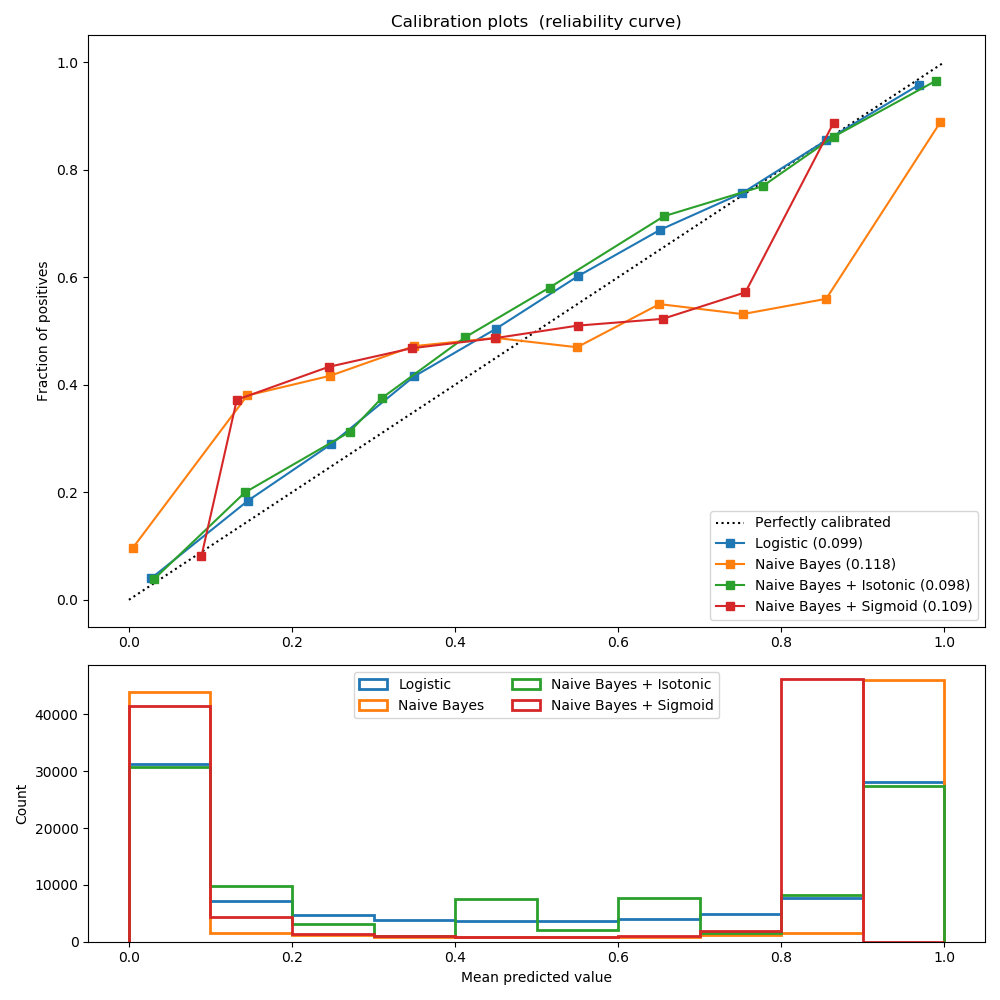
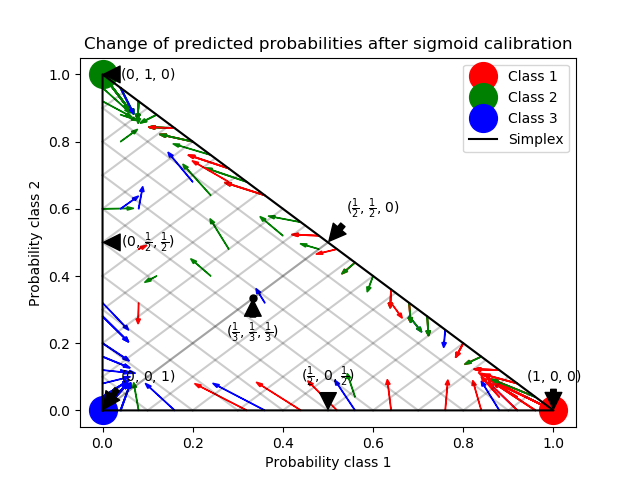
sklearn.calibration.CalibratedClassifierCV¶
class sklearn.calibration.CalibratedClassifierCV(base_estimator=None, *, method='sigmoid', cv=None)
isotonic回归或逻辑回归的概率校正。
校准依据的是 base_estimator 的decision_function方法(如果存在的话),否则是predict_proba。
在用户指南中阅读更多内容。
新版本0.19
| 参数 | 说明 |
|---|---|
| base_estimator | instance BaseEstimator 分类器的输出需要被校准以提供更准确的 predict_proba输出。 |
| method | ‘sigmoid’ or ‘isotonic’ 用于校准的方法。可以是“Sigmoid”,它对应于Platt的方法(即逻辑回归模型),也可以是“isotonic”,这是一种非参数方法。建议不要用太少的校准样本 (<<1000)进行等渗校准,因为它趋向于过拟合。 |
| cv | integer, cross-validation generator, iterable or “prefit”, optional 确定交叉验证的拆分策略。cv的可能输入包括: - None, 默认使用5折交叉验证 - 整数, 指定交叉验证的折数 - CV splitter - 一个可迭代由训练集和测试集划分的索引的数组。 对于输入整数或者None, 如果 y是一个二分类或者多分类, 则使用sklearn.model_selection.StratifiedKFold 如果 y既不是二分类也不是多分类, 则使用sklearn.model_selection.KFold 有关可在此处使用的各种交叉验证策略,请参阅用户指南。 如果“prefit”通过,则假定 base_estimator已经拟合,所有数据都用于校准。在0.22版中更改:如果为None, 则CV默认值从3折更改为5折。 |
| 属性 | 说明 |
|---|---|
| classes_ | array, shape (n_classes) 类标签 |
| calibrated_classifiers_ | list (len() equal to cv or 1 if cv == “prefit”) 已校准的分类器列表,每个交叉验证折都有一个,除了验证折外,已在所其他折上进行了拟合,并在验证折上进行了校准。 |
参考
R57cf438d7060-1 Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers, B. Zadrozny & C. Elkan, ICML 2001
R57cf438d7060-2 Transforming Classifier Scores into Accurate Multiclass Probability Estimates, B. Zadrozny & C. Elkan, (KDD 2002)
R57cf438d7060-3 Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods, J. Platt, (1999)
R57cf438d7060-4 Predicting Good Probabilities with Supervised Learning, A. Niculescu-Mizil & R. Caruana, ICML 2005
方法
| 方法 | 说明 |
|---|---|
fit(self, X, y[, sample_weight]) |
拟合校准模型 |
get_params(self[, deep]) |
获取此估计器的参数 |
predict(self, X) |
预测新样本的目标 |
predict_proba(self, X) |
分类后验概率 |
score(self, X, y[, sample_weight]) |
返回给定测试数据和标签的平均精度。 |
set_params(self, **params) |
设置此估计器的参数 |
__init__(self, /, *args, **kwargs)
初始化self。请参阅help(type(self))以获得准确的说明。
fit(self, X, y, sample_weight=None)
拟合校准模型。
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 训练数据 |
| y | array-like, shape (n_samples,) 目标值 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重。如果为None, 样本的权重是一样的。 |
| 返回值 | 说明 |
|---|---|
| self | object 返回self的实例 |
get_params(self, deep=True)
获取此估计器的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估计器的参数和所包含的作为估计器的子对象。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 映射到其值的参数名称 |
predict(self, X)
预测新样品的目标。预测类是具有最高概率的类,因此可以与未标记分类器的预测不同。
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 样本 |
| 返回值 | 说明 |
|---|---|
| C | array, shape (n_samples,) 预测类 |
predict_proba(self, X)
后验分类概率。
该函数根据测试向量X上的每个类返回分类的后验概率。
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 样本 |
| 返回值 | 说明 |
|---|---|
| C | array, shape (n_samples,) 预测类 |
score(self, X, y, sample_weight=None)
返回给定测试数据和标签的平均精度。
在多标签分类中,这是子集的准确性,这是一个严格的度量,因为您需要对每个样本正确地预测每个标签集。
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) 测试样本 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) 测试样板的真实标签 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重 |
| 返回值 | 说明 |
|---|---|
| score | float self.predict(X)与y的平均精度。 |
set_params(self, **params)
设置此估计器的参数。
该方法适用于简单估计器以及嵌套对象(例如pipelines)。后者具有表单的参数 <component>__<parameter>,这样就可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估计器参数 |
| 返回值 | 说明 |
|---|---|
| self | 估计器实例。 |