sklearn.metrics.brier_score_loss¶
sklearn.metrics.brier_score_loss(y_true, y_prob, *, sample_weight=None, pos_label=None)
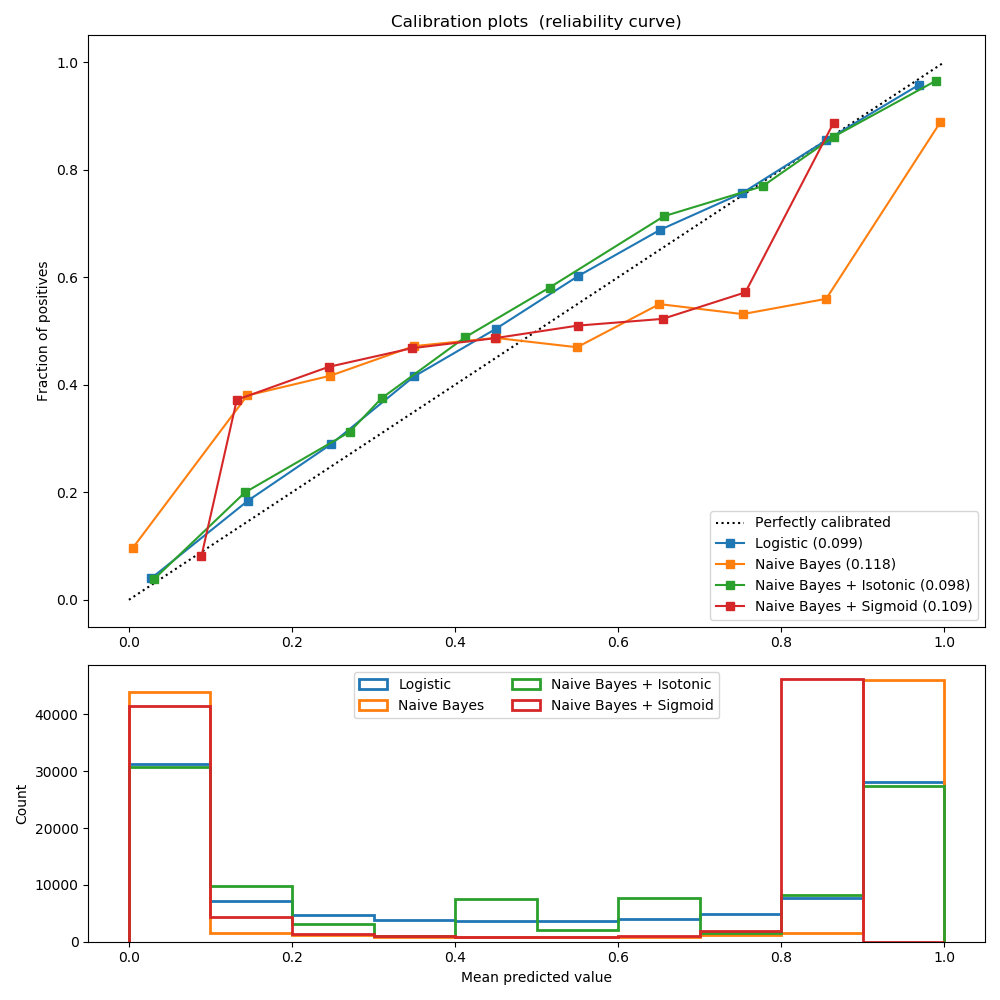
计算Brier分数。
Brier分数越小越好,因此命名为“loss”。在一组N个预测中的所有项目上,Brier分数测量(1)分配给项目i可能结果的预测概率与(2)实际结果之间的均方差。因此,一组预测的Brier分数越低,则对预测的校准就越好。请注意,Brier分数始终取0到1之间的值,因为这是预测概率(必须在0到1之间)和实际结果(只能取0到1)之间的最大可能差值。)。Brier loss由精制损失和校准损失组成。 Brier得分适用于可以构造为真或假的二进制和分类结果,但不适用于可以采用三个或更多值的序数变量(这是因为Brier分数假设所有可能的结果的彼此“距离”相等)。哪个标签被视为肯定标签是通过参数pos_label(默认值为1)控制的。请阅读用户指南中的更多内容。
| 参数 | 说明 |
|---|---|
| y_true | array, shape (n_samples,) 实际targets。 |
| y_prob | array, shape (n_samples,) 正类的概率。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重。 |
| pos_label | int or str, default=None 正向类别的标签。除非y_true为全0或全为-1时pos_label默认为1;否则默认为更大的标签。 |
| 返回值 | 说明 |
|---|---|
| score | float Brier得分。 |
参考
1 Wikipedia entry for the Brier score.
示例
>>> import numpy as np
>>> from sklearn.metrics import brier_score_loss
>>> y_true = np.array([0, 1, 1, 0])
>>> y_true_categorical = np.array(["spam", "ham", "ham", "spam"])
>>> y_prob = np.array([0.1, 0.9, 0.8, 0.3])
>>> brier_score_loss(y_true, y_prob)
0.037...
>>> brier_score_loss(y_true, 1-y_prob, pos_label=0)
0.037...
>>> brier_score_loss(y_true_categorical, y_prob, pos_label="ham")
0.037...
>>> brier_score_loss(y_true, np.array(y_prob) > 0.5)
0.0