

Search
Please activate JavaScript to enable the search functionality.
From here you can search these documents. Enter your search words into the box below and click "search". Note that the search function will automatically search for all of the words. Pages containing fewer words won't appear in the result list.
Search Results
Search finished, found 840 page(s) matching the search query.
-
metrics.pairwise.manhattan_distances
```python sklearn.metrics.pairwise.manhattan_distances(X, Y=None, *, sum_over_features=True) ```
-
sklearn.model_selection.LeavePOut
```python class sklearn.model_selection.LeavePOut(p) ``` [[源码](https://github.com/scikit-learn/
-
sklearn.preprocessing.MaxAbsScaler
```python class sklearn.preprocessing.MaxAbsScaler(*, copy=True) ``` [[源码]](https://github.com/scik
-
sklearn.utils.safe_sqr
```python sklearn.utils.safe_sqr(X, *, copy=True) ``` [源码](https://github.com/scikit-learn/scik
-
二维数字嵌入上的各种凝聚聚类
在数字数据集的2D嵌入上用于聚集聚类的各种链接选项的说明。 此示例的目标是直观地显示指标的行为,而不是为数字找到好的聚类。这就是为什么这个例子适用于2D嵌入。 这个例子向我们展示的是聚集性
-
单调约束
这个例子说明了单调约束对梯度提升估计器的影响。 我们创建了一个人工数据集,其中目标值一般与第一个特征正相关(具有一些随机和非随机变化),而在一般情况下与第二个特征呈负相关。 通过在学习过程
-
比较各种在线求解器
一个示例,展示了不同的在线求解器在手写数字数据集上的表现。 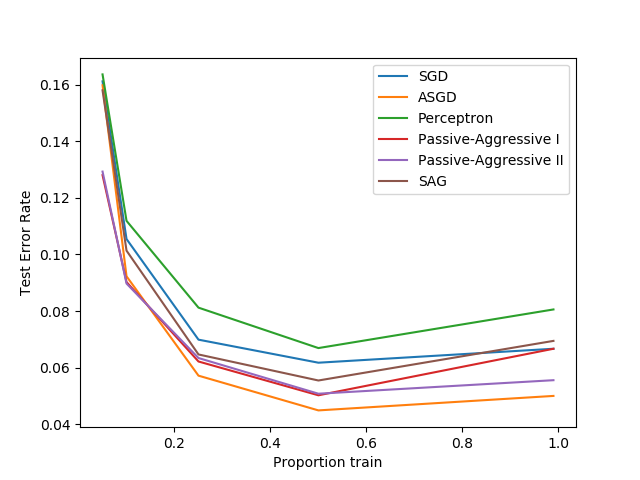 ```python train
-
sklearn.cluster.DBSCAN
```python class sklearn.cluster.DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params
-
sklearn.linear_model.BayesianRidge
```python class sklearn.linear_model.BayesianRidge(*, n_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=
-
sklearn.metrics.pairwise.nan_euclidean_distances
```python sklearn.metrics.pairwise.nan_euclidean_distances(X, Y=None, *, squared=False, missing_valu
-
sklearn.datasets.make_checkerboard
```python sklearn.datasets.make_checkerboard(shape, n_clusters, *, noise=0.0, minval=10, maxval=100,
-
sklearn.model_selection.PredefinedSplit
```python class sklearn.model_selection.PredefinedSplit(test_fold) ``` [[源码](https://github.com
-
sklearn.preprocessing.MinMaxScaler
```python class sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1), *, copy=True) ``` 通过将每个要素缩
-
sklearn.utils.shuffle
```python sklearn.utils.shuffle(*arrays, **options) ``` [源码](https://github.com/scikit-learn/scikit
-
K-means聚类
图中首先显示了使用一个K-means算法产生三个聚类会是什么样的结果。然后显示错误初始化对分类过程的影响。通过将n_init设置为1(默认值为10),可以减少算法使用不同的质心种子运行的次数。下一幅图

