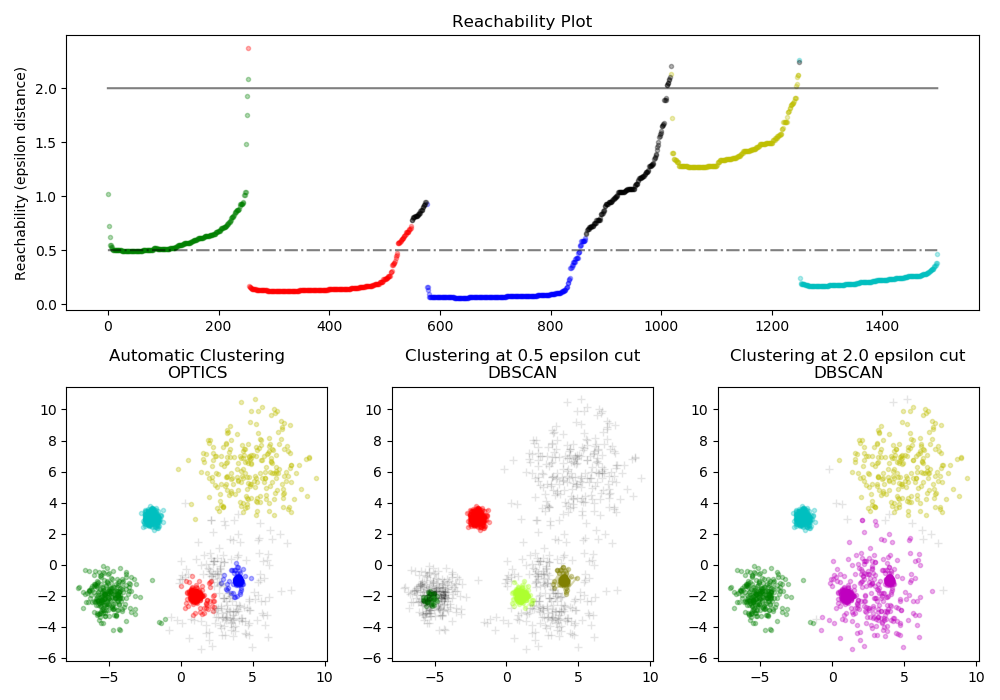
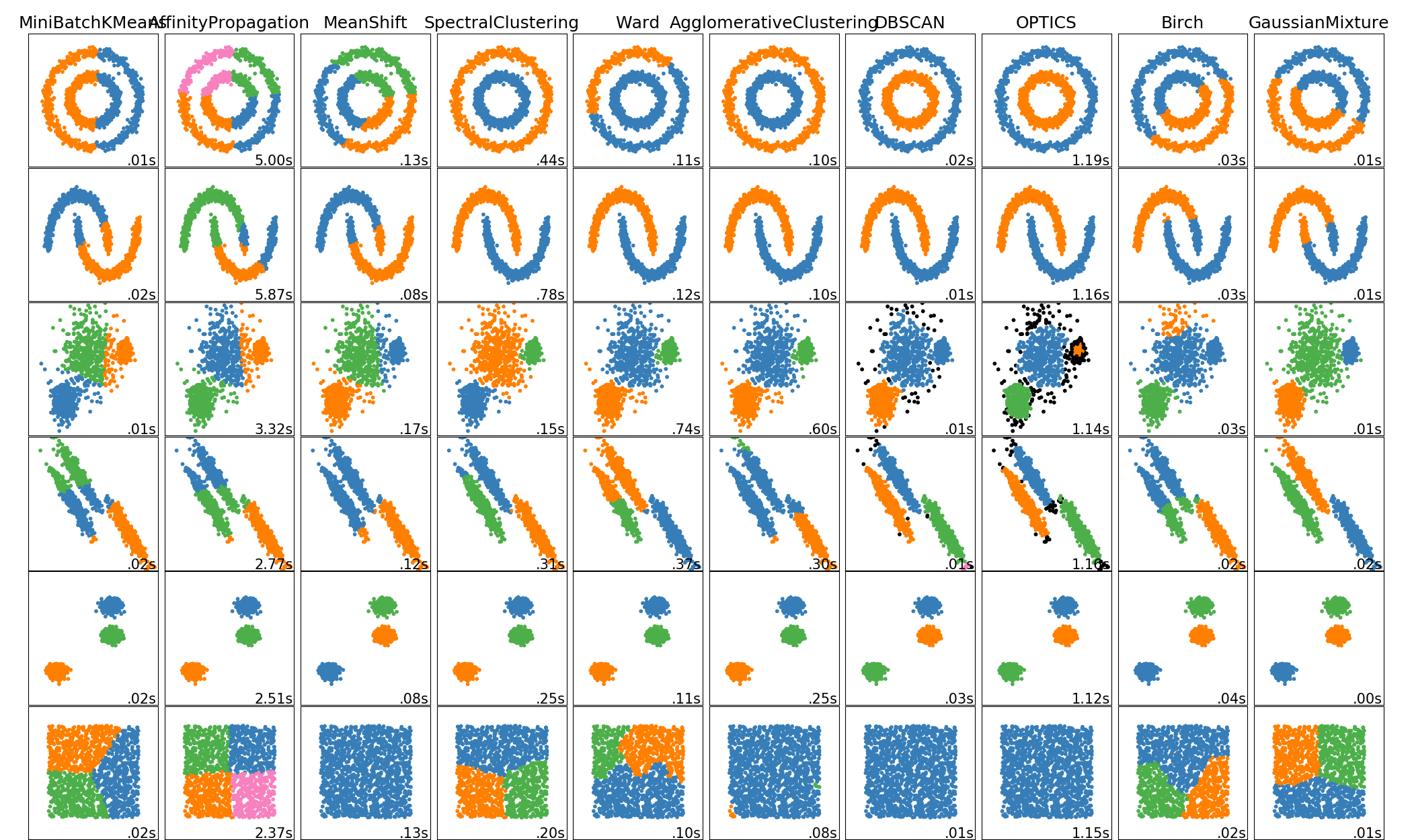
sklearn.cluster.OPTICS¶
class sklearn.cluster.OPTICS(*, min_samples=5, max_eps=inf, metric='minkowski', p=2, metric_params=None, cluster_method='xi', eps=None, xi=0.05, predecessor_correction=True, min_cluster_size=None, algorithm='auto', leaf_size=30, n_jobs=None)
从向量数组估计聚类结构
OPTICS(用于确定聚类结构的排序点)与DBSCAN密切相关,它找到了高密度的核心样本,并从它们中扩展了团簇[R2c55e37003fe-1]。与DBSCAN不同,为可变邻域半径保持集群层次结构。与DBSCAN当前的sklearn实现相比,更适合在大型数据集上使用。
然后使用DBSCAN-like方法(cluster_method = ‘dbscan’) 或[R2c55e37003fe-1]中提出的自动技术 (cluster_method = ‘xi’)提取簇。
该实现首先对所有点执行k最近邻域搜索,以识别核大小,然后在构造簇序时只计算到未处理点的距离,从而偏离了原始OPTICS。请注意,我们没有使用堆来管理扩展候选项,因此时间复杂度将是O(n^2)。
在用户指南中阅读更多内容.
| 参数 | 列表 |
|---|---|
| min_samples | int > 1 or float between 0 and 1 (default=5) 一个点被视为核心点的邻域样本数。此外,上下陡峭地区不能有超过 min_samples连续的非陡峭点。表示为样本数的绝对值或一小部分(四舍五入至少为2)。 |
| max_eps | float, optional (default=np.inf) 两个样本之间的最大距离,其中一个被视为另一个样本的邻域。 np.inf默认值将识别所有规模的聚类;减少max_eps会缩短运行时间。 |
| metric | str or callable, optional (default=’minkowski’) 用于距离计算的度量。任何来自scikit-learn或scipy.spatial.distance的度量都可以使用。 如果度量是可调用的函数,则在每对实例(行)上调用它,并记录结果值。可调用应该以两个数组作为输入,并返回一个值,指示它们之间的距离。这适用于Scipy’s度量,但比将度量名称作为字符串传递的效率要低。如果度量是“precomputed”,则假定X是距离矩阵,并且必须是平方的。 度量的有效值是: scikit-learn里面:[‘cityblock’, ‘cosine’, ‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’] scipy.spatial.distance里面:[‘braycurtis’, ‘canberra’, ‘chebyshev’, ‘correlation’, ‘dice’, ‘hamming’, ‘jaccard’, ‘kulsinski’, ‘mahalanobis’, ‘minkowski’, ‘rogerstanimoto’, ‘russellrao’, ‘seuclidean’, ‘sokalmichener’, ‘sokalsneath’, ‘sqeuclidean’, ‘yule’] 有关这些度量的详细信息,请参阅scipy.spatial.distance的文档。 |
| p | int, optional (default=2) 来自 sklearn.metrics.pairwise_distances的Minkowski度量的参数。当p=1时,这相当于使用曼哈顿距离(L1); 当p=2, 相当于使用欧几里得距离(L2)。对于任意p,使用minkowski_distance (l_p)。 |
| metric_params | dict, optional (default=None) 度量函数的附加关键字参数。 |
| cluster_method | str, optional (default=’xi’) 利用计算的可达性和有序性提取簇的提取方法,可能的值是“xi”和“dbscan”。 |
| eps | float, optional (default=None) 两个样本之间的最大距离,其中一个被视为另一个样本的邻域内。默认情况下,它假设的值与 max_eps相同。只有当cluster_method='dbscan'才被使用。 |
| xi | float, between 0 and 1, optional (default=0.05) 确定构成聚类边界的可达性图的最小陡度。例如,可达图中的一个向上点定义为从一个点到它的后继点最多为1-xi的比率。只有当 cluster_method='xi'才被使用。 |
| predecessor_correction | bool, optional (default=True) 根据OPTICS预先计算的[R2c55e37003fe-2]正确的团簇。此参数对大多数数据集的影响最小。只有当 cluster_method='xi'才被使用。 |
| min_cluster_size | int > 1 or float between 0 and 1 (default=None) OPTICS聚类中的最小样本数,表示为样本数的绝对值或一部分(四舍五入为至少2)。如果为None, min_samples的值将被使用。只有当cluster_method='xi'才被使用。 |
| algorithm | {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’ NearestNeighbors模块用于计算点态距离和寻找最近邻的算法。 |
| p | float, default=None 用于计算点间距离的Minkowski度量的幂。 - ‘ball_tree’将会使用 BallTree- ‘kd_tree’将会使用 KDtree- ‘brute’将会使用蛮力搜索 - ‘auto’将尝试根据传递给 fit方法的值来确定最合适的算法。(默认) |
| n_jobs | int or None, optional (default=None) 要为邻居搜索的并行作业数。 None意味1, 除非在joblib.parallel_backend环境中。-1指使用所有处理器。有关详细信息,请参Glossary。 |
| 属性 | 说明 |
|---|---|
| labels_ | array, shape (n_samples,) 为fit()提供的数据集中每个点的聚类标签。不包含在 cluster_hierarchy_的叶簇中的含噪样本和点被标记为-1。 |
| reachability_ | array, shape (n_samples,) 每个样本的可达距离,按对象顺序索引。使用 clust.achaability_[clust.order_]按聚类顺序访问。 |
| ordering_ | array, shape (n_samples,) 样本索引的聚类排序列表。 |
| core_distances_ | array, shape (n_samples,) 每个样本成为一个核心点的距离,按对象顺序索引。有一个inf的距离点永远不会成为核心。使用 clust.core_distances_[clust.ordering_]按聚类排序进行访问。 |
| predecessor_ | array, shape (n_samples,) 指出一个样本是从中得到的,并按对象顺序进行索引。种子点有-1的前身。 |
| cluster_hierarchy_ | array, shape (n_clusters, 2) 每一行中 [start,end]形式的聚类列表,包括所有索引。聚类按照(end, -start)(升序)排列,这样包含较小的簇的更大的簇就在那些较小的簇之后。由于标签不反映层次结构,通常len(cluster_hierarchy_) > np.unique(optics.labels_)。请注意这些索引是ordering_。即X[ordering_][start:end + 1]形成成一个簇。只有当cluster_method='xi'才被使用。 |
另见
指定邻域半径(eps)的相似聚类。针对运行时间进行了优化。
参考
R2c55e37003fe-1([1],[2]) Ankerst, Mihael, Markus M. Breunig, Hans-Peter Kriegel, and Jörg Sander. “OPTICS: ordering points to identify the clustering structure.” ACM SIGMOD Record 28, no. 2 (1999): 49-60.
[R2c55e37003fe-2] Schubert, Erich, Michael Gertz. “Improving the Cluster Structure Extracted from OPTICS Plots.” Proc. of the Conference “Lernen, Wissen, Daten, Analysen” (LWDA) (2018): 318-329.
示例
>>> from sklearn.cluster import OPTICS
>>> import numpy as np
>>> X = np.array([[1, 2], [2, 5], [3, 6],
... [8, 7], [8, 8], [7, 3]])
>>> clustering = OPTICS(min_samples=2).fit(X)
>>> clustering.labels_
array([0, 0, 0, 1, 1, 1])
方法
| 方法 | 说明 |
|---|---|
fit(self, X[, y]) |
执行OPTICS聚类 |
fit_predict(self, X[, y]) |
在X上执行聚类并返回聚类标签 |
get_params(self[, deep]) |
获取此估计器的参数 |
set_params(self, **params) |
设置此估计器的参数 |
__init__(self, *, min_samples=5, max_eps=inf, metric='minkowski', p=2, metric_params=None, cluster_method='xi', eps=None, xi=0.05, predecessor_correction=True, min_cluster_size=None, algorithm='auto', leaf_size=30, n_jobs=None)
初始化self。请参阅help(type(self))以获得准确的说明。
fit(self, X, y=None)
执行OPTICS聚类
提取点和可达距离的有序列表,并利用OPTICS对象实例化时指定的max_eps进行初始聚类。
| 参数 | 说明 |
|---|---|
| X | array, shape (n_samples, n_features), or (n_samples, n_samples) if metric=’precomputed’ 一个特征数组,或样本之间的距离数组, 如果metric=’precomputed’ |
| y | ignored Ignored |
| 返回值 | 说明 |
|---|---|
| self | instance of OPTICS 实例 |
fit_predict(self, X, y=None)
在X上执行聚类并返回聚类标签。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 输入数据 |
| y | Ignored 未使用,在此按约定呈现为api一致性。 |
| 返回值 | 说明 |
|---|---|
| labels | ndarray of shape (n_samples,) 聚类标签 |
get_params(self, deep=True)
获取此估计器的参数
| 表格 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估计器的参数和所包含的作为估计量的子对象。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 映射到其值的参数名称 |
set_params(self, **params)
设置此估计器的参数
该方法适用于简单估计器以及嵌套对象(例如pipelines)。后者具有表单的 <component>__<parameter>参数,这样就可以更新嵌套对象的每个组件。
| 表格 | 说明 |
|---|---|
| **params | dict 估计器参数 |
| 返回值 | 说明书 |
|---|---|
| self | object 估计器实例 |