

置换重要性与随机森林特征重要性(MDI)¶
在这个例子中,我们将比较随机RandomForestClassifier的基于不纯的的特征重要性和使用permutation_importance在titanic数据集上的排列重要性。我们将证明基于不纯度的特征重要性可以夸大数值特征的重要性。
此外,基于不纯度的随机森林特征重要性受到从训练数据集得出的统计数据的影响:即使对于无法预测目标变量的特征,其重要性也可能很高,只要模型有能力使用它们来过度拟合。
此示例演示如何使用置换重要性作为可以减轻这些限制的替代方法。
References:
[1] L. Breiman, “Random Forests”, Machine Learning, 45(1), 5-32,
https://doi.org/10.1023/A:1010933404324
print(__doc__)
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.inspection import permutation_importance
from sklearn.compose import ColumnTransformer
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
数据加载与特征工程
让我们用pandas来加载泰坦尼克号数据集的副本。下面展示了如何对数值特征和分类特征分别进行预处理。
我们还包括两个与目标变量(survived)没有任何关联的随机变量:
random_num是一个高基数的数值变量(与记录一样多的唯一值)random_cat是一个低基数的分类变量(3个可能的值)。
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
rng = np.random.RandomState(seed=42)
X['random_cat'] = rng.randint(3, size=X.shape[0])
X['random_num'] = rng.randn(X.shape[0])
categorical_columns = ['pclass', 'sex', 'embarked', 'random_cat']
numerical_columns = ['age', 'sibsp', 'parch', 'fare', 'random_num']
X = X[categorical_columns + numerical_columns]
X_train, X_test, y_train, y_test = train_test_split(
X, y, stratify=y, random_state=42)
categorical_pipe = Pipeline([
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
numerical_pipe = Pipeline([
('imputer', SimpleImputer(strategy='mean'))
])
preprocessing = ColumnTransformer(
[('cat', categorical_pipe, categorical_columns),
('num', numerical_pipe, numerical_columns)])
rf = Pipeline([
('preprocess', preprocessing),
('classifier', RandomForestClassifier(random_state=42))
])
rf.fit(X_train, y_train)

模型的精度
在检验特征重要性之前,重要的是要检查模型的预测性能是否足够高。事实上,我们对检查非预测模型的重要特征没有兴趣。
在这里可以观察到,训练的精度很高(随机森林模型有足够的能力完全记住训练集),但是由于随机森林的内置bagging,它仍然可以很好地推广到测试集。
也许可以通过限制树的容量(例如设置min_samples_leaf=5或者min_samples_leaf=10)来交换训练集的一些准确性,从而在不引入太多不适当的情况下限制过度拟合。
然而,让我们现在保持我们的高容量随机森林模型,以说明一些具有特性重要性的陷阱,对于具有许多唯一值的变量:
print("RF train accuracy: %0.3f" % rf.score(X_train, y_train))
print("RF test accuracy: %0.3f" % rf.score(X_test, y_test))
RF train accuracy: 1.000
RF test accuracy: 0.817
从平均不纯度减少(MDI)看树的特征重要性
基于不纯度的特征重要性将数值特征列为最重要的特征。因此,非预测的 random_num 变量是最重要的!
这个问题源于基于不纯度的特征重要性的两个限制
基于不纯度的重要性倾向于高基数(取值很多)特征; 基于不纯度的重要性是根据训练集统计量计算的,因此不能反映特征的能力,从而无法进行泛化到测试集的预测(当模型有足够的能力时)。
ohe = (rf.named_steps['preprocess']
.named_transformers_['cat']
.named_steps['onehot'])
feature_names = ohe.get_feature_names(input_features=categorical_columns)
feature_names = np.r_[feature_names, numerical_columns]
tree_feature_importances = (
rf.named_steps['classifier'].feature_importances_)
sorted_idx = tree_feature_importances.argsort()
y_ticks = np.arange(0, len(feature_names))
fig, ax = plt.subplots()
ax.barh(y_ticks, tree_feature_importances[sorted_idx])
ax.set_yticklabels(feature_names[sorted_idx])
ax.set_yticks(y_ticks)
ax.set_title("Random Forest Feature Importances (MDI)")
fig.tight_layout()
plt.show()
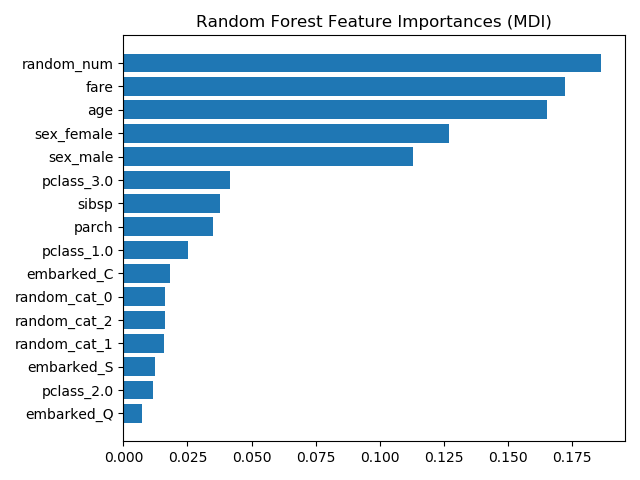 作为另一种选择,
作为另一种选择,rf的置换重要性是在一个在测试集上计算的。这说明基数低的分类特征,sex是最重要的特征。
还要注意的是,这两个随机特征的重要性都很低(接近0)。
result = permutation_importance(rf, X_test, y_test, n_repeats=10,
random_state=42, n_jobs=2)
sorted_idx = result.importances_mean.argsort()
fig, ax = plt.subplots()
ax.boxplot(result.importances[sorted_idx].T,
vert=False, labels=X_test.columns[sorted_idx])
ax.set_title("Permutation Importances (test set)")
fig.tight_layout()
plt.show()
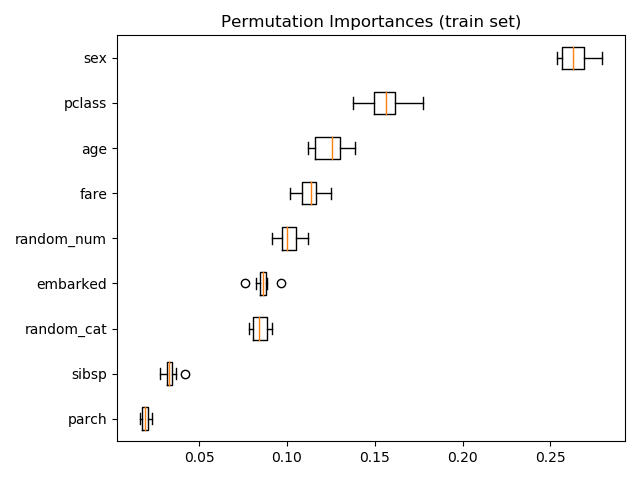
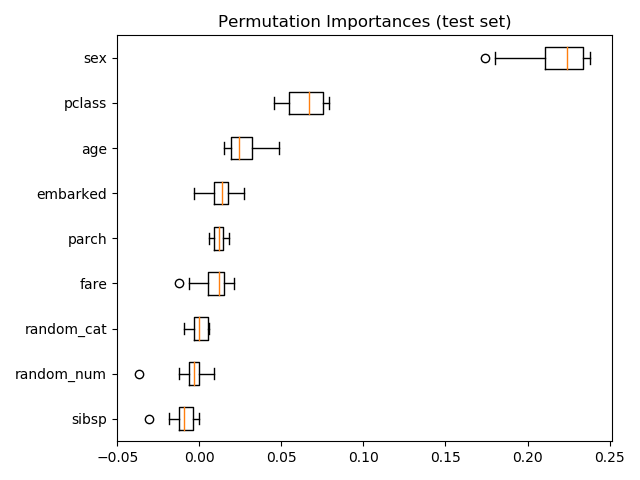 还可以计算训练集上的置换重要性。这表明,与在测试集上计算时相比,
还可以计算训练集上的置换重要性。这表明,与在测试集上计算时相比, random_num 获得了更高的重要性排序。这两幅图的不同之处在于证实了RF模型有足够的能力利用随机数值特征来过度拟合。您可以通过以下方法进一步确认这一点:使用带有 min_samples_leaf=10的受限 RF 重新运行此示例。
result = permutation_importance(rf, X_train, y_train, n_repeats=10,
random_state=42, n_jobs=2)
sorted_idx = result.importances_mean.argsort()
fig, ax = plt.subplots()
ax.boxplot(result.importances[sorted_idx].T,
vert=False, labels=X_train.columns[sorted_idx])
ax.set_title("Permutation Importances (train set)")
fig.tight_layout()
plt.show()
 脚本的总运行时间:(0分6.657秒)
脚本的总运行时间:(0分6.657秒)
Download Python source code: plot_permutation_importance.py
Download Jupyter notebook: plot_permutation_importance.ipynb

