

使用KBinsDiscretizer离散化连续特征¶
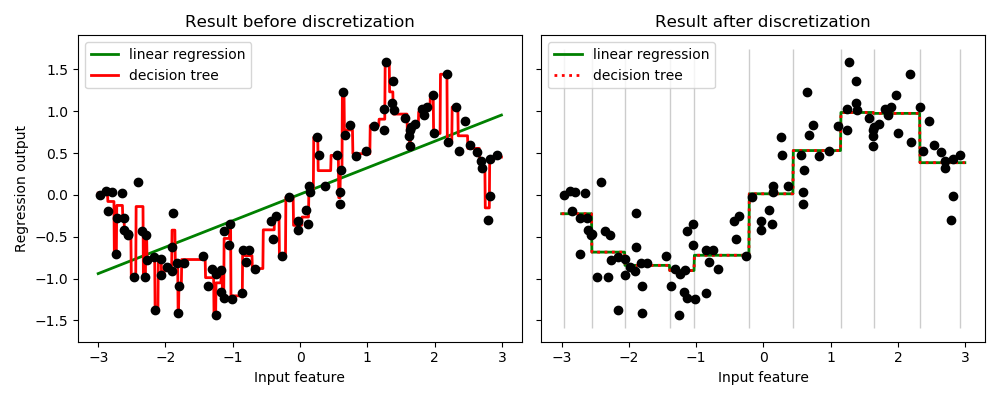
该示例比较了带有或不带有离散化实值特征的线性回归(线性模型)和决策树(基于树的模型)的预测结果。
如离散化之前的结果所示,线性模型的建立速度很快,解释起来也相对简单,但是只能建模线性关系,而决策树则可以构建更为复杂的数据模型。使线性模型在连续数据上更强大的一种方法是使用离散化(也称为分箱)。在示例中,我们离散化了特征,并对转换后的数据进行了一次热编码。请注意,如果分箱的宽度不太合理,则过拟合的风险似乎会大大增加,因此通常应在交叉验证下调整离散器参数。
离散化之后,线性回归和决策树做出完全相同的预测。由于每个分箱仓中的要素都是恒定的,因此任何模型都必须为仓中的所有点预测相同的值。与离散化之前的结果相比,线性模型变得更加灵活,而决策树的灵活性则大大降低。请注意,合并功能通常不会对基于树的模型产生任何有益影响,因为这些模型可以学习将数据拆分到任何地方。
# 作者: Andreas Müller
# Hanmin Qin <qinhanmin2005@sina.com>
# 执照: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.tree import DecisionTreeRegressor
print(__doc__)
# 构建数据集
rnd = np.random.RandomState(42)
X = rnd.uniform(-3, 3, size=100)
y = np.sin(X) + rnd.normal(size=len(X)) / 3
X = X.reshape(-1, 1)
# 用KBinsDiscretizer转换数据集
enc = KBinsDiscretizer(n_bins=10, encode='onehot')
X_binned = enc.fit_transform(X)
# 用原始数据集进行预测
fig, (ax1, ax2) = plt.subplots(ncols=2, sharey=True, figsize=(10, 4))
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
reg = LinearRegression().fit(X, y)
ax1.plot(line, reg.predict(line), linewidth=2, color='green',
label="linear regression")
reg = DecisionTreeRegressor(min_samples_split=3, random_state=0).fit(X, y)
ax1.plot(line, reg.predict(line), linewidth=2, color='red',
label="decision tree")
ax1.plot(X[:, 0], y, 'o', c='k')
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
# 用转换后的数据进行预测
line_binned = enc.transform(line)
reg = LinearRegression().fit(X_binned, y)
ax2.plot(line, reg.predict(line_binned), linewidth=2, color='green',
linestyle='-', label='linear regression')
reg = DecisionTreeRegressor(min_samples_split=3,
random_state=0).fit(X_binned, y)
ax2.plot(line, reg.predict(line_binned), linewidth=2, color='red',
linestyle=':', label='decision tree')
ax2.plot(X[:, 0], y, 'o', c='k')
ax2.vlines(enc.bin_edges_[0], *plt.gca().get_ylim(), linewidth=1, alpha=.2)
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()
输出:
 脚本的总运行时间:(0分钟0.203秒)
脚本的总运行时间:(0分钟0.203秒)

