

谱协聚类算法的一个示例¶
注意 单击此处下载完整的示例代码,或通过Binder在浏览器中运行此示例
有关列子在模块sklearn.cluster.biclusterh中。
此示例演示如何使用谱协聚类算法(pectral Co-Clustering algorithm)生成数据集和双光泽数据集。
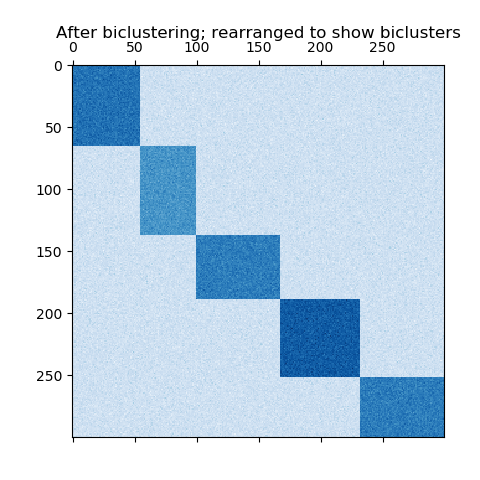
数据集是使用make_biluster函数生成的,该函数创建一个小值矩阵和具有较大值的集群。然后对行和列进行洗牌,并将其传递给谱协聚类算法。重新排列洗牌矩阵,使集群连续显示,该算法明确的表明地找到了集群。

# 输出
# consensus score: 1.000
print(__doc__)
# Author: Kemal Eren <kemal@kemaleren.com>
# License: BSD 3 clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_biclusters
from sklearn.cluster import SpectralCoclustering
from sklearn.metrics import consensus_score
data, rows, columns = make_biclusters(
shape=(300, 300), n_clusters=5, noise=5,
shuffle=False, random_state=0)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
# shuffle clusters
rng = np.random.RandomState(0)
row_idx = rng.permutation(data.shape[0])
col_idx = rng.permutation(data.shape[1])
data = data[row_idx][:, col_idx]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
model = SpectralCoclustering(n_clusters=5, random_state=0)
model.fit(data)
score = consensus_score(model.biclusters_,
(rows[:, row_idx], columns[:, col_idx]))
print("consensus score: {:.3f}".format(score))
fit_data = data[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]
plt.matshow(fit_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
plt.show()
脚本的总运行时间:(0分钟0.292秒)

