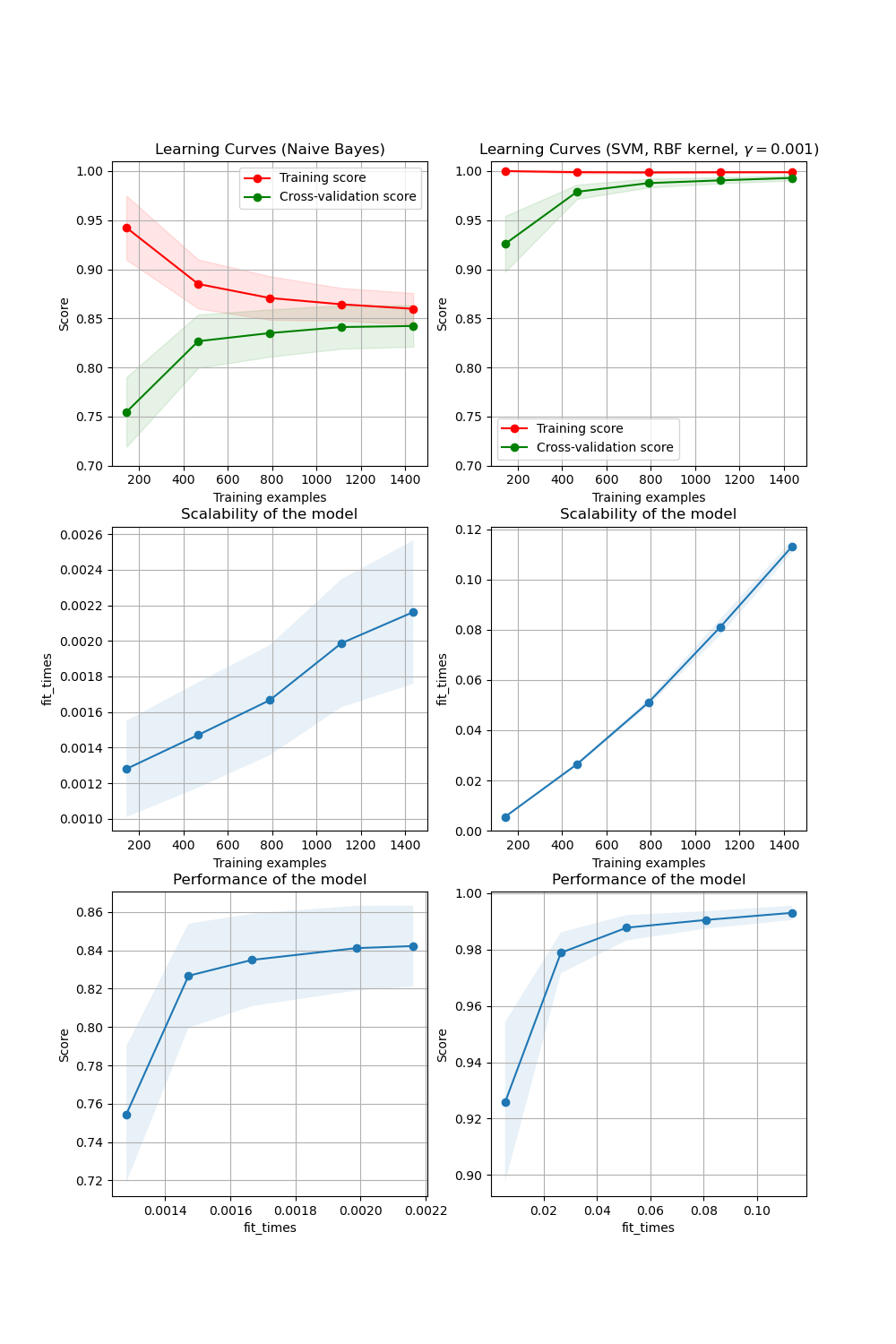
sklearn.model_selection.learning_curve¶
sklearn.model_selection.learning_curve(estimator, X, y, *, groups=None, train_sizes=array([0.1, 0.33, 0.55, 0.78, 1. ]), cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=None, pre_dispatch='all', verbose=0, shuffle=False, random_state=None, error_score=nan, return_times=False)
[源码]
学习曲线。
确定不同训练集大小的交叉验证训练和测试分数。
交叉验证生成器将整个数据集在训练和测试数据中分割k次。具有不同大小的训练集的子集将用于训练估计器,并计算每个训练子集的大小和测试集的分数。然后,对每个训练子集大小的k次运行的分数取平均值。
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| estimator | object type that implements the “fit” and “predict” methods 每次验证都会克隆的该类型的对象。 |
| X | array-like of shape (n_samples, n_features) 用于训练的向量,其中n_samples是样本数量,n_features是特征数量。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) 相对于X的标签,用于分类或回归;无监督学习为None。 |
| groups | array-like of shape (n_samples,), default=None 将数据集切分为训练集或测试集时使用的样本的分组标签。仅与“ Group” cv 实例(例如 GroupKFold)结合使用。 |
| train_sizes | array-like of shape (n_ticks,), default=np.linspace(0.1, 1.0, 5) 用于生成学习曲线的相对或绝对数量的训练样本。如果dtype为float,则视为训练集最大规模的一部分(由所选验证方法确定),即它必须在(0,1]之内,否则将被解释为训练集的绝对大小。请注意,为进行分类,样本数量通常必须足够大,每个类至少包含一个样本。 |
| cv | int, cross-validation generator or an iterable, default=None 确定交叉验证切分策略。cv值可以输入: - None,默认使用5折交叉验证 - int,用于指定 (Stratified)KFold的折数- CV splitter, - 可迭代输出训练集和测试集的切分作为索引数组 对于int或 None输入,如果估计器是分类器,并且 y是二分类或多分类,则使用StratifiedKFold。在所有其他情况下,均使用KFold。有关可在此处使用的各种交叉验证策略,请参阅用户指南。 在版本0.22中:如果 cv为None,默认值从3折更改为5折。 |
| scoring | str or callable, default=None 一个str(参见模型评估文档)或一个信息为 scorer(estimator, X, y)的可调用对象或函数的评分器,它应该只返回一个值。 |
| exploit_incremental_learning | bool, default=False 如果估计器支持增量学习,这将用于加快拟合不同训练集大小的速度。 |
| n_jobs | int, default=None 用于进行计算的CPU数量。 None除非在joblib.parallel_backend环境中,否则表示1 。 undefined表示使用所有处理器。有关更多详细信息,请参见词汇表。 |
| pre_dispatch | int or str, default=’all’ 并行执行的预调用CPU数(默认为全部)。该选项可以减少分配的内存。str可以是类似“ 2 * n_jobs”的表达式。 |
| verbose | int, default=0 控制详细程度:越高,消息越多。 |
| shuffle | bool, default=False 是否在基于"train_sizes''为前缀之前对训练数据进行打乱。 |
| random_state | int or RandomState instance, default=None 在 shuffle为true时使用。为多个函数调用传递可重复输出的int值。请参阅词汇表。 |
| error_score | ‘raise’ or numeric, default=np.nan 估计器拟合出现错误时,分配给分数的值。如果设置为“ raise”,则会引发错误。如果给出数值,则引发FitFailedWarning。此参数不会影响重新拟合步骤,这将总是引发错误。 0.20版中的新功能。 |
| return_times | bool, default=False 是否返回拟合和计算得分的时间。 |
| 返回值 | 说明 |
|---|---|
| train_sizes_abs | array of shape (n_unique_ticks,) 已用于生成学习曲线的训练样本数。请注意,标记号的数目可能少于n_ticks,因为重复的条目将被删除。 |
| train_scores | array of shape (n_ticks, n_cv_folds) 训练集准确率。 |
| test_scores | array of shape (n_ticks, n_cv_folds) 测试集准确率。 |
| fit_times | array of shape (n_ticks, n_cv_folds) 拟合花费的时间,以秒为单位。仅在 return_times 为True时存在。 |
| score_times | array of shape (n_ticks, n_cv_folds) 计算准确率花费的时间,以秒为单位。仅在 return_times 为True时存在。 |
注