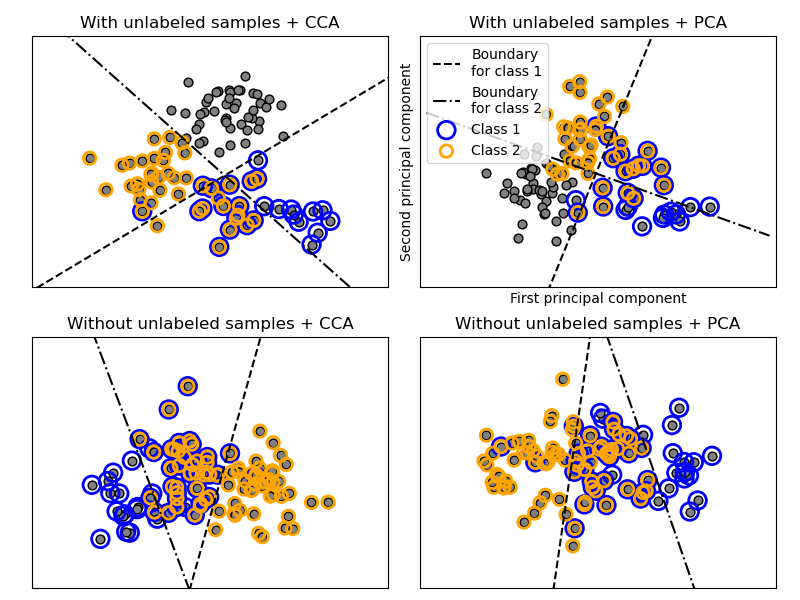
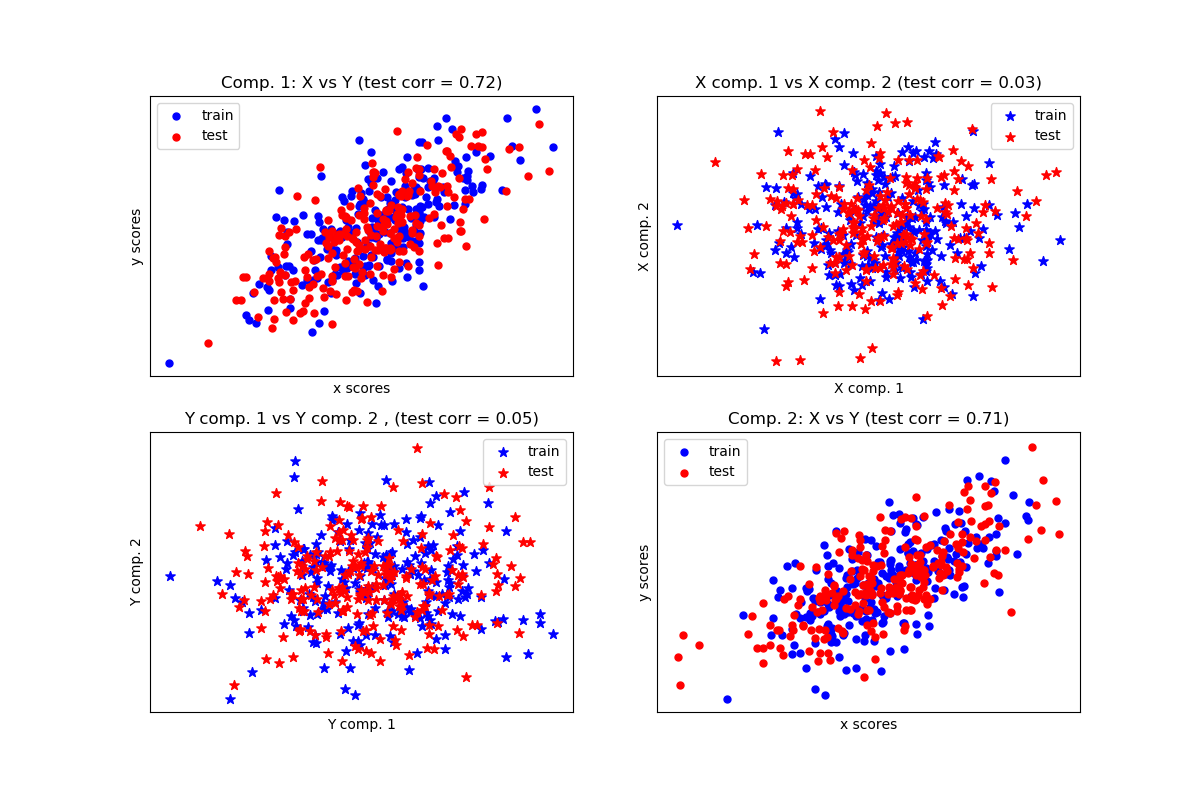
sklearn.cross_decomposition.CCA¶
class sklearn.cross_decomposition.CCA(n_components=2, *, scale=True, max_iter=500, tol=1e-06, copy=True)
CCA典型相关分析
CCA继承mode=“B”和deflation_mode =“canonical”的PLS。
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| n_components | int, (default 2) 要保留的组件数。 |
| scale | boolean, (default True) 是否缩放数据? |
| max_iter | an integer, (default 500) NIPALS内部循环的最大迭代次数 |
| tol | non-negative real, default 1e-06. 迭代算法中使用的容差。 |
| copy | boolean 是否在副本上进行紧缩。 除非您不关心副作用,否则将默认值设为True |
| 属性 | 说明 |
|---|---|
| x_weights_ | array, [p, n_components] X的权重向量。 |
| y_weights_ | array, [q, n_components] Y的权重向量。 |
| x_loadings_ | array, [p, n_components] X的加载向量。 |
| y_loadings_ | array, [q, n_components] Y的加载向量。 |
| x_scores_ | array, [n_samples, n_components] X的分数。 |
| y_scores_ | array, [n_samples, n_components] Y的分数。 |
| x_rotations_ | array, [p, n_components] X块到隐藏的旋转。 |
| y_rotations_ | array, [q, n_components] Y块到隐藏的旋转。 |
| coef_ | array of shape (p, q) 线性模型的系数:Y = X coef_ + Err |
| n_iter_ | array-like 每个组件的NIPALS内部循环的迭代次数。 |
另见:
注
对于每个分量k,找到使max corr(Xk u,Yk v)最大化的权重u,v,使得|u| = |v| = 1
注意,它仅使得分之间的相关性最大化。
X(Xk + 1)块的残差矩阵是通过收缩当前X分数x_score获得的。
Y(Yk + 1)块的残差矩阵是通过收缩当前*Y分数获得的。
参考
Jacob A. Wegelin. A survey of Partial Least Squares (PLS) methods, with emphasis on the two-block case. Technical Report 371, Department of Statistics, University of Washington, Seattle, 2000.
In french but still a reference: Tenenhaus, M. (1998). La regression PLS: theorie et pratique. Paris: Editions Technic.
示例
>>> from sklearn.cross_decomposition import CCA
>>> X = [[0., 0., 1.], [1.,0.,0.], [2.,2.,2.], [3.,5.,4.]]
>>> Y = [[0.1, -0.2], [0.9, 1.1], [6.2, 5.9], [11.9, 12.3]]
>>> cca = CCA(n_components=1)
>>> cca.fit(X, Y)
CCA(n_components=1)
>>> X_c, Y_c = cca.transform(X, Y)
方法
fit(self, X, Y) |
训练数据 |
|---|---|
fit_transform(self, X[, y]) |
在训练集上学习并应用降维。 |
get_params(self[, deep]) |
获取评估器的参数。 |
inverse_transform(self, X) |
将数据转换回其原始空间。 |
predict(self, X[, copy]) |
应用在训练集学习到的降维。 |
score(self, X, y[, sample_weight]) |
返回预测的确定系数R^2。 |
set_params(self,**params) |
设置评估器参数。 |
transform(self, X[, Y, copy]) |
应用在训练集上学习到的降维。 |
__init__(self, n_components=2, *, scale=True, max_iter=500, tol=1e-06, copy=True)
初始化self, 请参阅help(type(self))以获得准确的说明
fit(self, X, Y)
训练数据。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 训练向量,其中n_samples是样本数,n_features是预测变量数。 |
| Y | array-like of shape (n_samples, n_targets) 目标向量,其中n_samples是样本数,n_targets是响应变量数。 |
fit_transform(self, X, y=None)
在训练集上学习并应用降维
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 训练向量,其中n_samples是样本数,n_features是预测变量数。 |
| y | array-like of shape (n_samples, n_targets) 目标向量,其中n_samples是样本数,n_targets是响应变量数。 |
| 返回值 |
|---|
| 如果未指定Y,则为x_scores,否则为(x_scores,y_scores)。 |
get_params(self, deep=True)
获取此估算器的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,将返回此估算器和其所包含子对象的参数。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名称映射到其值。 |
inverse_transform(self, X)
将数据转换回其原始空间。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_components) 新数据,其中n_samples是样本数,n_components是pls分量数。 |
| 返回值 | 说明 |
|---|---|
| x_reconstructed | array-like of shape (n_samples, n_features) |
注
仅当n_components = n_features时,此转换才是精确的
predict(self, X, copy=True)
在训练集上学习到的降维应用
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 训练向量,其中n_samples是样本数,n_features是预测变量数。 |
| copy | boolean, default True 是复制X和Y,还是执行就地归一化。 |
注
该调用需要估计p x q矩阵,这在高维空间中可能是个问题。
score(self, X, y, sample_weight=None)
返回预测的确定系数R^2。
系数R^2定义为(1- u/v),其中u是平方的残差和((y_true-y_pred)** 2).sum(),而v是平方的总和((y_true- y_true.mean())** 2).sum()。 可能的最高得分为1.0,并且可能为负(因为该模型可能会更差)。 不管输入特征如何,常数模型预测y的期望值,获得的R^2分数将始终是0.0。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 测试样本。对于某些评估器,可以是预先计算的核矩阵或通用对象列表,shape =(n_samples,n_samples_fitted),其中n_samples_fitted是用于评估器训练的样本数。 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真实值。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重 |
| 返回值 | 说明 |
|---|---|
| score | float self.predict(X)关于y的R^2 |
注
在回归器上调用score时使用的R2得分使用版本0.23中的multioutput ='uniform_average'来保持与r2_score的默认值一致。 这会影响所有多输出回归器的评分方法(MultiOutputRegressor除外)。
set_params(self, **params)
[源码]
设置此估算器的参数。
该方法适用于简单的估算器以及嵌套对象(例如管道)。后者具有形式参数<component>__<parameter>,以便可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估算器参数。 |
| 返回值 | 说明 |
|---|---|
| self | object 估算器实例。 |
transform(self, X, Y=None, copy=True)
[源码]
在训练集上学习到的降维应用
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 训练向量,其中n_samples是样本数,n_features是预测变量数。 |
| Y | array-like of shape (n_samples, n_targets) 目标向量,其中n_samples是样本数,n_targets是响应变量数。 |
| copy | boolean, default True 是复制X和Y,还是执行就地归一化。 |
| 返回值说明 |
|---|
| 如果未指定Y,则为x_scores,否则为(x_scores,y_scores)。 |