

Search
Please activate JavaScript to enable the search functionality.
From here you can search these documents. Enter your search words into the box below and click "search". Note that the search function will automatically search for all of the words. Pages containing fewer words won't appear in the result list.
Search Results
Search finished, found 840 page(s) matching the search query.
-
6.4 缺失值插补
由于各种原因,现实世界的许多数据集包含缺失值,通常将其编码为空白,NaN或其他占位符。但是,此类数据集与scikit-learn估计器不兼容,后者假定数组中的所有值都是具有含义的数字。使用不完整数据集
-
二维点云上的FastICA
此示例在特征空间中用两种不同的成分分析技术直观地说明了通过结果进行比较的方法。 [Independent component analysis (ICA)](https://scikit-learn
-
梯度提升的提前停止
梯度提升是一种集成技术,将几个弱学习者(回归树)组合在一起,以迭代的方式生成一个强大的单一模型。 梯度提升中的早期停止支持使我们能够找到最小的迭代次数,这足以建立一个可以很好地推广到未知数据的模型。
-
股市结构可视化
此示例使用几种无监督学习技术从历史报价的变化中提取股票市场结构。 我们使用的数量是报价的每日变动:有关联的报价往往在一天内波动。 ## 学习一个图结构 我们使用稀疏逆协方差估计来找出哪些报价是有
-
F检验与互换信息法的比较
此示例说明了单变量F检验统计量与互换信息法之间的差异。 我们考虑三个特征x_1,x_2,x_3均匀分布在[0,1]上,目标变量依赖于它们: y = x_1 + sin(6 * pi * x
-
高斯混合模型的密度估计
绘制两个高斯混合体的密度估计图。数据由两个具有不同中心和协方差矩阵的高斯产生。 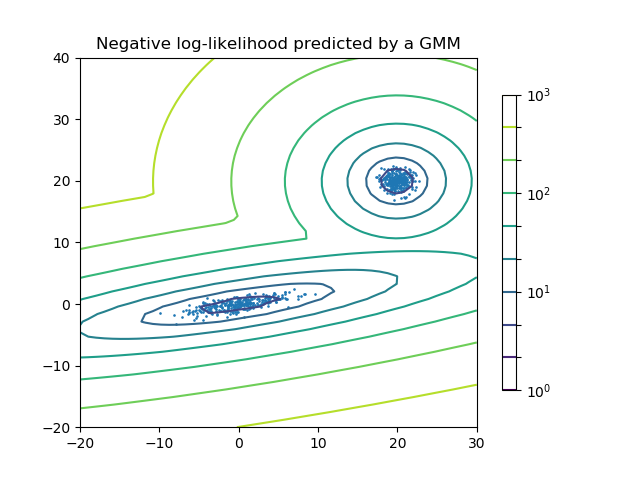 ```pyt
-
高斯过程分类的等概率线(GPC)
一个二维分类示例,显示了预测概率的等概率线。 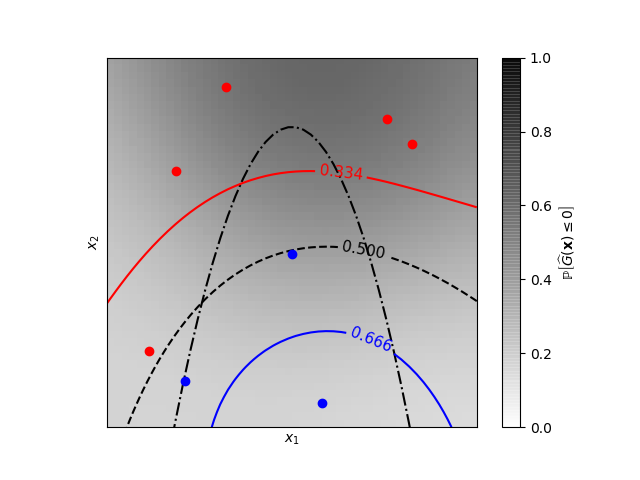 ```python Learned kern
-
贝叶斯岭回归
在合成数据集上计算贝叶斯岭回归。 有关回归的更多信息,请参见[贝叶斯岭回归](https://scikit-learn.org.cn/view/4.html#1.1.10%20%E8%B4%9D%E
-
带LLE的Swiss Roll降低
一种局部线性嵌入的Swiss Roll降低的图解如下: 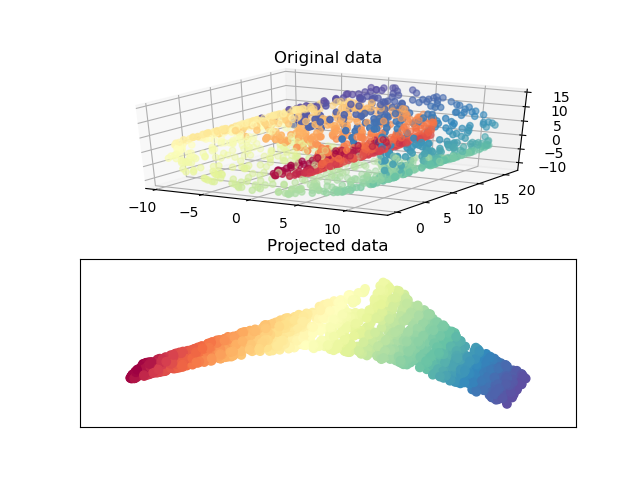 ```python Computi
-
使用多输出估算器完成人脸绘制
本示例说明了使用多输出估算器来完成图像。目标是根据给定脸部的上半部分来预测其下半部分。 图像的第一列显示真实面孔。下几列说明了极端随机树,k近邻,线性回归和岭回归如何完成这些面孔的下半部分。
-
用于文本特征提取和评估的示例管道
在本案例中使用的数据集是20个新闻组数据集,这些数据集将自动下载,然后缓存并重新用于文档分类示例。 您可以通过将类别的名称提供给数据集加载器或将其设置为None来获得20个类别来调整类别的数量。
-
具有局部离群因子(LOF)的新颖性检测
局部离群因子(LOF)算法是一种无监督的异常检测方法,可计算给定数据点相对于其邻居的局部密度偏差。它认为密度远低于其邻居的样本为异常值。本示例说明如何使用LOF进行新颖性检测。请注意,将LOF用于新颖
-
串联多个特征提取方法
在许多实际示例中,有很多方法可以从数据集中提取要素。 通常,结合几种方法以获得良好的性能是有益的。 本示例说明如何使用FeatureUnion组合通过PCA和单变量选择获得的特征。 使用该转换器
-
使用KBinsDiscretizer离散化连续特征
该示例比较了带有或不带有离散化实值特征的线性回归(线性模型)和决策树(基于树的模型)的预测结果。 如离散化之前的结果所示,线性模型的建立速度很快,解释起来也相对简单,但是只能建模线性关系,而决策
-
支持向量机的边际
下图显示了参数C对分隔线的影响。 设置较大的C值相当于告诉我们的模型,我们对数据的分布没有太大的信心,只会考虑更接近分隔线的点。 较小的C值包含更多/所有观察值,从而可以使用该区域中的所有数据来

