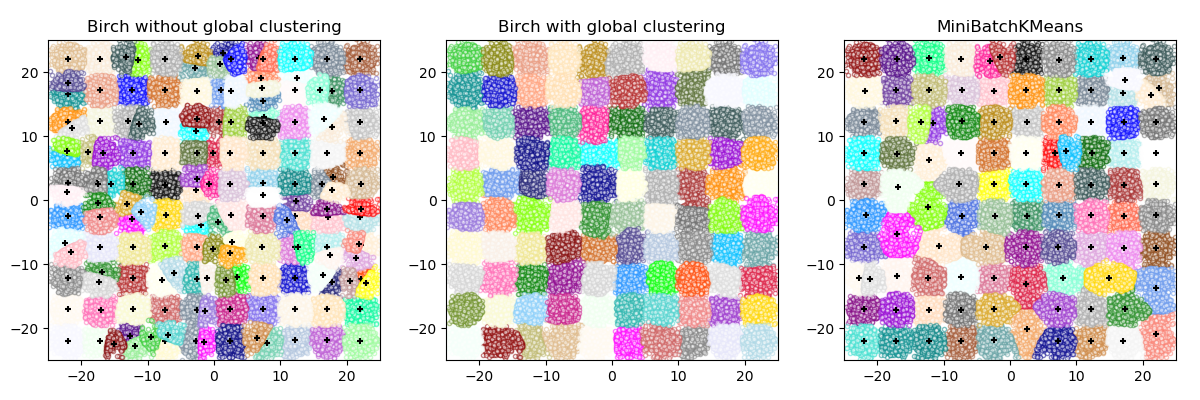
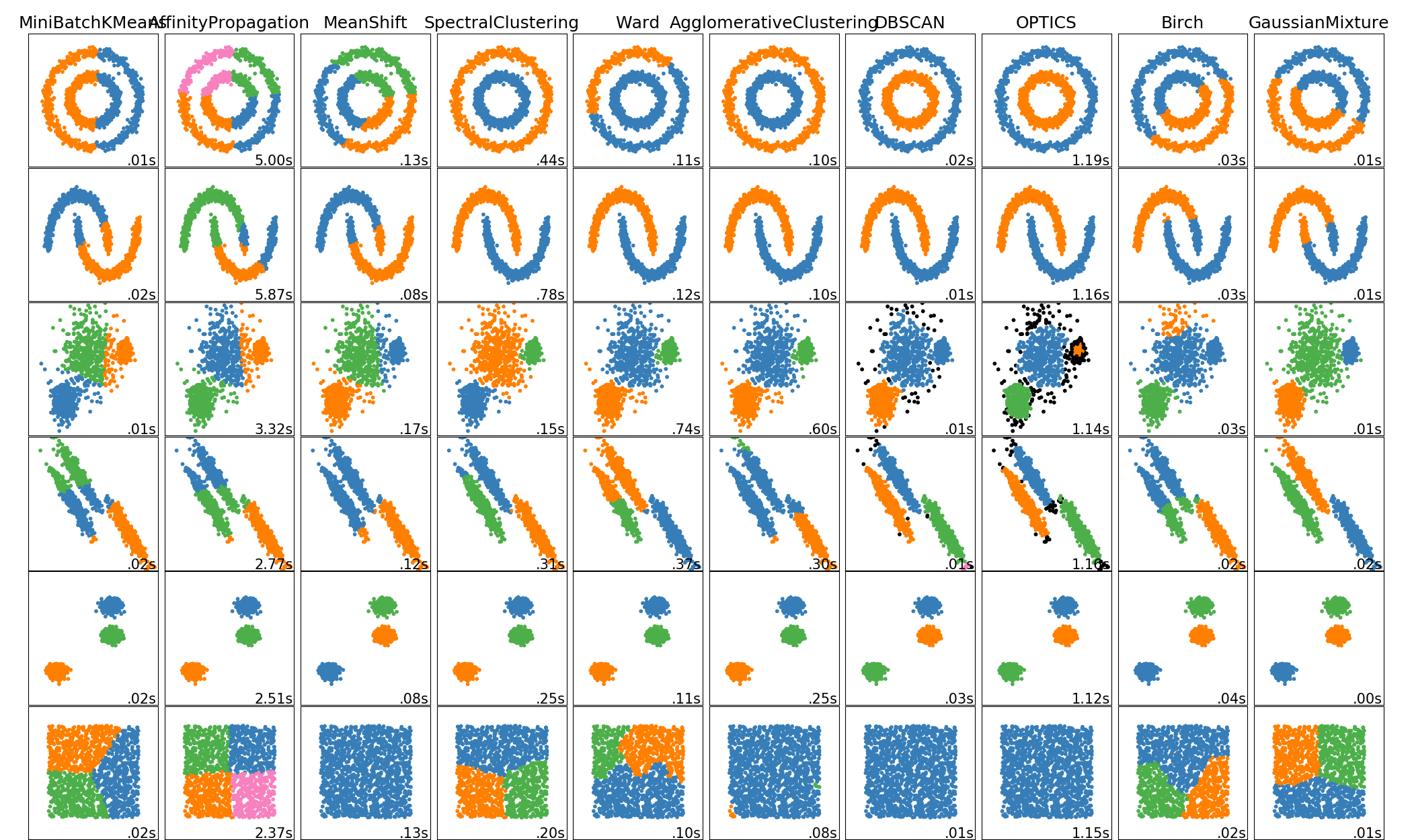
sklearn.cluster.Birch¶
class sklearn.cluster.Birch(*, threshold=0.5, branching_factor=50, n_clusters=3, compute_labels=True, copy=True)
实现Birch聚类算法
它是一种内存高效的在线学习算法,可以替代MiniBatchKMeans。它构造了一个树形数据结构,并从叶子中读取聚类质心。这些可以是最终的聚类质心,也可以作为另一种聚类算法的输入,比如聚类。
在用户指南中阅读更多内容。
New in version 0.16.
| 参数 | 说明 |
|---|---|
| threshold | float, default=0.5 通过合并新样本和最近的子簇获得的子簇的半径应该小于阈值。否则,将启动一个新的子聚类。将此值设置为非常低将促进拆分,反之亦然。 |
| branching_factor | int, default=50 每个节点中CF子聚类的最大数目。如果一个新的样本进入,使得子簇的数目超过分支因子,那么该节点被分成两个节点,每个子簇都重新分布。删除该节点的父聚类,并将两个新的子聚类添加为两个拆分节点的父级。 |
| n_clusters | int, instance of sklearn.cluster model, default=3 最后的聚类步骤之后的簇数,该步骤将叶子中的子簇作为新的样本处理。 - None:不执行最后的聚类步骤,子聚类按原样返回。- sklearn.cluster估计器:如果提供了一个模型,则该模型将子聚类作为新样本处理进行拟合,并将初始数据映射到最近的子聚类的标签上。- int:模型拟合为AgglomerativeClustering,n_clusters设置为整数。 |
| compute_labels | compute_labels 是否为每一次拟合计算标签 |
| copy | bool, default=True 是否复制给定数据。如果设置为False,则将覆盖初始数据。 |
| 属性 | 说明 |
|---|---|
| root_ | _CFNode CF树的根 |
| dummy_leaf_ | _CFNode 启动指向所有叶子的指针 |
| subcluster_centers_ | ndarray 所有子簇的质心直接从叶子中读取 |
| subcluster_labels_ | ndarray 在全局聚类后,分配给子簇的标签。 |
| labels_ | ndarray of shape (n_samples,) 分配给输入数据的标签数组。如果使用partial_fit而不是fit,则将它们分配给最后一批数据。 |
另见:
替代实现,使用小型批处理对中心的位置进行增量更新。
注
树形数据结构由节点组成,每个节点由多个子簇组成。节点中的最大子簇数由分支因子决定。每个子簇保持一个线性和、平方和和以及该子簇中的样本数。此外,如果子簇不是叶节点的成员,则每个子簇也可以有一个节点作为其子节点。
对于进入根的新点,它与最接近根的子簇合并,并更新线性和、平方和和以及该子簇的样本数。这是递归完成的,直到叶节点的属性被更新。
参考
Tian Zhang, Raghu Ramakrishnan, Maron Livny BIRCH: An efficient data clustering method for large databases.https://www.cs.sfu.ca/CourseCentral/459/han/papers/zhang96.pdf
Roberto Perdisci JBirch - Java implementation of BIRCH clustering algorithmhttps://code.google.com/archive/p/jbirch
示例
>>> from sklearn.cluster import Birch
>>> X = [[0, 1], [0.3, 1], [-0.3, 1], [0, -1], [0.3, -1], [-0.3, -1]]
>>> brc = Birch(n_clusters=None)
>>> brc.fit(X)
Birch(n_clusters=None)
>>> brc.predict(X)
array([0, 0, 0, 1, 1, 1])
方法
| 方法 | 说明 |
|---|---|
fit(self, X[, y]) |
为输入数据构建一个CF树。 |
fit_predict(self, X[, y]) |
在X上执行聚类并返回聚类标签 |
fit_transform(self, X[, y]) |
拟合数据,然后转换它。 |
get_params(self[, deep]) |
获取此估计器的参数 |
partial_fit(self[, X, y]) |
在线学习 |
predict(self, X) |
利用子簇的质心预测数据。 |
set_params(self, **params) |
设置此估计器的参数 |
transform(self, X) |
将X变换为子簇质心维数 |
__init__(self, *, threshold=0.5, branching_factor=50, n_clusters=3, compute_labels=True, copy=True)
初始化self。请参阅help(type(self))以获得准确的说明。
fit(self, X, y=None)
为输入数据构建一个CF树。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入数据 |
| y | Ignored 未使用,在此按约定呈现为API一致性。 |
| 返回值 | 说明 |
|---|---|
| self | object 已拟合的估计器 |
fit_predict(self, X, y=None)
在X上执行聚类并返回聚类标签
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) or (n_samples, n_samples) 输入数据 |
| y | Ignored 未使用,在此按约定呈现为API一致性。 |
| 返回值 | 说明 |
|---|---|
| labels | ndarray, shape (n_samples,) 聚类标签 |
fit_transform(self, X, y=None, **fit_params)
拟合数据,然后转换它。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix, dataframe} of shape (n_samples, n_features) |
| y | ndarray of shape (n_samples,), default=None 目标值 |
| 返回值 | 说明 |
|---|---|
| **fit_params | dict 转换后的数组 |
get_params(self, deep=True)
获取此估计器的参数
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估计器的参数和所包含的作为估计量的子对象。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 映射到其值的参数名称 |
partial_fit(self, X=None, y=None)
在线学习。防止CFTree从头开始重建
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入数据。如果没有提供X,则只执行全局聚类步骤。 |
| y | Ignored 未使用,在此按约定呈现为API一致性。 |
| 返回值 | 说明 |
|---|---|
| self | object 已拟合的估计器 |
predict(self, X)
利用子簇的 centroids_ 预测数据。
避免计算X的行范数。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入数据。 |
| 返回值 | 说明 |
|---|---|
| labels | ndarray of shape(n_samples,) 标签的数据 |
set_params(self, **params)
设置此估计器的参数
该方法适用于简单估计器以及嵌套对象(例如pipelines)。后者具有表单的 <component>__<parameter>参数,这样就可以更新嵌套对象的每个组件。
| 表格 | 说明 |
|---|---|
| **params | dict 估计器参数 |
| 返回值 | 说明 |
|---|---|
| self | object 估计器实例 |
transform(self, X)
将X转换为子簇质心维数。
每个维度表示从样本点到每个簇质心的距离。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入数据。 |
| 返回值 | 说明 |
|---|---|
| X_trans | {array-like, sparse matrix} of shape (n_samples, n_clusters) 已转换的数据 |