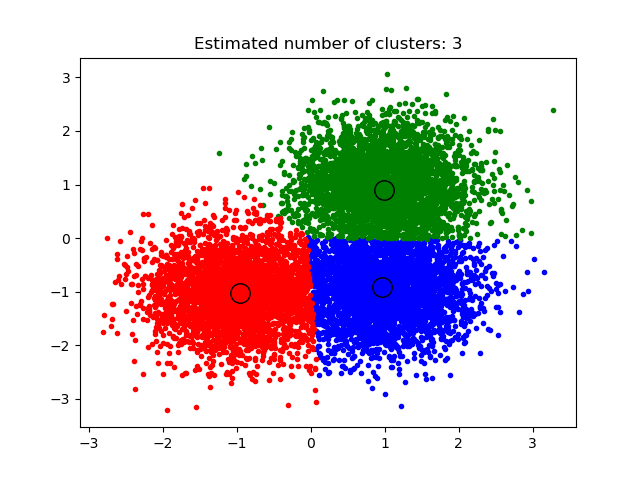
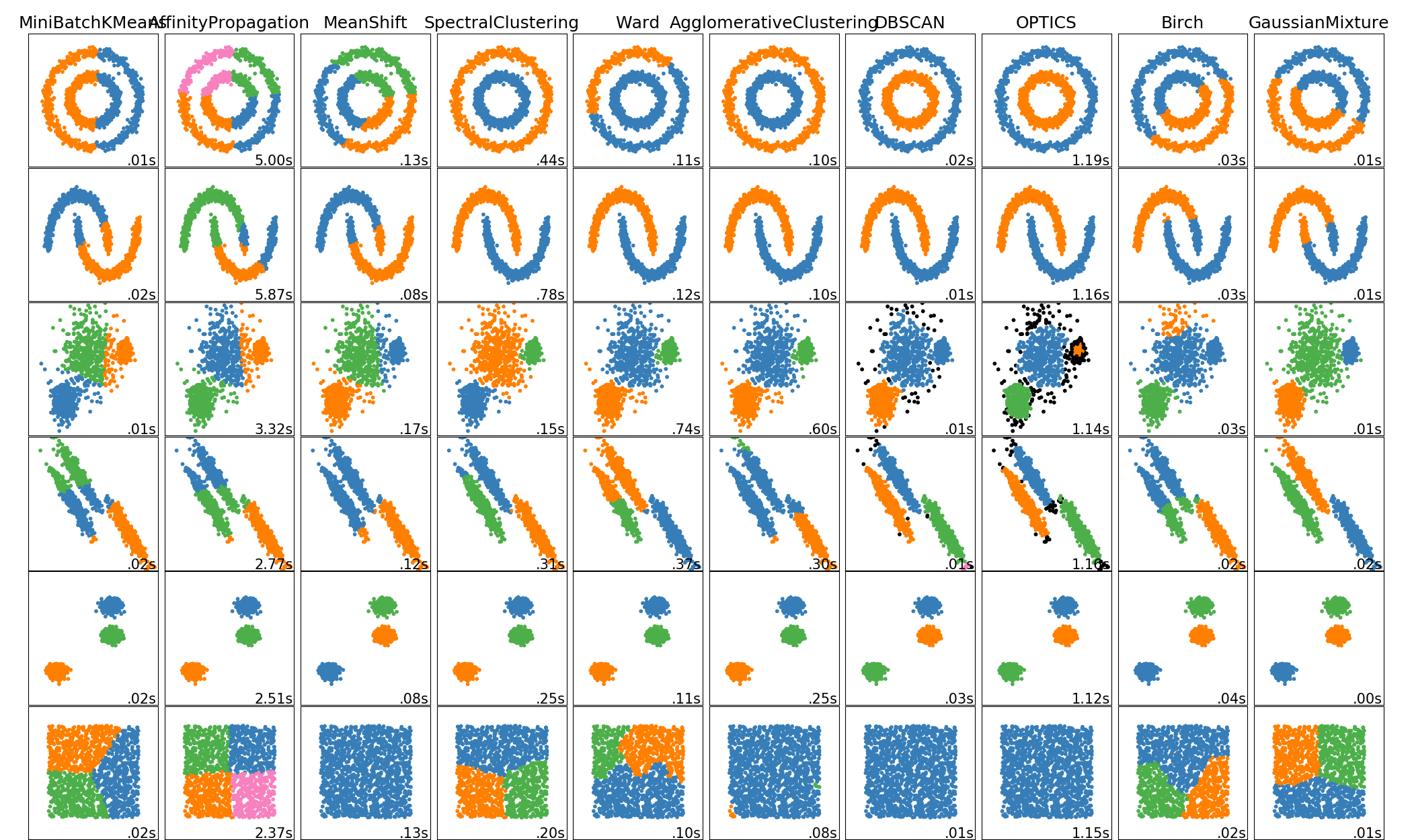
sklearn.cluster.MeanShift¶
class sklearn.cluster.MeanShift(*, bandwidth=None, seeds=None, bin_seeding=False, min_bin_freq=1, cluster_all=True, n_jobs=None, max_iter=300)
使用平坦核的均值移位聚类
均值移位聚类的目的是在平滑的样本密度中发现“blobs”。它是一种基于质心的算法,它的工作方式是将候选的质心更新为给定区域内点的平均值。然后,在后处理阶段对这些候选对象进行过滤,以消除几乎重复的情况,形成最终的质心集。
种子是使用可伸缩性的联调技术执行的。
在用户指南中阅读更多内容
| 参数 | 说明 |
|---|---|
| bandwidth | float, default=None RBF核中使用的带宽。如果不给出带宽,则使用sklearn.cluster.estimate_bandwidth来估算带宽;有关可伸缩性的提示,请参阅该函数的文档(另请参阅下面的Notes)。 |
| seeds | array-like of shape (n_samples, n_features), default=None 用于初始化核的种子。如果未设置,则通过clustering.get_bin_seeds计算,带宽作为网格大小并且其他参数的默认 。 |
| bin_seeding | bool, default=False 如果是True,初始内核位置不是所有点的位置,而是点的离散版本的位置,其中点被绑定到一个网格上,网格的粗度与带宽相对应。将此选项设置为True将加快算法的速度,因为初始化的种子将减少。默认值为False。如果种子参数是None,就忽略它。 |
| min_bin_freq | int, default=1 要加快算法的速度,只接受那些至少有min_bin_freq个点的箱子作为种子。 |
| cluster_all | bool, default=True 如果为True,那么所有的点都是聚在一起的,甚至那些不在任何内核中的孤立点也是如此。孤立点被分配到最近的内核。如果为False,则为孤立点指定聚类标签-1。 |
| n_jobs | int, default=None 用于计算的任务数。这是通过计算n_init中的每一个并行运行来实现的。 None意味着1,除非在joblib.parallel_backend上下文中。-1指使用所有处理器。有关详细信息,请参阅Glossary。 |
| max_iter | int, default=300 如果尚未收敛,则聚类操作终止之前的每个种子点的最大迭代次数(对于该种子点)。 |
| 属性 | 说明 |
|---|---|
| cluster_centers_ | array, [n_clusters, n_features] 簇中心坐标 |
| labels_ | array of shape (n_samples,) 每个点的标签。 |
| n_iter_ | int 对每个种子执行的最大迭代次数。 新版本0.22。 |
注
可伸缩性:
因为这个实现使用一个扁平的内核和一个Ball树来查找每个内核的成员,所以在较低的维度上,复杂度将趋向于O(T*n*log(N)),其中n是样本数,T是点数。在较高的维数中,复杂度趋向于O(T*n^2)。
可以通过使用更少的种子来提高可伸缩性,例如在 get_bin_seeds函数中使用更高的min_bin_freq值。
请注意,estimate_bandwidth函数比MeanShift算法的可伸缩性要小得多,如果使用它,将成为瓶颈。
参考
Dorin Comaniciu and Peter Meer, “Mean Shift: A robust approach toward feature space analysis”. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002. pp. 603-619.
示例
>>> from sklearn.cluster import MeanShift
>>> import numpy as np
>>> X = np.array([[1, 1], [2, 1], [1, 0],
... [4, 7], [3, 5], [3, 6]])
>>> clustering = MeanShift(bandwidth=2).fit(X)
>>> clustering.labels_
array([1, 1, 1, 0, 0, 0])
>>> clustering.predict([[0, 0], [5, 5]])
array([1, 0])
>>> clustering
MeanShift(bandwidth=2)
方法
| 方法 | 说明 |
|---|---|
fit(self, X[, y]) |
执行聚类 |
fit_predict(self, X[, y]) |
在X上执行聚类并返回聚类标签 |
get_params(self[, deep]) |
获取此估计器的参数 |
predict(self, X) |
预测X中每个样本所属的最接近的聚类 |
set_params(self, **params) |
设置此估计器的参数 |
__init__(self, *, bandwidth=None, seeds=None, bin_seeding=False, min_bin_freq=1, cluster_all=True, n_jobs=None, max_iter=300)
初始化self。请参阅help(type(self))以获得准确的说明。
fit(self, X, y=None)
执行聚类
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 样本聚类 |
| y | Ignored |
fit_predict(self, X, y=None)
在X上执行聚类并返回聚类标签。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 输入数据 |
| y | Ignored 未使用,在此按约定呈现为api一致性。 |
| 返回值 | 说明 |
|---|---|
| labels | ndarray of shape (n_samples,) 聚类标签 |
get_params(self, deep=True)
获取此估计器的参数
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估计器的参数和所包含的作为估计量的子对象。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 映射到其值的参数名称 |
predict(self, X)
预测X中每一个样本所属的最接近的聚类。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix}, shape=[n_samples, n_features] 新的预测数据 |
| 返回值 | 说明 |
|---|---|
| labels | array, shape [n_samples,] 每个样本所属的聚类的索引 |
set_params(self, **params)
设置此估计器的参数
该方法适用于简单估计器以及嵌套对象(例如pipelines)。后者具有表单的 <component>__<parameter>参数,这样就可以更新嵌套对象的每个组件。
| 表格 | 说明 |
|---|---|
| **params | dict 估计器参数 |
| 返回值 | 说明书 |
|---|---|
| self | object 估计器实例 |