sklearn.preprocessing.QuantileTransformer¶
class sklearn.preprocessing.QuantileTransformer(*, n_quantiles=1000, output_distribution='uniform', ignore_implicit_zeros=False, subsample=100000, random_state=None, copy=True)
使用分位数信息变换特征。
此方法将要素转换为遵循均匀或正态分布。因此,对于给定的特征,此变换趋向于散布最频繁的值。它还减少了(边际)离群值的影响:因此,这是一个可靠的预处理方案。
变换独立应用于每个功能。首先,特征的累积分布函数的估计值用于将原始值映射到均匀分布。然后使用关联的分位数函数将获得的值映射到所需的输出分布。低于或高于拟合范围的新数据/看不见数据的特征值将映射到输出分布的边界。请注意,此变换是非线性的。它可能会扭曲以相同比例尺测量的变量之间的线性相关性,但会使以不同比例尺测量的变量更直接可比。
在用户指南中阅读更多内容。
版本0.19中的新功能。
| 参数 | 说明 |
|---|---|
| n_quantiles | int, optional (default=1000 or n_samples) 要计算的分位数。它对应于用来离散化累积分布函数的界标数量。如果n_quantiles大于样本数,则将n_quantiles设置为样本数,因为较大的分位数不能够更好地近似累积分布函数估计量。 |
| output_distribution | str, optional (default=’uniform’) 转换后数据的边际分布。选择是“统一”(默认)或“正常”。 |
| ignore_implicit_zeros | bool, optional (default=False) 仅适用于稀疏矩阵。如果为True,则将丢弃矩阵的稀疏条目以计算分位数统计信息。如果为False,则将这些条目视为零。 |
| subsample | int, optional (default=1e5) 用于估计分位数以提高计算效率的最大样本数。注意,对于值相同的稀疏矩阵和密集矩阵,子采样过程可能有所不同。 |
| random_state | int, RandomState instance or None, optional (default=None) 确定用于二次采样和平滑噪声的随机数生成。请参阅子样本以获取更多详细信息。在多个函数调用之间传递int以获得可重复的结果。见词汇 |
| copy | boolean, optional, (default=True) 设置为False可以执行就地转换并避免复制(如果输入已经是一个numpy数组)。 |
| 属性 | 说明 |
|---|---|
| n_quantiles_ | integer 用于离散化累积分布函数的分位数的实际数量。 |
| quantiles_ | ndarray, shape (n_quantiles, n_features) 这些值对应于参考分位数。 |
| references_ | ndarray, shape(n_quantiles, ) 参考分位数。 |
另见:
没有估算器API的等效函数。
使用幂变换执行到正态分布的映射。
执行更快的标准化,但对异常值的鲁棒性较低。
执行鲁棒的标准化,以消除离群值的影响,但不会使离群值和离群值处于相同的规模。
注释
NaN被视为缺失值:忽略适合度,并保持变换值。
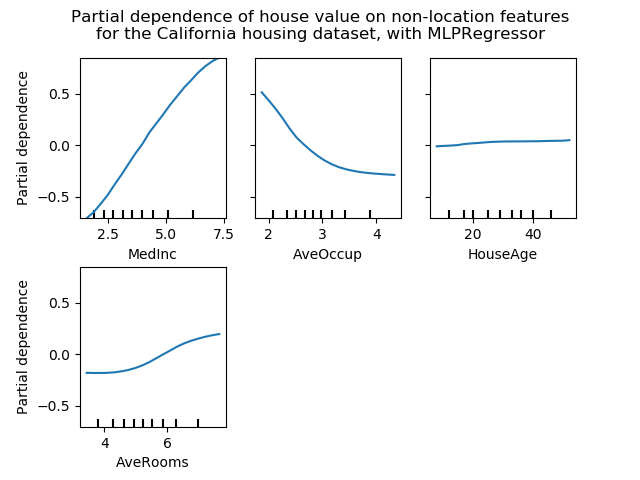
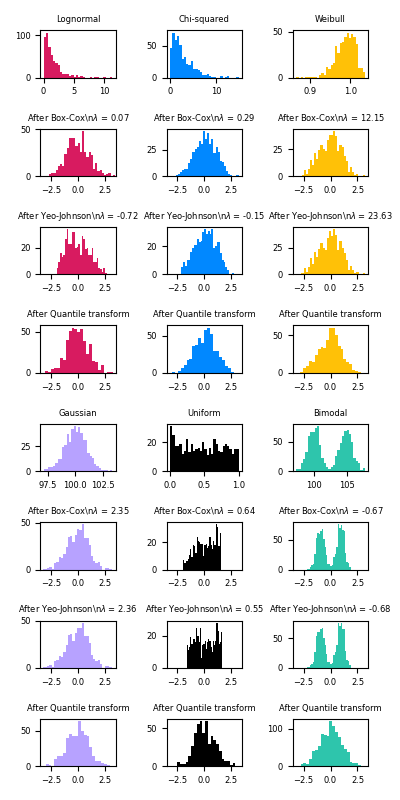
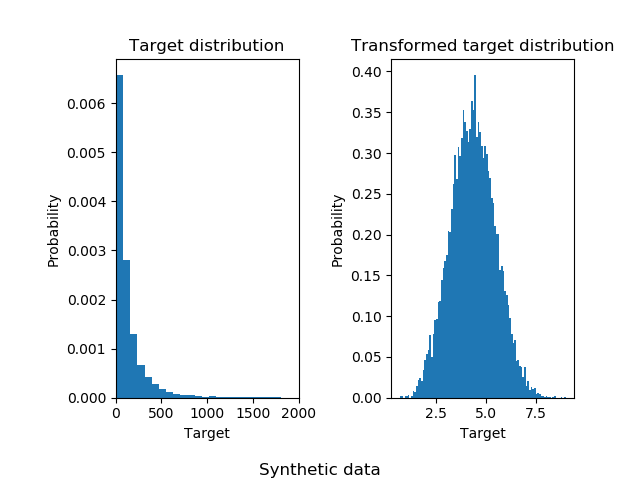
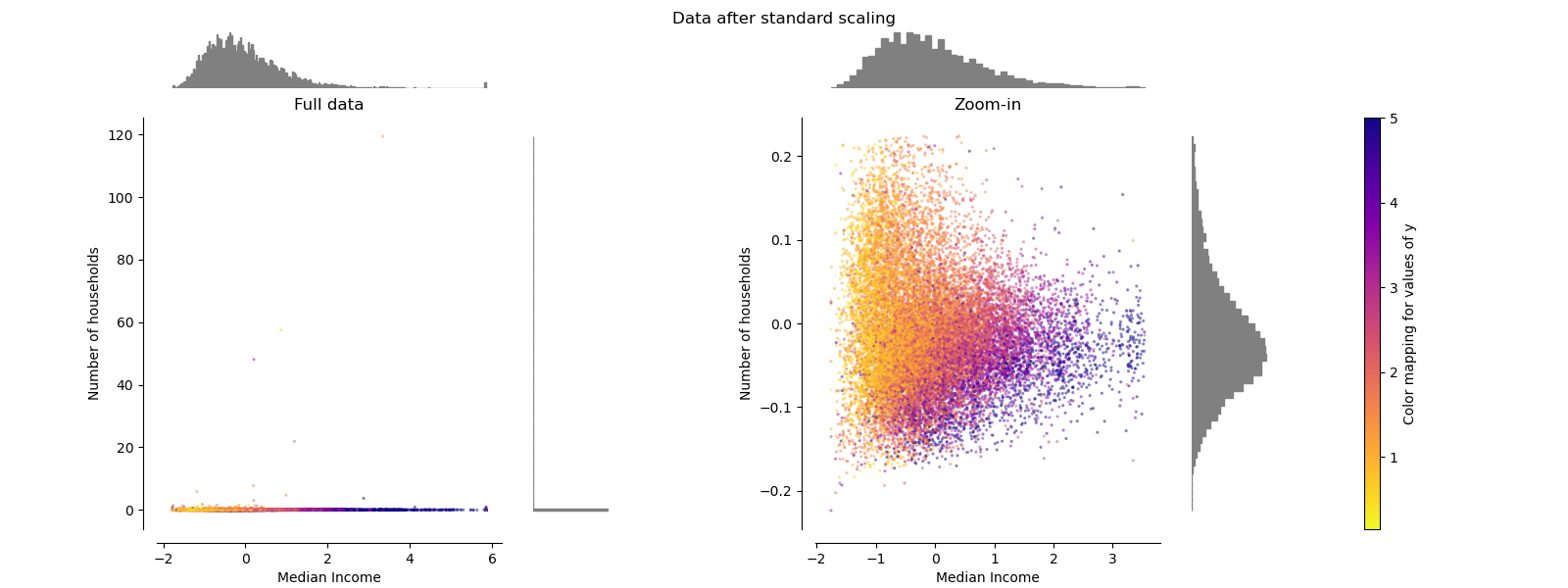
有关不同缩放器,转换器和规范化器的比较,请参阅examples/preprocessing/plot_all_scaling.py。
示例
>>> import numpy as np
>>> from sklearn.preprocessing import QuantileTransformer
>>> rng = np.random.RandomState(0)
>>> X = np.sort(rng.normal(loc=0.5, scale=0.25, size=(25, 1)), axis=0)
>>> qt = QuantileTransformer(n_quantiles=10, random_state=0)
>>> qt.fit_transform(X)
array([...])
方法
| 方法 | 说明 |
|---|---|
fit(X[, y]) |
计算用于转换的分位数。 |
fit_transform(X[, y]) |
拟合数据,然后对其进行转换。 |
get_params([deep]) |
获取此估计量的参数。 |
inverse_transform(X) |
反投影到原始空间。 |
set_params(**params) |
设置此估算器的参数。 |
transform(X) |
数据的按特征进行转换。 |
__init__(*, n_quantiles=1000, output_distribution='uniform', ignore_implicit_zeros=False, subsample=100000, random_state=None, copy=True)
初始化self,有关准确的签名,请参见help(type(self))。
fit(X, y=None)
计算用于转换的分位数。
| 参数 | 说明 |
|---|---|
| X | ndarray or sparse matrix, shape (n_samples, n_features) 用于沿要素轴缩放的数据。如果提供了稀疏矩阵,它将被转换为稀疏csc_matrix。此外,如果ignore_implicit_zeros为False,则稀疏矩阵需要为非负数。 |
| 返回值 | 说明 |
|---|---|
| self | object |
fit_transform(X, y=None, **fit_params)
拟合数据,然后对其进行转换。
使用可选参数fit_params将转换器拟合到X和y,并返回X的转换版本。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix, dataframe} of shape (n_samples, n_features) |
| y | ndarray of shape (n_samples,), default=None 目标值。 |
| **fit_params | dict 其他拟合参数。 |
| 返回值 | 说明 |
|---|---|
| X_new | ndarray array of shape (n_samples, n_features_new) 转换后的数组。 |
get_params(deep=True)
获取此估计量的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估算器和作为估算器的所包含子对象的参数。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名称映射到其值。 |
inverse_transform(X)
反投影到原始空间。
| 参数 | 说明 |
|---|---|
| X | ndarray or sparse matrix, shape (n_samples, n_features) 用于沿要素轴缩放的数据。如果提供了稀疏矩阵,它将被转换为稀疏csc_matrix。此外,如果ignore_implicit_zeros为False,则稀疏矩阵需要为非负数。 |
| 返回值 | 说明 |
|---|---|
| Xt | ndarray or sparse matrix, shape (n_samples, n_features) 投影数据。 |
set_params(**params)
设置此估算器的参数。
该方法适用于简单的估计器以及嵌套对象(例如管道)。后者的参数形式为<component>__<parameter>这样就可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估算器参数。 |
| 返回值 | 说明 |
|---|---|
| self | object 估算器实例。 |
transform(X)
数据的按特征进行转换。
| 参数 | 说明 |
|---|---|
| X | ndarray or sparse matrix, shape (n_samples, n_features) 用于沿要素轴缩放的数据。如果提供了稀疏矩阵,它将被转换为稀疏csc_matrix。此外,如果ignore_implicit_zeros为False,则稀疏矩阵需要为非负数。 |
| 返回值 | 说明 |
|---|---|
| Xt | ndarray or sparse matrix, shape (n_samples, n_features) 投影数据。 |