

3.1 交叉验证:评估模型表现¶
通过对预测函数参数的训练,并在相同的数据集上进行测试,是一个错误的方法论:如果一个模型对相同样本标签进行训练和测试,模型的得分会很高,但在实验数据上的表现会很差,这种情况被称为过拟合。为了避免过拟合,在执行有监督的机器学习“实验”时,常见的方法是将已有数据集中保留一部分数据作为测试集,即Xtest, Ytest。需要注意的是:“实验”并不仅用于学术领域,因为在商业领域中,机器学习通常也是以实验为开端。如下是一个交叉验证流程图。最优参数选择可以参考grid search。
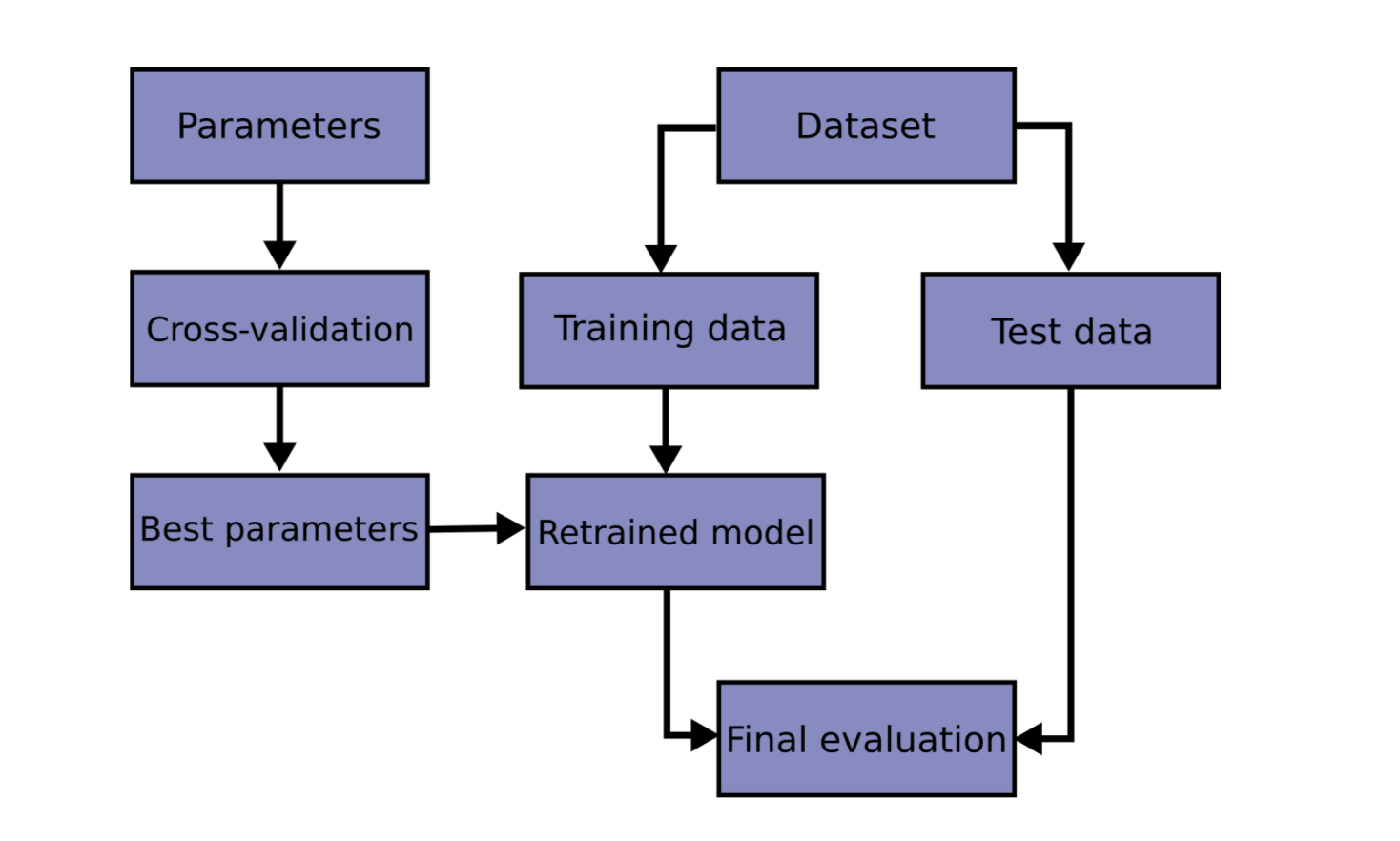
在scikit-learn中,随机切分数据集为训练集和测试集可以使用train_test_split帮助函数。
如:使用莺尾花数据集(iris data)拟合一个线性支持向量机模型。
>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> from sklearn import datasets
>>> from sklearn import svm
>>> X, y = datasets.load_iris(return_X_y=True)
>>> X.shape, y.shape
((150, 4), (150,))
使用部分数据来训练模型,并用剩余40%的数据来对模型分类效果进行评估:
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.4, random_state=0)
>>> X_train.shape, y_train.shape
((90, 4), (90,))
>>> X_test.shape, y_test.shape
((60, 4), (60,))
>>> clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.96...
当评估器对不同的模型参数(“超参数”)进行评估时,如参数C是支持向量机的一个超参数,在模型未调整前,仍有过拟合的风险,因为参数的选择决定模型的最佳表现。然而,通过这种方式,测试集中的信息仍有可能会“泄露”到模型中,导致评估指标不能概括模型的评估能力。通过将已知数据集划分一部分为“验证集”可以解决上述问题:在训练数据上对模型进行训练,利用验证集对模型进行评估。当“实验”得到一个较好的成绩时,在测试集上完成模型的最终评估。
但是,当把整个数据集分为上述三个集合时,大大降低可用于建模的数据量。从而,模型的评估结果取决于对训练集和验证集的某种随机划分。
解决上述问题的一个方法是交叉验证(corss-validation,简称CV)。当应用交叉验证的方法时,不再需要划分验证集,而测试集始终应用于模型的最终评估。最基本的交叉验证方法是K折交叉验证(k-fold CV),它是指将训练集划分为k个最小的子集(其它的方法将在下文介绍,当均具有相同的原理)。如下的过程应用k“折叠”中的一个:
将k-1个子集用于模型训练;
用剩余数据验证上一步中建立的模型(类似于利用测试集计算模型的准确率)。
模型表现是由k折交叉验证的结果表示的,它是上述步骤循环结果的平均值。这个方法计算成本高,但不会浪费很多数据(如下图每一个例子中,固定一个随机验证集),上述方法在如下问题中,譬如样本数据非常小的反向推演,具有显著优势。
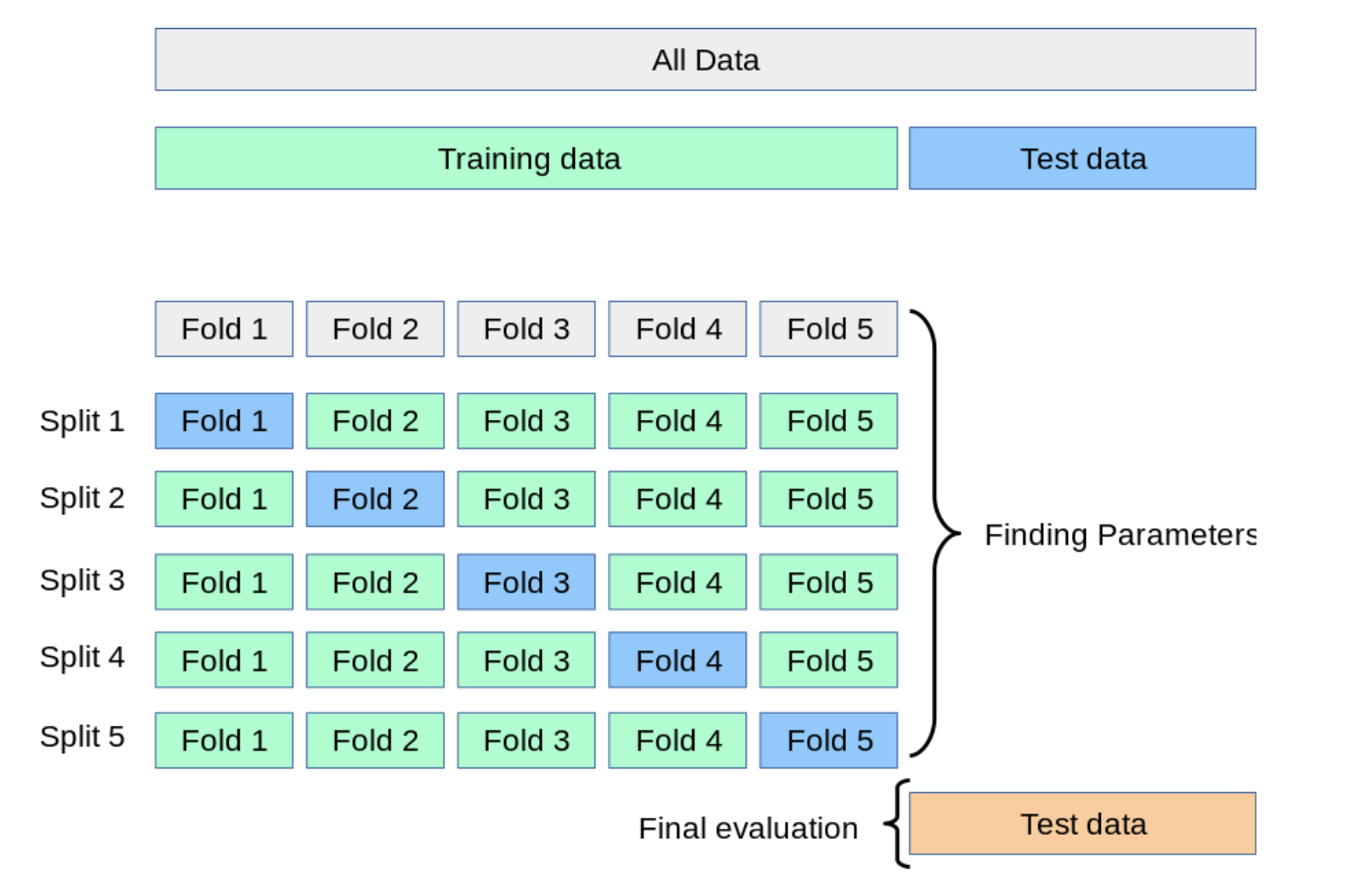
3.1.1 计算交叉验证的指标
在数据集和估计器上应用交叉验证最简单的方法是调用cross_val_score帮助函数。
随后的例子将会说明在莺尾花(iris)数据集上,如何通过划分数据集、训练模型和计算5次交叉验证的得分,从而估计一个线性核支持向量机的准确率(每次使用不同的拆分)。
>>> from sklearn.model_selection import cross_val_score
>>> clf = svm.SVC(kernel='linear', C=1)
>>> scores = cross_val_score(clf, X, y, cv=5)
>>> scores
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
如下是在95%置信区间上的平均得分为:
>>> print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
Accuracy: 0.98 (+/- 0.03)
默认的交叉验证迭代的输出结果是参数为score的估计器,通过修改scoring的参数可以修改估计器:
>>> from sklearn import metrics
>>> scores = cross_val_score(
... clf, X, y, cv=5, scoring='f1_macro')
>>> scores
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
参见 The scoring parameter: defining model evaluation。在上述莺尾花数据集(Iris dataset)的例子中,样本标签是均衡的,因此计算的准确率和F1-score几乎相等。
当参数cv是一个整数时,cross_val_score的初始参数为KFold或StratifiedKFold,当模型的估计器来自于ClassifierMixin时,使用后一种参数。
也可以通过传入交叉验证迭代器,来使用交叉验证的策略对模型进行评估,如:
>>> from sklearn.model_selection import ShuffleSplit
>>> n_samples = X.shape[0]
>>> cv = ShuffleSplit(n_splits=5, test_size=0.3, random_state=0)
>>> cross_val_score(clf, X, y, cv=cv)
array([0.977..., 0.977..., 1. ..., 0.955..., 1. ])
另一种选择时使用可迭代的数据集拆分(训练集,测试集)方式作为数组的索引,例如:
>>> def custom_cv_2folds(X):
... n = X.shape[0]
... i = 1
... while i <= 2:
... idx = np.arange(n * (i - 1) / 2, n * i / 2, dtype=int)
... yield idx, idx
... i += 1
...
>>> custom_cv = custom_cv_2folds(X)
>>> cross_val_score(clf, X, y, cv=custom_cv)
array([1. , 0.973...])
使用保留的数据进行数据转化
正如对从训练数据中拆分的数据进行预测评估是重要的,预处理(如标准化、特征选择等)和类似的数据转换同样应从训练集中学习,并应用于剩余的数据以进行预测评估:
>>> from sklearn import preprocessing
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.4, random_state=0)
>>> scaler = preprocessing.StandardScaler().fit(X_train)
>>> X_train_transformed = scaler.transform(X_train)
>>> clf = svm.SVC(C=1).fit(X_train_transformed, y_train)
>>> X_test_transformed = scaler.transform(X_test)
>>> clf.score(X_test_transformed, y_test)
0.9333...
Pipeline库使编写估计器更加容易,在交叉验证下提供这种方法:
>>> from sklearn.pipeline import make_pipeline
>>> clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1))
>>> cross_val_score(clf, X, y, cv=cv)
array([0.977..., 0.933..., 0.955..., 0.933..., 0.977...])
参见 管道和复合估计器。
3.1.1.1 交叉验证函数和多指标评估
cross_validate与cross_val_score存在两方面不同:
它允许制定多个评估指标,
它返回一个字典,包含拟合时间,得分时间(以及可选输出项训练分数和评估器),另外还会输出测试集得分。
对于单一的评估指标,scoring参数是一个字符串类型,可调用的对象或者空值,关键词可能如下:
['test_score', 'fit_time', 'score_time']
而对于多参数评估指标,输入如下关键词将会返回值是一个字典类型:
['test<score1_name>', 'test<score2_name>', 'test_<scorer...>', 'fit_time', 'score_time']
return_train_score的初始值是False,以便节省计算时间。如果需要输出训练集的得分,则需要将参数修改为True。
如果想获得模型在每个训练集上拟合的估计器,则需要设置return_estimator = True。
多个指标的传入可以是列表,元组或预定义的评分器名称:
>>> from sklearn.model_selection import cross_validate
>>> from sklearn.metrics import recall_score
>>> scoring = ['precision_macro', 'recall_macro']
>>> clf = svm.SVC(kernel='linear', C=1, random_state=0)
>>> scores = cross_validate(clf, X, y, scoring=scoring)
>>> sorted(scores.keys())
['fit_time', 'score_time', 'test_precision_macro', 'test_recall_macro']
>>> scores['test_recall_macro']
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])也可以用字典映射一个预定义的评分器或者自定义评分器函数:
>>> from sklearn.metrics import make_scorer
>>> scoring = {'prec_macro': 'precision_macro',
... 'rec_macro': make_scorer(recall_score, average='macro')}
>>> scores = cross_validate(clf, X, y, scoring=scoring,
... cv=5, return_train_score=True)
>>> sorted(scores.keys())
['fit_time', 'score_time', 'test_prec_macro', 'test_rec_macro',
'train_prec_macro', 'train_rec_macro']
>>> scores['train_rec_macro']
array([0.97..., 0.97..., 0.99..., 0.98..., 0.98...])如下是使用单一参数的cross_validate的例子:
>>> scores = cross_validate(clf, X, y,
... scoring='precision_macro', cv=5,
... return_estimator=True)
>>> sorted(scores.keys())
['estimator', 'fit_time', 'score_time', 'test_score']
3.1.1.2 获得交叉验证的预测值
cross_val_predict函数与cross_val_score具有类似的界面,返回的是每一个属于测试集数据的预测值。只有交叉验证的策略允许测试集一次使用所有数据(否则,将会报错)。
警告:不正确使用cross_val_predict的报警
cross_val_predict的结果可能与cross_val_score的结果不同,因为数据会以不同的方式进行分组。cross_val_score函数是交叉验证的平均值,而cross_val_predict仅返回标签(或者标签的概率)来源于不同的输入学习器**(这里的翻译看的知乎https://zhuanlan.zhihu.com/p/90451347)**。 因此,cross_val_predict不是一个适宜的度量泛化误差的方法。
cross_val_predict函数适合的场景如下:
从不同模型中获得预测值的可视化。
模型混合:在集成方法中,当一个有监督估计器的预测值被应用于训练另一个估计器。
随后将介绍可用的交叉验证迭代器。
例子:
3.1.2 交叉验证迭代器
随后的部分列出了一些用于生成索引标号,用于在不同的交叉验证策略中生成数据划分的工具。
3.1.2.1 针对独立同分布数据的交叉验证迭代器
假设一些数据是独立同分布的,假定所有的样本来自于相同的生成过程,并且生成过程假设不基于对过去样本的记忆。
随后的交叉验证会被用于如下的例子。
注意:
尽管独立同分布的数据在机器学习理论中是一个普遍的假设,但它很少存在于实际生活中。假设某样本的生成是一个的过程,那么使用时间序列感知交叉验证方案会更安全。同样的,如果已知样本生成过程具有group structure(团体结构)性质(样本来自于不同的主体,实验和测量工具),就可以更安全的使用group-wise cross-validation。
3.1.2.1.1 K-fold
KFold将所有的样本分为k组,被称为折叠(如果k=n,等价于Leave One Out(留一)策略),每个子样本组的数据量相同(如果可能)。预测函数将会使用k-1个折叠中的数据进行学习,剩余的折叠将会被用于测试。
例如四个样本集的2折交叉验证:
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = ["a", "b", "c", "d"]
>>> kf = KFold(n_splits=2)
>>> for train, test in kf.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[0 1] [2 3]
下图是交叉验证的可视化。注意KFold并不受类别或者组别的影响。
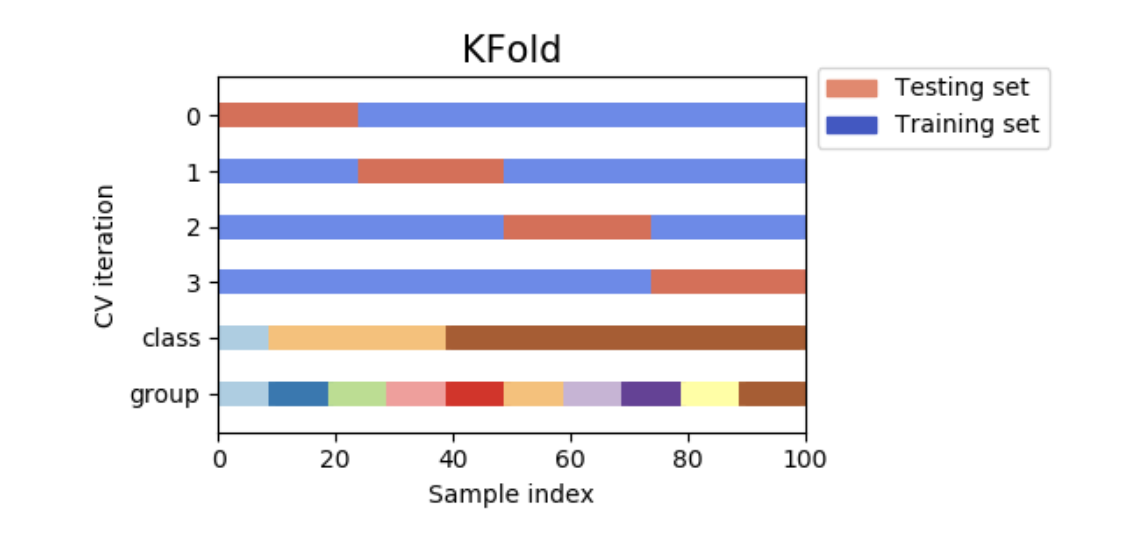 每一个折叠都有两个数组构成:第一个是训练集,第二个是测试集。因此,可以使用numpy索引建立训练/测试集合:
每一个折叠都有两个数组构成:第一个是训练集,第二个是测试集。因此,可以使用numpy索引建立训练/测试集合:
>>> X = np.array([[0., 0.], [1., 1.], [-1., -1.], [2., 2.]])
>>> y = np.array([0, 1, 0, 1])
>>> X_train, X_test, y_train, y_test = X[train], X[test], y[train], y[test]
3.1.2.1.2 重复的K-Fold
RepeatedKFold重复K-Fold n次。该方法可以用于需要执行n次KFold的情形,在每个循环中会生成不同的分组。
2折K-Fold重复2次示例:
>>> import numpy as np
>>> from sklearn.model_selection import RepeatedKFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> random_state = 12883823
>>> rkf = RepeatedKFold(n_splits=2, n_repeats=2, random_state=random_state)
>>> for train, test in rkf.split(X):
... print("%s %s" % (train, test))
...
[2 3] [0 1]
[0 1] [2 3]
[0 2] [1 3]
[1 3] [0 2]
类似的,RepeatedStratifiedKFold是在每个重复中以不同的随机化重复n次分层的K-Fold。
3.1.2.1.3 Leave One Out(LOO)
LeaveOneOut(或LOO)是一个简单的交叉验证。每个学习集都是去除一个样本后的剩余样本,测试集是余下样本。因此,对于n个样本而言,就会有n个不同的训练集和n个不同的测试集。这个交叉验证的过程不会浪费很多数据,因为只有一个数据从训练集中移出。
>>> from sklearn.model_selection import LeaveOneOut
>>> X = [1, 2, 3, 4]
>>> loo = LeaveOneOut()
>>> for train, test in loo.split(X):
... print("%s %s" % (train, test))
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
LOO潜在的用户选择模型应该考虑一些已知警告。当与k-fold交叉验证做比较时,当n>k时,留一法可以从n个样本中构建n个模型,而不是k个模型。进一步,每一个模型都是在n-1个样本上进行训练,而不是在(k-1)n/k。两种方法都假设k不是很大,并且k<n,LOO比k-fold交叉验证的计算成本高。
就正确率而言,LOO经常导致高方差(测试误差的估计器)。直观地说,因为用n个样本的n-1个样本构建模型,由折叠构建的模型实际上是相同的,且相同于由整个数据集构建的模型。
但是,如果学习曲线相对于训练集的大小是陡峭的,那么5-或者10-折交叉验证会高估模型的泛化误差。
作为通用规则,大多数作者,及实际经验表明,5-或者10-交叉验证会优于LOO。
参考文献:
http://www.faqs.org/faqs/ai-faq/neural-nets/part3/section-12.html; T. Hastie, R. Tibshirani, J. Friedman, The Elements of Statistical Learning, Springer 2009 L. Breiman, P. Spector Submodel selection and evaluation in regression: The X-random case, International Statistical Review 1992; R. Kohavi, A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection, Intl. Jnt. Conf. AI R. Bharat Rao, G. Fung, R. Rosales, On the Dangers of Cross-Validation. An Experimental Evaluation, SIAM 2008; G. James, D. Witten, T. Hastie, R Tibshirani, An Introduction to Statistical Learning, Springer 2013.
3.1.2.1.4 Leave P Out(LPO)
LeavePOut与LeaveOneOut相类似,因为它通过从整个数据集中,删除p个样本点来创建所有可能的训练集/测试集。对于n个样本量,它产生了种训练-测试组合。与LeaveOneOut和KFold不同的是,当p>1时,测试集将会重叠。
在只有四个样本的数据集上使用Leave-2-Out示例:
>>> from sklearn.model_selection import LeavePOut
>>> X = np.ones(4)
>>> lpo = LeavePOut(p=2)
>>> for train, test in lpo.split(X):
... print("%s %s" % (train, test))
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3]
3.1.2.1.5 随机排列交叉验证a.k.a. Shuffle & Split:
ShuffleSplit迭代器会产生一个由用户定义数值,独立的训练集/测试集划分。样本首先被打乱,然后划分为训练集和测试集的组合。
通过设置种子random_state伪随机数发生器,可以再现随机切分数据集的结果。
以下是使用示例:
>>> from sklearn.model_selection import ShuffleSplit
>>> X = np.arange(10)
>>> ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state=0)
>>> for train_index, test_index in ss.split(X):
... print("%s %s" % (train_index, test_index))
[9 1 6 7 3 0 5] [2 8 4]
[2 9 8 0 6 7 4] [3 5 1]
[4 5 1 0 6 9 7] [2 3 8]
[2 7 5 8 0 3 4] [6 1 9]
[4 1 0 6 8 9 3] [5 2 7]
下图是交叉验证原理的可视化。注意ShuffleSplit不受类别或组的影响。
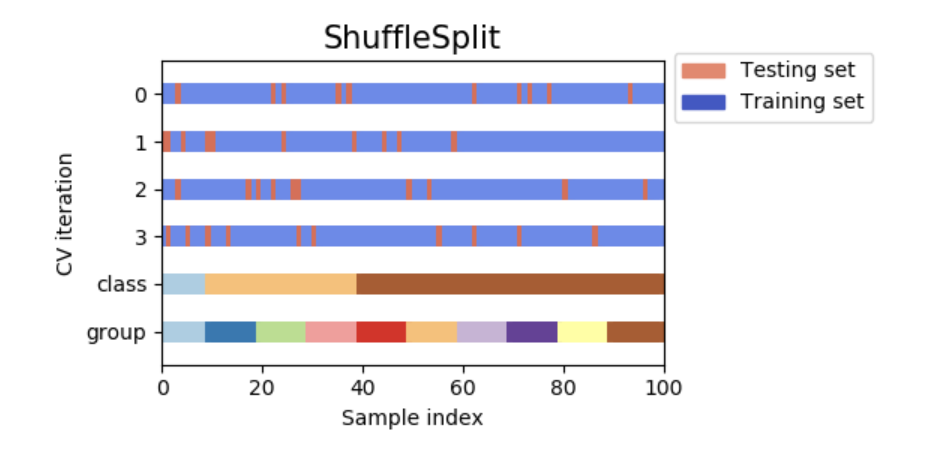 ShuffleSplit是KFold交叉验证好的替代选择,它允许数量或比例控制训练/测试集的划分方式。
ShuffleSplit是KFold交叉验证好的替代选择,它允许数量或比例控制训练/测试集的划分方式。
3.1.2.2 基于类标签的层化交叉验证迭代器
一些分类问题会表现出极大不均衡的样本类别分布:例如正样本是负样本的许多倍。在一些案例中,推荐使用分层抽样的方法,以确保相关类别的频率在训练集和验证折叠中大致一致,可以用StratifiedKFold和StratifiedShuffleSplit实现。
3.1.2.2.1 分层k折
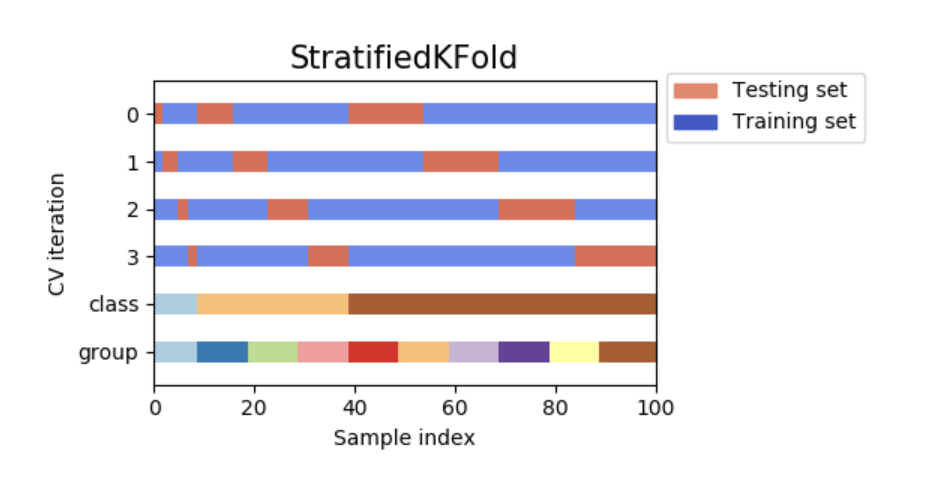
StratifiedKFold是k-fold的变种,它返回分层的折叠:每个集合的标签分布比例与整个数据集几乎相同。
如下是一个在包含50个样本,分为两类别的不平衡数据集上,进行3折交叉验证的例子。该例子将展示每个类别的样本量,并与KFold进行比较。
>>> from sklearn.model_selection import StratifiedKFold, KFold
>>> import numpy as np
>>> X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5))
>>> skf = StratifiedKFold(n_splits=3)
>>> for train, test in skf.split(X, y):
... print('train - {} | test - {}'.format(
... np.bincount(y[train]), np.bincount(y[test])))
train - [30 3] | test - [15 2]
train - [30 3] | test - [15 2]
train - [30 4] | test - [15 1]
>>> kf = KFold(n_splits=3)
>>> for train, test in kf.split(X, y):
... print('train - {} | test - {}'.format(
... np.bincount(y[train]), np.bincount(y[test])))
train - [28 5] | test - [17]
train - [28 5] | test - [17]
train - [34] | test - [11 5]
StratifiedKFold在训练集和测试集中保存了各类别的相同比例(大约1/10)。
下图是交叉验证原理的可视化。
 RepeatedStratifiedKFold可以在每一次循环中,重复n次不同随机选择的分层k折。
RepeatedStratifiedKFold可以在每一次循环中,重复n次不同随机选择的分层k折。
3.1.2.2.2 分层的随机拆分
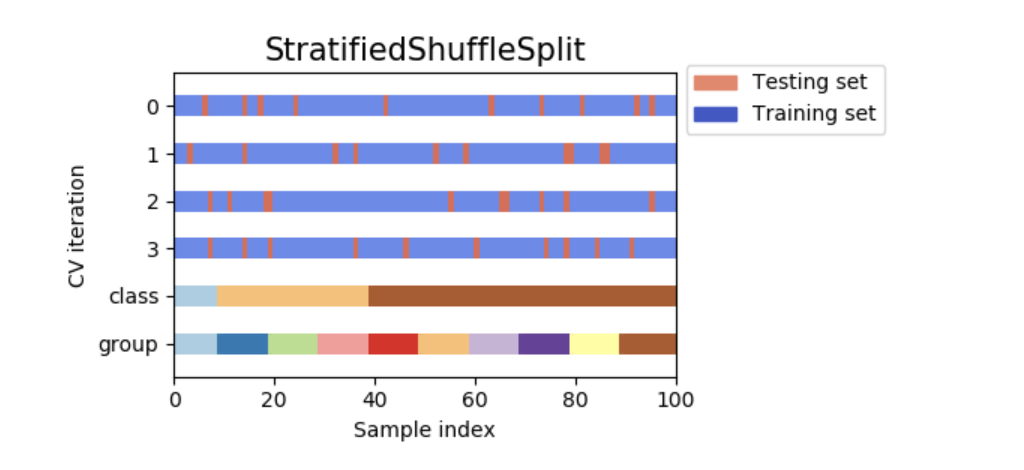
StratifiedShuffleSplit是shuffleSplit的变种,它返回分层的样本拆分,例如在拆分的各数据集中,保留与整个样本数据集相同的样本比例。
下图为交叉验证原理的可视化。
3.1.2.3 分组数据的交叉验证迭代器
如潜在的样本生成过程生成非独立的样本组,则独立同分布的假设将不适用。
这样的样本分组是应用于特定领域的。如下是一个从不同病人处收集的医学数据,每一位患者提供多个样本。并且这些数据很可能依赖于各自的组。在这个例子中,每个样本的患者id是其组标识符。
上述案例中,在特定组上训练的模型,是否能很好的概括看不见的组将是关注重点。为了衡量它,需要确保验证集中的所有样本不会在与之配对的训练折叠中出现。
在随后的交叉验证数据划分可以实现上述功能。样本中的组标识将通过groups参数进行定义。
3.1.2.3.1 组k折
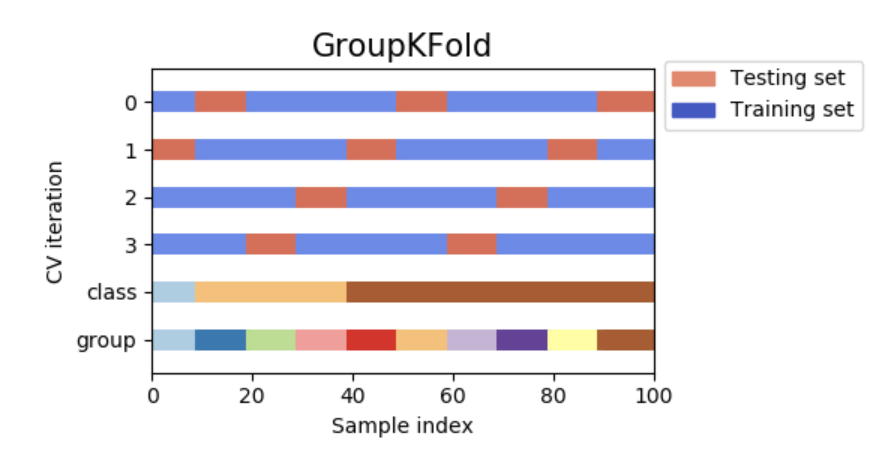
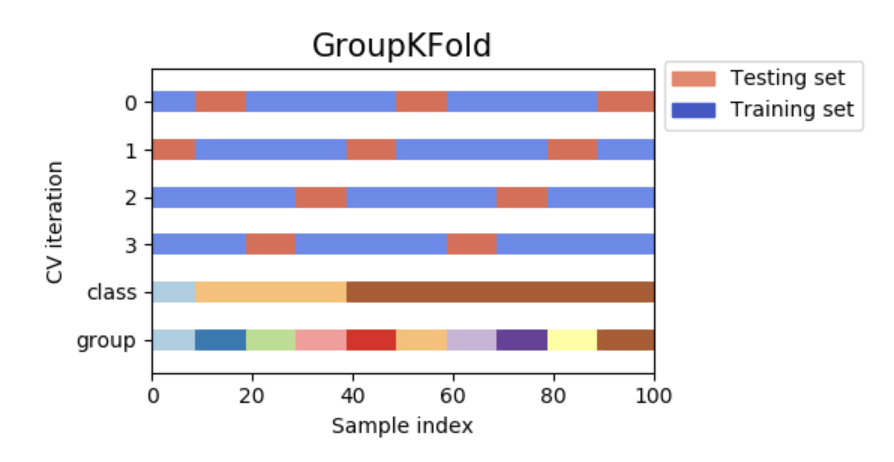
GroupKFold是k折的一个变种,它确保相同的组不会同时出现在测试集和训练集中。例如,如果数据来自不同的受试者,且每个受试者提供多个样本,同时,如果模型可以灵活学习高度具体化的特征,它就不能概括其它受试者的特征。GroupKFold方法使模型可以察觉到上述过拟合情形。
假设有三个受试者,每个受试者都有一个从1到3的关联数字:
>>> from sklearn.model_selection import GroupKFold
>>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
>>> y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
>>> groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
>>> gkf = GroupKFold(n_splits=3)
>>> for train, test in gkf.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]
每个受试者在不同的测试折中,相同的受试者不会同时出现在测试集和训练集中。需要注意的是,由于数据的不均衡问题,每个折叠含有不同的数据量。
下图是交叉验证原理的可视化。
3.1.2.3.2 留一组交叉验证
LeaveOneGroupOut是一个交叉验证方案,它根据第三方提供的整数组的数组来提供样本。这个组信息可用于编码任意域特定的预定义交叉验证折叠。
每一个训练集包含除特定组以外的所有样本。
在多次实验的例子中,LeaveOneGroupOut可以建立一个基于不同实验的交叉验证:创建一个除某一实验样本外的所有实验样本的训练集:
>>> from sklearn.model_selection import LeaveOneGroupOut
>>> X = [1, 5, 10, 50, 60, 70, 80]
>>> y = [0, 1, 1, 2, 2, 2, 2]
>>> groups = [1, 1, 2, 2, 3, 3, 3]
>>> logo = LeaveOneGroupOut()
>>> for train, test in logo.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[2 3 4 5 6] [0 1]
[0 1 4 5 6] [2 3]
[0 1 2 3] [4 5 6]
另外一个常见应用是使用时间信息:例如,组可以是收集样本的年份,从而允许对基于时间的拆分进行交叉验证。
3.1.2.3.3 留P组交叉验证
 对于训练/测试集而言,LeaveGroupOut与LeaveOneGroupOut相类似,但移除与P组相关的数据。
对于训练/测试集而言,LeaveGroupOut与LeaveOneGroupOut相类似,但移除与P组相关的数据。
留2组交叉验证的例子:
>>> from sklearn.model_selection import LeavePGroupsOut
>>> X = np.arange(6)
>>> y = [1, 1, 1, 2, 2, 2]
>>> groups = [1, 1, 2, 2, 3, 3]
>>> lpgo = LeavePGroupsOut(n_groups=2)
>>> for train, test in lpgo.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[4 5] [0 1 2 3]
[2 3] [0 1 4 5]
[0 1] [2 3 4 5]
3.1.2.3.4 组乱序分割(Group Shuffle Split)
GroupShuffleSplit迭代器表现为ShuffleSplit和LeavePGroupsOut的结合,并生成一个随机分区的序列,并为每一个分组提供一个组子集。
如下示例:
>>> from sklearn.model_selection import GroupShuffleSplit
>>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 0.001]
>>> y = ["a", "b", "b", "b", "c", "c", "c", "a"]
>>> groups = [1, 1, 2, 2, 3, 3, 4, 4]
>>> gss = GroupShuffleSplit(n_splits=4, test_size=0.5, random_state=0)
>>> for train, test in gss.split(X, y, groups=groups):
... print("%s %s" % (train, test))
...
[0 1 2 3] [4 5 6 7]
[2 3 6 7] [0 1 4 5]
[2 3 4 5] [0 1 6 7]
[4 5 6 7] [0 1 2 3]
交叉验证原理的可视化:
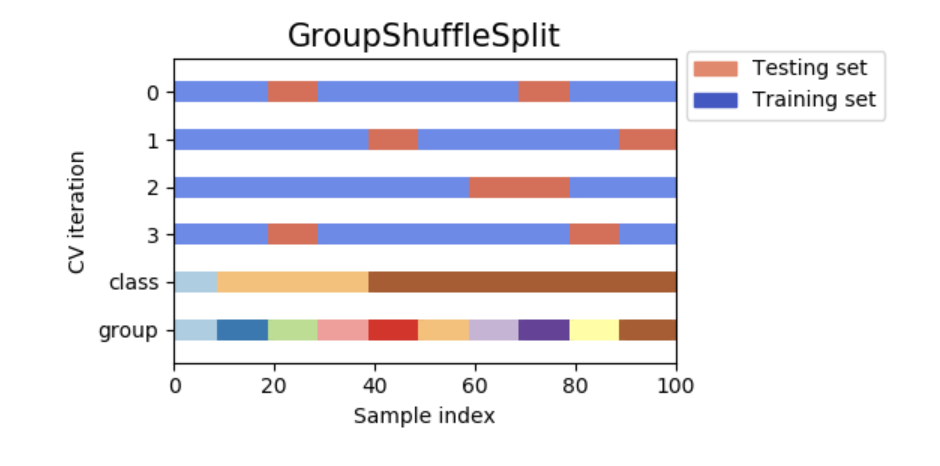 当需要LeavePGroupsOut的功能时,这个分类非常有用,但是当组的个数足够大时,保留P组的分区成本将很高。在这种情形中,GroupShuffleSplit通过LeavePGroupsOut提供一个随机(可重复)的训练/测试集划分。
当需要LeavePGroupsOut的功能时,这个分类非常有用,但是当组的个数足够大时,保留P组的分区成本将很高。在这种情形中,GroupShuffleSplit通过LeavePGroupsOut提供一个随机(可重复)的训练/测试集划分。
3.1.2.4 预定义的折叠/验证集
对于一些数据集,一个预定义的数据集划分训练-和验证折叠或一些交叉验证折叠已经存在。例如当需要搜索超参数时,可以使用PredefinedSplit来使用这些折叠。
例如,当使用验证集时,设置所有样本的test_fold为0,以将其归为验证集。并设置剩余样本得到该参数为-1。
3.1.2.5 时间序列数据的交叉验证
时间序列数据的特点是观测值间的相关性与时间趋势相关(自相关)。但是,传统的交叉验证技术例如KFold和ShuffleSplit均假定样本的独立同分布,并且会造成训练集和测试集间难以解释的相关性(估计出较差的泛化误差)在时间序列的数据集中。因此,评估模型对观测“未来”值的时间序列数据至关重要,而不仅是用于训练模型。为了完成这个目标,可以使用TimeSeriesSplit。
3.1.2.5.1 时间序列划分
TimeSeriesSplit是一个k-fold变种,它返回前k折作为训练集,同时第(k+1)折作为测试集。需要注意的是,与标准的交叉验证法不同,连续的训练集是前面数据集的超集。并且,会将多余的数据放到用于训练模型的第一个训练分区。
这些分类可被用于固定时间被观测的交叉验证时间序列数据样本。
例如在6个样本上进行3-split 时间序列交叉验证:
>>> from sklearn.model_selection import TimeSeriesSplit
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4, 5, 6])
>>> tscv = TimeSeriesSplit(n_splits=3)
>>> print(tscv)
TimeSeriesSplit(max_train_size=None, n_splits=3)
>>> for train, test in tscv.split(X):
... print("%s %s" % (train, test))
[0 1 2] [3]
[0 1 2 3] [4]
[0 1 2 3 4] [5]
交叉验证原理可视化如下所示:
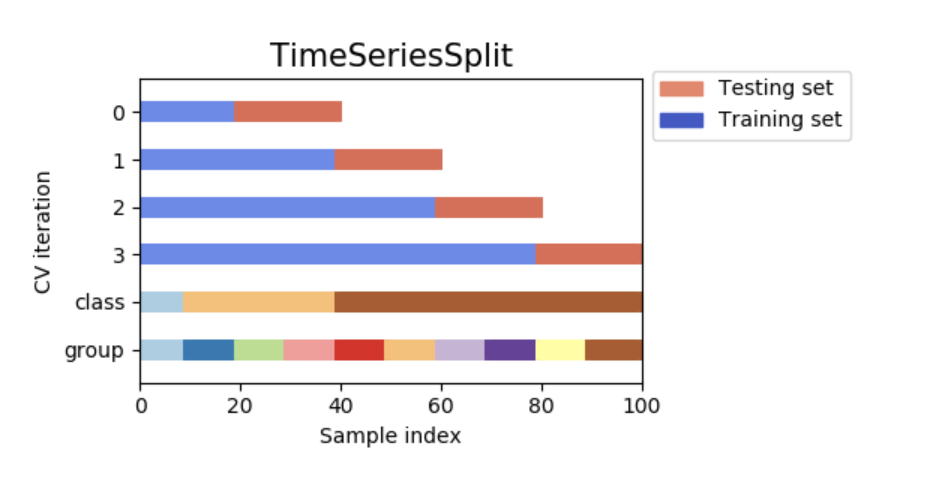
3.1.3 shuffling的注意事项
如果数据的顺序不是随机的(例如具有相同类别标签的样本连在一起),先把数据打乱对于获得有价值的交叉验证结果是有意义的。但是,如果样本不是独立同分布的,则结果可能相反。例如,如果样本数据是关于“文章发表”的,并且发表时间符合时间序列,则打乱数据会导致模型过拟合及过高的验证集分数:这是人为导致训练集与验证集相类似(时间趋势相似)的结果。
一些交叉验证迭代器具有内置选项在拆分数据集前打乱数据索引。注意:
相比直接打乱数据,它消耗更少内存。 初始化是不打乱数据,包括:通过给cross_val_score,网格搜索等定义cv=some_integer来执行(分层的)K折交叉验证。但train_test_split会返回一个随机划分。 random_state参数的初始值是None,意味着KFold(..., shuffle = True)每次迭代的结果不同。但是GridSearchCV调用fit方法,对同一组参数使用相同的打乱方式。 如想获取相同的拆分结果,需设置random_state为整数。
3.1.4 交叉验证和模型选择
交叉验证迭代器也可以直接用于模型选择,如获得模型最佳超参数的网格搜索。下一节的话题是:调整估计器的超参数。

