基于自举样本为每棵生长的树计算的。 对于多输出,将y的每一列的权重相乘。 注意,如果指定了sample_weight,那么这些权重将与sample_weight相乘(通过fit方法传递)。 |
| ccp_alpha | non-negative float, default=0.0 复杂度参数用于最小代价复杂度剪枝。将选择代价复杂度最大且小于ccp_alpha的子树。默认情况下,不执行修剪。 有关更多详细信息,请参见Minimal Cost-Complexity Pruning。 0.22版中的新功能。 |
| max_samples | int or float, default=None 如果bootstrap为真,则需要从X中抽取样本来训练每个基估计量。 - 如果为 None(默认),则绘制X.shape[0]样本。- 如果为 int,则绘制 max_samples 样本。- 如果为 float, 则绘制 max_samples * X.shape[0]样本。因此,max_samples应该在区间(0,1)内。0.22版本新增功能 |
| 属性 | 说明 |
|---|---|
| base_estimator_ | ExtraTreesClassifier 子估计器模板,用于创建适合的子估计器的集合。 |
| estimators_ | list of DecisionTreeClassifier 拟合的次估计值的集合。 |
| classes_ | ndarray of shape (n_classes,) or a list of such arrays 类标签(单一输出问题)或类标签数组列表(多输出问题)。 |
| n_classes_ | int or list 类的数量(单个输出问题),或包含每个输出的类数量的列表(多输出问题)。 |
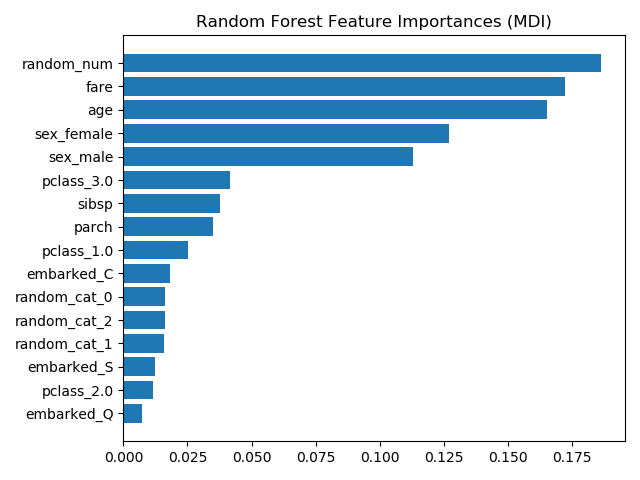
| feature_importances_ | ndarray of shape (n_features,) 基于杂质的特性重要性。 |
| n_features_ | int 执行 fit时的特征数。 |
| n_outputs_ | int 执行 fit时输出的数量。 |
| oob_score_ | float 使用袋外估计获得的训练数据集的得分。该属性仅在 oob_score为True时存在。 |
| oob_decision_function_ | ndarray of shape (n_samples, n_classes) 决策函数是通过训练集的袋外估计计算出来的。如果 n_estimators很小,可能在bootstrap过程中没有遗漏一个数据点。在这种情况下,oob_decision_function_可能包含NaN。该属性仅在oob_score为True时存在。 |
另见
DecisionTreeClassifier,ExtraTreesClassifier
注意
控制树大小的参数的默认值(例如max_depth, min_samples_leaf等)会导致完全生长和未修剪的树,在某些数据集上可能会非常大。为了减少内存消耗,应该通过设置这些参数值来控制树的复杂性和大小。
在每次分割时,特性总是随机地进行分配。因此,即使训练数据相同,max_features=n_features, bootstrap=False,在搜索最佳分割的过程中,如果枚举的几个分割对准则的改进相同,那么找到的最佳分割也会有所不同。为了在拟合过程中获得确定性行为,必须修复random_state。
参考文献
Breiman, “Random Forests”, Machine Learning, 45(1), 5-32, 2001.
实例
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_classification
>>> X, y = make_classification(n_samples=1000, n_features=4,
... n_informative=2, n_redundant=0,
... random_state=0, shuffle=False)
>>> clf = RandomForestClassifier(max_depth=2, random_state=0)
>>> clf.fit(X, y)
RandomForestClassifier(...)
>>> print(clf.predict([[0, 0, 0, 0]]))
[1]
方法
| 方法 | 说明 |
|---|---|
apply(X) |
将森林中的树应用于X,返回叶子索引。 |
decision_path(X) |
返回森林中的决策路径。 |
fit(X, y[, sample_weight]) |
从训练集(X, y)构建一个树的森林。 |
get_params([deep]) |
获取此估计器的参数。 |
predict(X) |
预测X的类。 |
predict_log_proba(X) |
预测X的类对数概率。 |
predict_proba(X) |
预测X的类概率。 |
score(X, y[, sample_weight]) |
返回给定测试数据和标签上的平均准确度。 |
*set_params(*params) |
设置此估算器的参数。 |
__init__(n_estimators=100, *, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
初始化self。有关准确的签名,请参见help(type(self))。
apply(X)
将森林中的树应用于X,返回叶子索引。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。在内部,它的 dtype将被转换为dtype=np.float32。如果提供了一个稀疏矩阵,它将被转换为一个csr_matrix。 |
| 返回值 | 说明 |
|---|---|
| X_leaves | ndarray of shape (n_samples, n_estimators) 对于X中的每个数据点x和森林中的每棵树,返回x最终所在的叶子的索引。 |
decision_path(X)
返回森林中的决策路径。
版本0.18中的新功能。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。在内部,它的 dtype将被转换为dtype=np.float32。如果提供了一个稀疏矩阵,它将被转换为一个csr_matrix。 |
| 返回值 | 说明 |
|---|---|
| indicator | sparse matrix of shape (n_samples, n_nodes) 返回一个节点指示符矩阵,其中非零元素表示样本经过节点。矩阵为CSR格式。 |
| n_nodes_ptr | ndarray of shape (n_estimators + 1,) 列元素来自指示符 [n_nodes_ptr[i]:n_nodes_ptr[i+1]]给出第i个估计器的指示值。 |
property feature_importances_
基于杂质的功能的重要性。
越高,功能越重要。特征的重要性计算为该特征带来的标准的(标准化)总缩减。这也被称为基尼重要性。
警告:基于杂质的特征重要性可能会误导高基数特征(许多唯一值)。另见 sklearn.inspection.permutation_importance。
| 返回值 | 说明 |
|---|---|
| feature_importances_ | ndarray of shape (n_features,) 除非所有树都是仅由根节点组成的单节点树,否则此数组的值总计为1,在这种情况下,它将是零数组。 |
fit(X, y, sample_weight = None)
根据训练集(X, y)建立树木森林。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。在内部,它的 dtype将被转换为dtype=np.float32。如果提供了一个稀疏矩阵,它将被转换为一个csr_matrix。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) 目标值(分类中的类标签,回归中的实数)。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重。如果没有,那么样本的权重相等。当在每个节点中搜索分割时,将忽略创建具有净零权值或负权值的子节点的分割。在分类的情况下,如果分割会导致任何一个类在任一子节点中具有负权值,那么分割也将被忽略。 |
| 返回值 | 说明 |
|---|---|
| self | object |
get_params(deep=True)
获取此估计器的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估算器和作为估算器的所包含子对象的参数。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名称与其值相对应。 |
predict(X)
预测X的分类。
输入样本的预测类是森林中树的投票,由它们的概率估计加权。也就是说,预测的类是树中概率估计均值最高的类。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。在内部,它的 dtype将被转换为dtype=np.float32。如果提供了一个稀疏矩阵,它将被转换为一个csr_matrix。 |
| 返回值 | 说明 |
|---|---|
| y | ndarray of shape (n_samples,) or (n_samples, n_outputs) 被预测的分类 |
predict_log_proba(X)
预测X分类的对数概率。
输入样本的预测类对数概率被计算为森林中树的平均预测类概率的对数。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。在内部,它的 dtype将被转换为dtype=np.float32。如果提供了一个稀疏矩阵,它将被转换为一个csr_matrix。 |
| 返回值 | 说明 |
|---|---|
| y | ndarray of shape (n_samples, n_classes), or a list of n_outputs 如果n_outputs > 1,则输出该数组。输入样本的类概率。类的顺序对应于属性classes_中的顺序。 |
predict_proba(X)
预测X分类概率。
输入样本的预测类概率被计算为森林中树的平均预测类概率。单个树的类概率是同一类的样本在叶子中的比例。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入样本。在内部,它的 dtype将被转换为dtype=np.float32。如果提供了一个稀疏矩阵,它将被转换为一个csr_matrix。 |
| 返回值 | 说明 |
|---|---|
| y | ndarray of shape (n_samples, n_classes), or a list of n_outputs 如果n_outputs > 1,则输出该数组。输入样本的类概率。类的顺序对应于属性classes_中的顺序。 |
score(X, y, sample_weight=None)
返回给定测试数据和标签的平均精度。
在多标签分类中,这是子集精度,这是一个苛刻的指标,因为你需要对每个样本正确预测每个标签集。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 测试样本。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的正确标签。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重。 |
| 返回值 | 说明 |
|---|---|
| score | float self.predict(X) 关于y的平均准确率。 |
set_params(**params)
设置该估计器的参数。
该方法适用于简单估计器和嵌套对象(如pipline)。后者具有形式为<component>_<parameter>的参数,这样就可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| params | dict 估计器参数 |
| 返回值 | 说明 |
|---|---|
| self | object 估计实例。 |