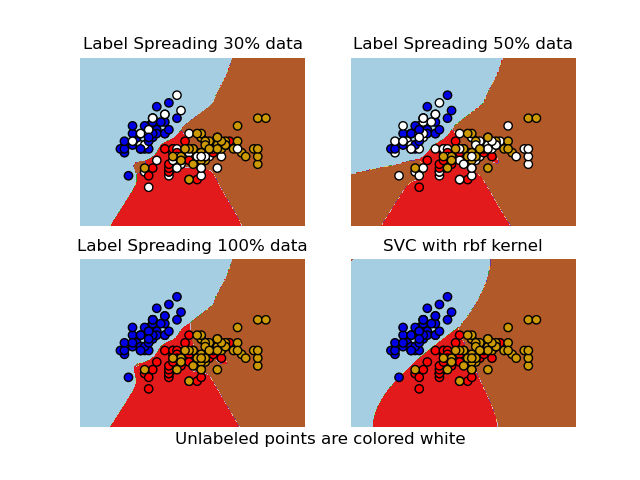
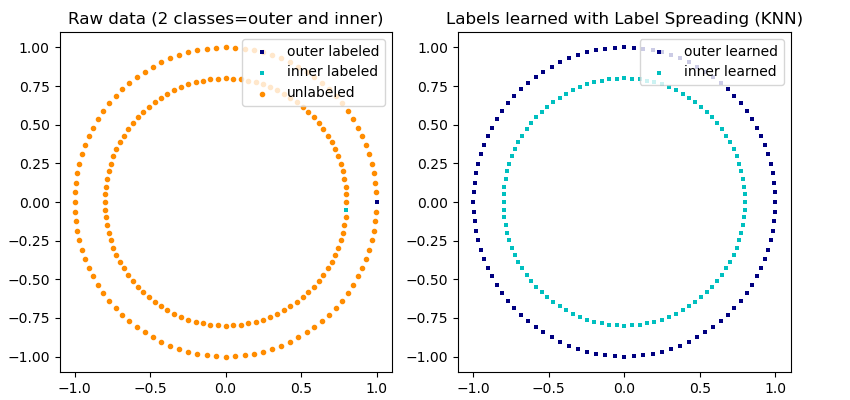
sklearn.semi_supervised.LabelSpreading¶
class sklearn.semi_supervised.LabelSpreading(kernel='rbf', *, gamma=20, n_neighbors=7, alpha=0.2, max_iter=30, tol=0.001, n_jobs=None)
用于半监督学习的LabelSpreading模型
该模型类似于基本的标签传播算法,但是使用基于归一化图拉普拉斯算子和跨标签的软夹持的关联矩阵。
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| kernel | {‘knn’, ‘rbf’} or callable, default=’rbf’ 要使用的内核函数或内核函数本身的字符串标识符。只有'rbf'和'knn'字符串是有效输入。传递的函数应采用两个输入,每个输入的形状为(n_samples,n_features),并返回一个(n_samples,n_samples)形状的权重矩阵。 |
| gamma | float, default=20 rbf内核的参数。 |
| n_neighbors | int, default=7 knn内核的参数,它是严格的正整数。 |
| alpha | float, default=0.2 软夹持系数。(0,1)中的一个值,指定一个实例从它的邻居(而不是它的初始标签)接收的信息的相对数量。alpha = 0表示保留初始标签信息;alpha = 1表示替换所有初始信息。 |
| max_iter | int, default=1000 允许的最大迭代次数。 |
| tol | float, 1e-3 收敛容差:认为系统处于稳定状态的阈值。 |
| n_jobs | int, default=None 要运行的核心数。 除非在上下文中设置了 joblib.parallel_backend,否则None表示1 。 -1表示使用所有处理器。有关更多详细信息,请参见词汇表。 |
| 属性 | 说明 |
|---|---|
| X_ | ndarray of shape (n_samples, n_features) 输入数组。 |
| classes_ | ndarray of shape (n_classes,) 用于分类的不同类别标签。 |
| label_distributions_ | ndarray of shape (n_samples, n_classes) 每个项目的分类分布。 |
| transduction_ | ndarray of shape (n_samples) 通过转换分配给每个项目的标签。 |
| n_iter_ | int 运行的迭代次数。 |
另见
基于非正规图的半监督学习
参考
Dengyong Zhou, Olivier Bousquet, Thomas Navin Lal, Jason Weston, Bernhard Schoelkopf. Learning with local and global consistency (2004) http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.115.3219
示例
>>> import numpy as np
>>> from sklearn import datasets
>>> from sklearn.semi_supervised import LabelSpreading
>>> label_prop_model = LabelSpreading()
>>> iris = datasets.load_iris()
>>> rng = np.random.RandomState(42)
>>> random_unlabeled_points = rng.rand(len(iris.target)) < 0.3
>>> labels = np.copy(iris.target)
>>> labels[random_unlabeled_points] = -1
>>> label_prop_model.fit(iris.data, labels)
LabelSpreading(...)
方法
| 方法 | 说明 |
|---|---|
fit(X, y) |
拟合基于半监督的标签传播模型。 |
get_params([deep]) |
获取此估计器的参数。 |
predict(X) |
在模型上执行归纳推理。 |
predict_proba(X) |
预测每种可能结果的概率。 |
score(X, y[, sample_weight]) |
返回给定测试数据和标签上的平均准确度。 |
set_params(**params) |
设置此估计器的参数。 |
__init__(kernel='rbf', *, gamma=20, n_neighbors=7, alpha=0.2, max_iter=30, tol=0.001, n_jobs=None)
初始化self。请参阅help(type(self))获取更准确的信息。
fit(X, y)
拟合基于半监督的标签传播模型。
提供所有输入数据的矩阵X(标记和未标记)和对应的标记矩阵y,对未标记样本有一个专用的标记值。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 形状为(n_samples,n_samples)的矩阵。 |
| y | array-like of shape (n_samples,)n_labeled_samples(未标记的点被标记为-1)所有未标记的样本将被转换指定的标签。 |
| 返回值 | 说明 |
|---|---|
| self | object |
get_params(deep=True)
获取此估计量的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估算器和所包含子对象的参数。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名称映射到其值。 |
predict(X )
在模型上执行归纳推理。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 数据矩阵。 |
| 返回值 | 说明 |
|---|---|
| y | ndarray of shape (n_samples,) 输入数据的预测值。 |
predict_proba(X )
预测每种可能类别的概率。
计算X中每个样本的概率估计值,以及训练过程中看到的每个可能结果(分类分布)。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 数据矩阵。 |
| 参数 | 说明 |
|---|---|
| probabilities | ndarray of shape (n_samples, n_classes) 跨类标签的归一化概率分布。 |
score(X,y,sample_weight = None )
返回给定测试数据和标签上的平均准确度。
在多标签分类中,这是子集准确性,这是一个苛刻的指标,因为需要为每个样本正确预测对应的标签集。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 测试样本。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真实标签。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重。 |
| 返回值 | 说明 |
|---|---|
| score | float 真实值与测试值的平均准确度。 |
set_params(**params)
设置此估算器的参数。
该方法适用于简单的估计器以及嵌套对象(例如管道)。后者具有<component>__<parameter>形式的参数, 以便可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估计器参数。 |
| 返回值 | 说明 |
|---|---|
| self | object 估计器实例。 |