

ROC曲线¶
这个案例展示评估分类器输出质量的接收器工作特征曲线(ROC)是如何工作。
ROC曲线通常在Y轴上具有真正率,在X轴上具有假正率。这意味着该图的左上角是“理想”点-误报率为零,而正误报率为1。这不是很现实,但这确实意味着曲线下的较大区域(AUC)通常更好。
ROC曲线的“陡峭程度”也很重要,因为理想的是最大程度地提高真正率,同时最小化假正率。
ROC曲线通常用于二进制分类中以研究分类器的输出。为了将ROC曲线和ROC区域扩展到多标签分类,有必要对输出进行二值化。可以为每个标签绘制一条ROC曲线,但也可以通过将标签指示器矩阵的每个元素视为二进制预测(微平均)来绘制ROC曲线。
多标签分类的另一种评估方法是宏平均(macro-averaging),它对每个标签的分类给予同等的权重。
注意,请同时查看:sklearn.metrics.roc_auc_score,
输入:
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from scipy import interp
from sklearn.metrics import roc_auc_score
# 导入数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将输出二值化
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
# 增加一些噪音特征让问题变得更难一些
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
# 打乱并分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5,
random_state=0)
# 学习,预测
classifier = OneVsRestClassifier(svm.SVC(kernel='linear',
probability=True,
random_state=random_state))
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# 计算每个类别的ROC曲线和AUC面积
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 计算ROC曲线和AUC面积的微观平均(micro-averaging)
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
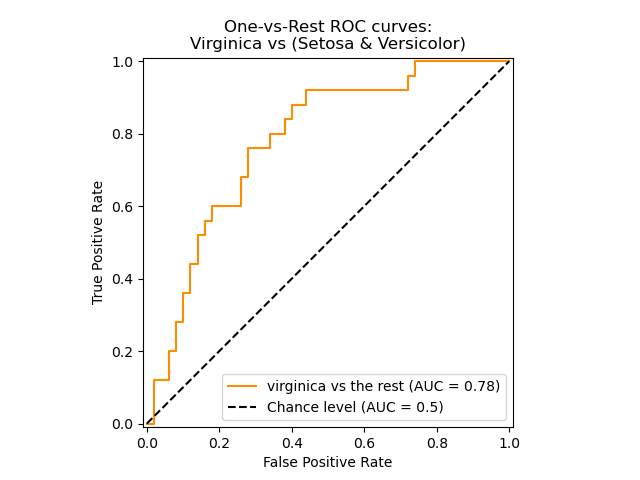
绘制其中一个具体类别的ROC曲线:
plt.figure()
lw = 2
plt.plot(fpr[2], tpr[2], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
输出:
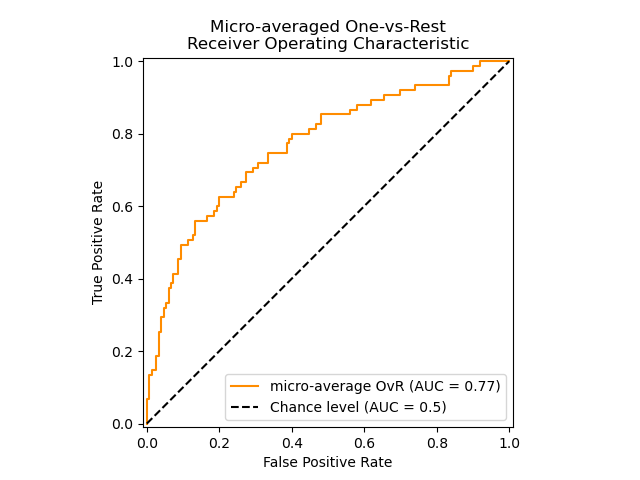
绘制多标签问题的ROC曲线
计算宏观平均ROC曲线和ROC面积。
# 首先收集所有的假正率
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# 然后在此点内插所有ROC曲线
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# 最终计算平均和ROC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
# 绘制全部的ROC曲线
plt.figure()
plt.plot(fpr["micro"], tpr["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Some extension of Receiver operating characteristic to multi-class')
plt.legend(loc="lower right")
plt.show()
输出:
/home/circleci/project/examples/model_selection/plot_roc.py:112: DeprecationWarning: scipy.interp is deprecated and will be removed in SciPy 2.0.0, use numpy.interp instead
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
ROC下的多类问题区域
sklearn.metrics.roc_auc_score函数可用于多类分类。 多类“一对一”方案比较类的每个唯一的成对组合。 在本节中,我们使用OvR和OvO方案计算AUC。 我们报告一个宏观平均值和一个患病率加权平均值。
y_prob = classifier.predict_proba(X_test)
macro_roc_auc_ovo = roc_auc_score(y_test, y_prob, multi_class="ovo",
average="macro")
weighted_roc_auc_ovo = roc_auc_score(y_test, y_prob, multi_class="ovo",
average="weighted")
macro_roc_auc_ovr = roc_auc_score(y_test, y_prob, multi_class="ovr",
average="macro")
weighted_roc_auc_ovr = roc_auc_score(y_test, y_prob, multi_class="ovr",
average="weighted")
print("One-vs-One ROC AUC scores:\n{:.6f} (macro),\n{:.6f} "
"(weighted by prevalence)"
.format(macro_roc_auc_ovo, weighted_roc_auc_ovo))
print("One-vs-Rest ROC AUC scores:\n{:.6f} (macro),\n{:.6f} "
"(weighted by prevalence)"
.format(macro_roc_auc_ovr, weighted_roc_auc_ovr))
输出:
One-vs-One ROC AUC scores:
0.698586 (macro),
0.665839 (weighted by prevalence)
One-vs-Rest ROC AUC scores:
0.698586 (macro),
0.665839 (weighted by prevalence)
脚本的总运行时间:(0分钟0.337秒)

