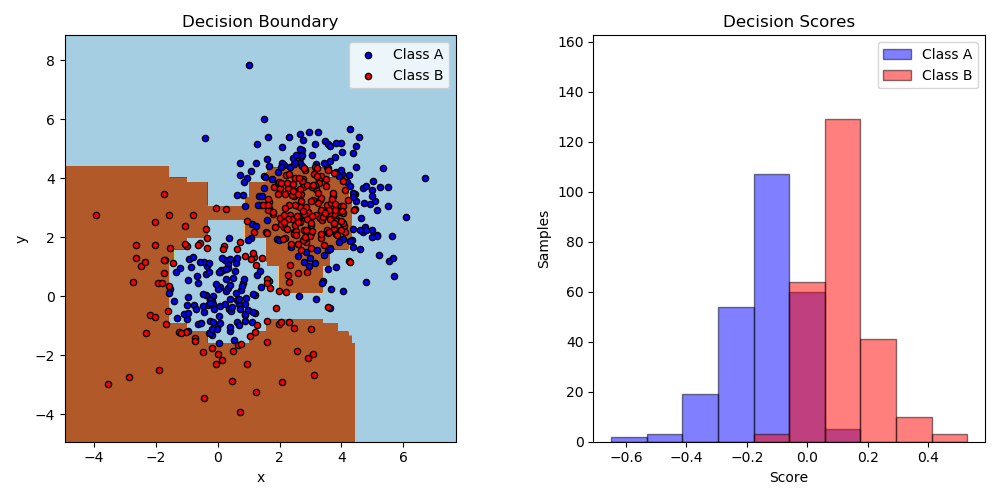
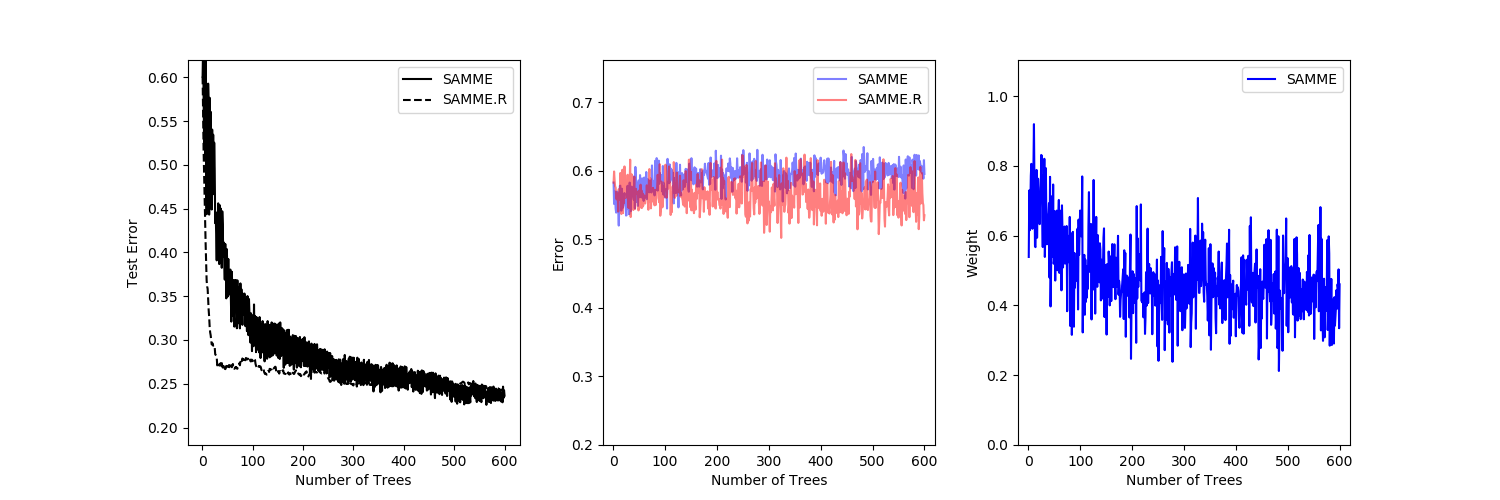
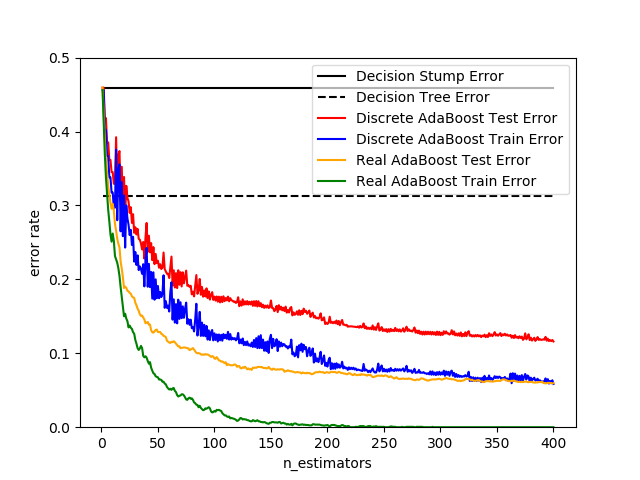
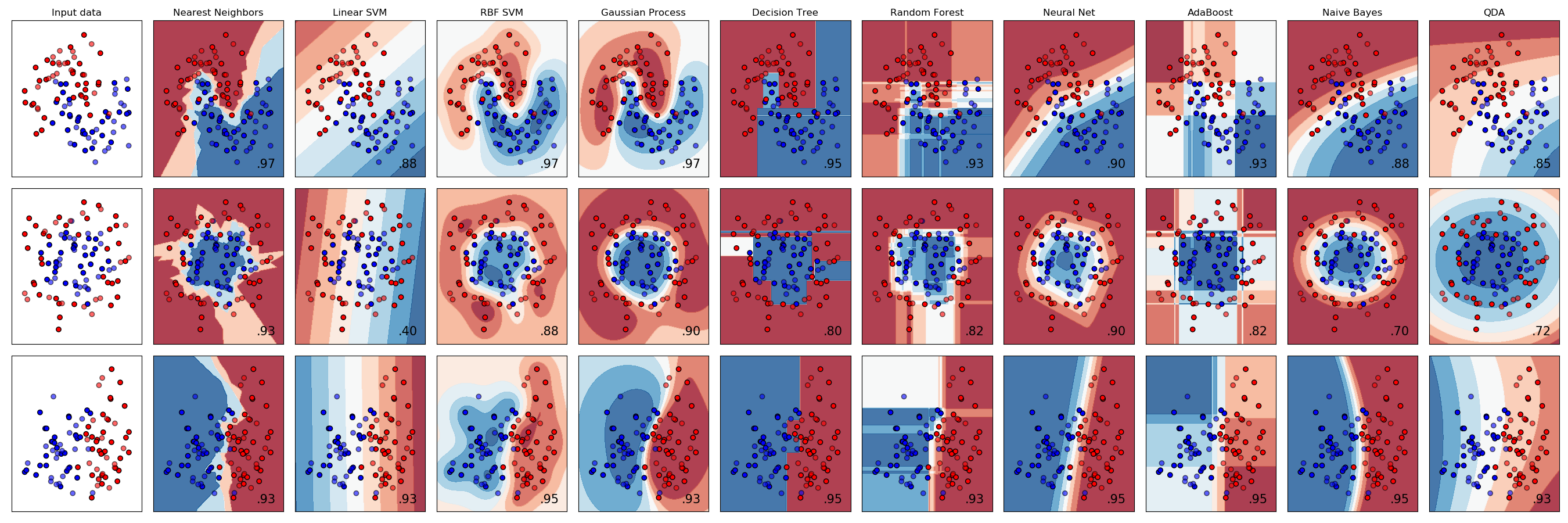
sklearn.ensemble.AdaBoostClassifier¶
class sklearn.ensemble.AdaBoostClassifier(base_estimator=None, *, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
一个AdaBoost分类器。
AdaBoost[1]分类器是一种元估计器,它首先在原始数据集上拟合一个分类器,然后在同一数据集上拟合分类器的额外副本,但其中错误分类实例的权重被调整,以便后续的分类器更多地关注困难的情况。
这个类实现的算法称为AdaBoost-SAMME [2]。
在用户指南中获取更多内容。
0.14版本中新增内容
| 参数 | 说明 |
|---|---|
| base_estimator | object, default = None 建立增强集成的基础估计器。需要支持示例权重,以及适当的 classes_和n_classes_属性。如果没有,那么基础估计器是DecisionTreeClassifier(max_depth=1) |
| n_estimators | int, default = 50 终止推进的估计器的最大数目。如果完全拟合,学习过程就会提前停止。 |
| learning_rate | float, default = 1 学习率通过 learning_rate缩小每个分类器的贡献程度。learning_rate和n_estimators之间存在权衡关系。 |
| algorithm | {'SAMME', 'SAMME.R'}, default = 'SAMME.R' 若为"SAMME.R"则使用real bossting算法。 base_estimator必须支持类概率的计算。若为SAMME,则使用discrete boosting算法。SAMME.R算法的收敛速度通常比SAMME快,通过更少的增强迭代获得更低的测试误差。 |
| random_state | int or RandomState, default = None 控制每个 base_estimator在每个增强迭代中给定的随机种子。因此,仅在base_estimator引入random_state时使用它。在多个函数调用之间传递可重复输出的整数。见Glossary。 |
| 属性 | 说明 |
|---|---|
| base_estimateor_ | estimator 用于增长集成的基础估计量。 |
| extimators_ | list of classsifiers 拟合的次估计量的集合。 |
| classes_ | ndarray of shape (n_classes, ) 类标签。 |
| n_classes_ | int 类的数量。 |
| estimator_weights_ | ndarray of floats 在增强的集合中每个估计量的权重。 |
| estimator_errors_ | ndarray of floats 每个估计量在增强集成中的分类误差。 |
| feature_importances_ | ndarray of shape (n_features, ) 基于杂质的特征重要性。 |
另见:
一个AdaBoost回归器,首先在原始数据集上拟合一个回归器,然后在同一数据集上拟合回归器的额外副本,但实例的权重会根据当前预测的误差进行调整。
GB采用前向阶梯的方式建立了可加性模型。回归树在二项或多项偏差损失函数的负梯度上拟合。二元分类是一种特殊的情况,其中只有一个回归树被诱导。
sklearn.tree.DecisionTreeClassifier一种用于分类的非参数监督学习方法。通过学习从数据特征推断出的简单决策规则,并创建预测目标变量值的模型。
参考文献
R33e4ec8c4ad5-1 Y. Freund, R. Schapire, “A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting”, 1995.
R33e4ec8c4ad5-2 Zhu, H. Zou, S. Rosset, T. Hastie, “Multi-class AdaBoost”, 2009.
实例
>>> from sklearn.ensemble import AdaBoostClassifier
>>> from sklearn.datasets import make_classification
>>> X, y = make_classification(n_samples=1000, n_features=4,
... n_informative=2, n_redundant=0,
... random_state=0, shuffle=False)
>>> clf = AdaBoostClassifier(n_estimators=100, random_state=0)
>>> clf.fit(X, y)
AdaBoostClassifier(n_estimators=100, random_state=0)
>>> clf.predict([[0, 0, 0, 0]])
array([1])
>>> clf.score(X, y)
0.983...
方法
| 方法 | 说明 |
|---|---|
decision_function(self, X) |
计算决策函数X |
fit(self, X, y[, sample_weight]) |
建立一个基于训练集(X,y)的增强分类器 |
get_params(self[, deep]) |
获得该估计量的参数值 |
predict(self, X) |
预测X的分类 |
predict_log_proba(self, X) |
预测X的类对数概率 |
predict_proba(self, X) |
预测X的类概率 |
score(self, X, y[, sample_weight]) |
根据给定测试数据及标签,返回平均精度 |
set_params(self, **params) |
设置该估计量的参数 |
staged_decision_function(self, X) |
计算每个boosting迭代的X决策函数 |
staged_predict(self, X) |
返回对X的阶梯预测 |
staged_predict_proba(self, X) |
预测X的类概率 |
staged_score(self, X, y[, sample_weight]) |
返回X,y的阶梯分数 |
__init__(self, base_estimator=None, *, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
初始化的self。请参阅帮助(type(self))以获得准确的签名。
decision_function(self, X)
计算决策函数X。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_feature) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| score | ndarray of shape of (n_samples, k) 输入样本的决策函数。输出的顺序与classes_属性的顺序相同。二分类是 k== 1的一种特殊情况,否则k==n_classes。对于二分类,更接近-1或1的值分别更像classes_中的第一类或第二类。 |
property feature_importances_
基于不纯的特性重要性。
越高,功能越重要。一个特征的重要性被计算为该特征带来的标准的(归一化)总减少量。它也被称为基尼重要性。
警告: 针对高基数特性(许多唯一值),基于不纯的特性重要性可能会引起误解。作为备选,请参考 sklearn.inspection.permutation_importance。
| 返回值 | 说明 |
|---|---|
| feature_importances_ | ndarray of shape (n_features,) 特征重要性。 |
fit(self, X, y, sample_weight=None)
建立一个基于训练集(X,y)的增强分类器。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_sample, n_features) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| y | array-like of shape (n_samples, ) 目标值(非类标签)。 |
| sample_weight | array-like of shape (n_samples, ), default = None 样本权重。如果没有,则将样本权重初始化为 1 / n_samples。 |
| 返回值 | 说明 |
|---|---|
| self | object 拟合后的估计量 |
get_params(self, deep=True)
得到估计器的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default = True 如果为真,将返回此估计量的参数以及包含作为估计量的子对象。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 名称参数及他们所映射的值。 |
predict(self, X)
预测X的分类。
对输入样本的预测类别进行计算,作为分类器在集成中的加权平均预测。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| 返回值 | 说明 |
|---|---|
| y | ndarray of shape (n_sample, ) 预测类别。 |
predict_log_proba(self, X)
预测X分的对数概率
一个输入样本的预测类对数概率被计算为集成中分类器预测类对数概率的加权平均值。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| 返回值 | 说明 |
|---|---|
| p | ndarray of shape (n_samples, n_classes) 输入样本的分类概率。输出的顺序与其classes_属性相一致。 |
predict_proba(self, X)
预测X的类概率
一个输入样本的预测类概率被计算为集成中分类器预测类概率的加权平均值。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| 返回值 | 说明 |
|---|---|
| p | ndarray of shape (n_samples, n_classes) 输入样本的分类概率。输出的顺序与其classes_属性相一致。 |
score(self, X, y, sample_weight=None)
返回测试数据和标签的平均准确率。
在多标签分类中,这是子集精度,这是一个苛刻的指标,因为你需要对每个样本正确预测每个标签集。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_sample, n_features) 测试样本。 |
| y | array-like of shpe (n_sample, ) or (n_samples, n_outputs) X的正确标签。 |
| sample_weight | array-like of shape (n_samples, ), default = None 样本权重。 |
| 返回值 | 说明 |
|---|---|
| score | float self.predict(X) 关于y的平均准确率。 |
set_params(self, params)
设置该估计器的参数。
该方法适用于简单估计器和嵌套对象(如pipline)。后者具有形式为<component>_<parameter>的参数,这样就可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估计器参数 |
| 返回值 | 说明 |
|---|---|
| self | object 估计实例。 |
staged_decision_function(self, X)
计算每个boosting迭代的X决策函数。
该方法允许在每次增强迭代后进行监视(即测试集的决策误差)。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| 产出 | 说明 |
|---|---|
| score | generator of ndarray of shape (n_samples, k) 输入样本的决策函数。输出的顺序与classes_属性的顺序相同。二分类是 k == 1的一种特殊情况,否则k == n_classes。对于二分类,更接近-1或1的值分别更像classes_中的第一类或第二类。 |
staged_predict(self, X)
返回X阶段性的预测。
对输入样本的预测类别进行计算,作为分类器在集成中的加权平均预测。
该生成器方法在每次增强迭代后生成集成预测,并且因此允许监视,例如确定每次增强后测试集的预测。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_sample, n_features) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| 产出 | 说明 |
|---|---|
| y | generator of ndarray of shape (n_samples, ) 预测后的类别。 |
staged_predict_proba(self, X)
预测X的类概率。
将输入样本的预测类概率作为集成中分类器的预测类概率的加权平均来计算。
该生成器方法在每次递增迭代后生成集合预测的类概率,并且因此允许进行监视,比如在每次递增之后确定测试集上预测的类概率。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| 产出 | 说明 |
|---|---|
| p | ndarray of shape (n_samples, n_classes) 输入样本的分类概率。输出的顺序与其classes_属性相一致。 |
staged_score(self, X, y, sample_weight=None)
返回X,y阶段性的分数。
该生成器方法在每次递增迭代后生成集成分数,因此允许进行监视,比如在每次递增之后确定测试集上分数。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 为训练输入样本。稀疏矩阵可以是CSC, CSR, COO, DOK, LIL。COO, DOK和LIL被转换为CSR。 |
| y | **array-like of shpe (n_sample, ) ** X的正确标签。 |
| sample_weight | array-like of shape (n_samples, ), default = None 样本权重。 |
| 返回值 | 说明 |
|---|---|
| z | float |