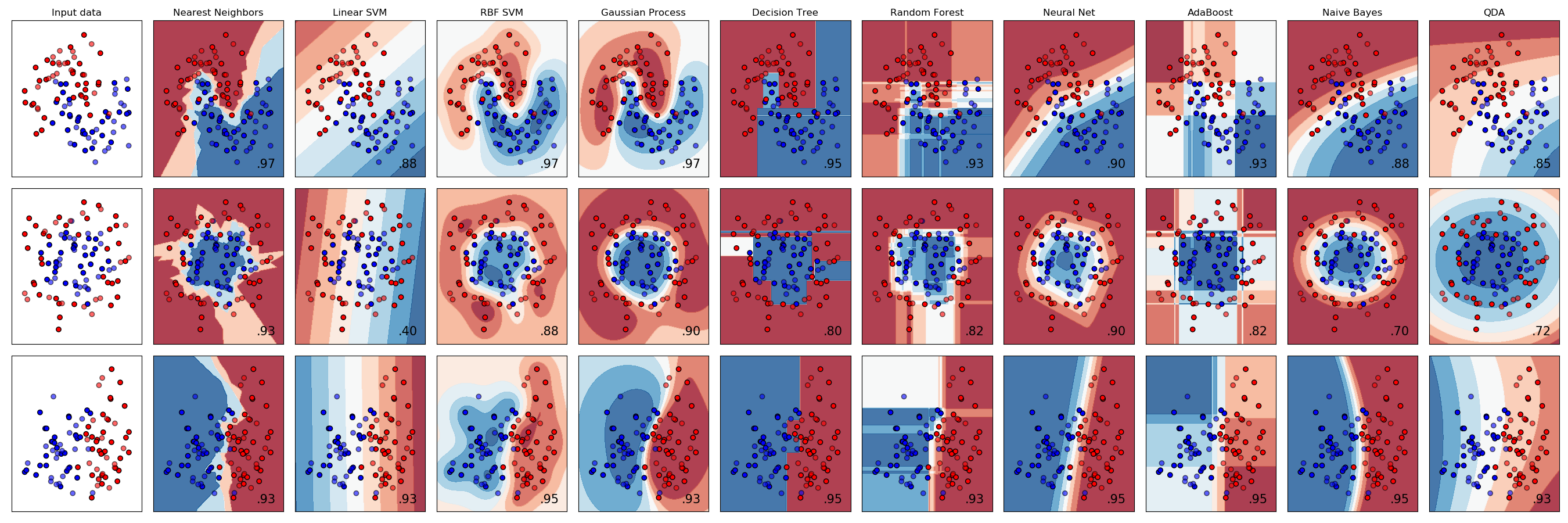
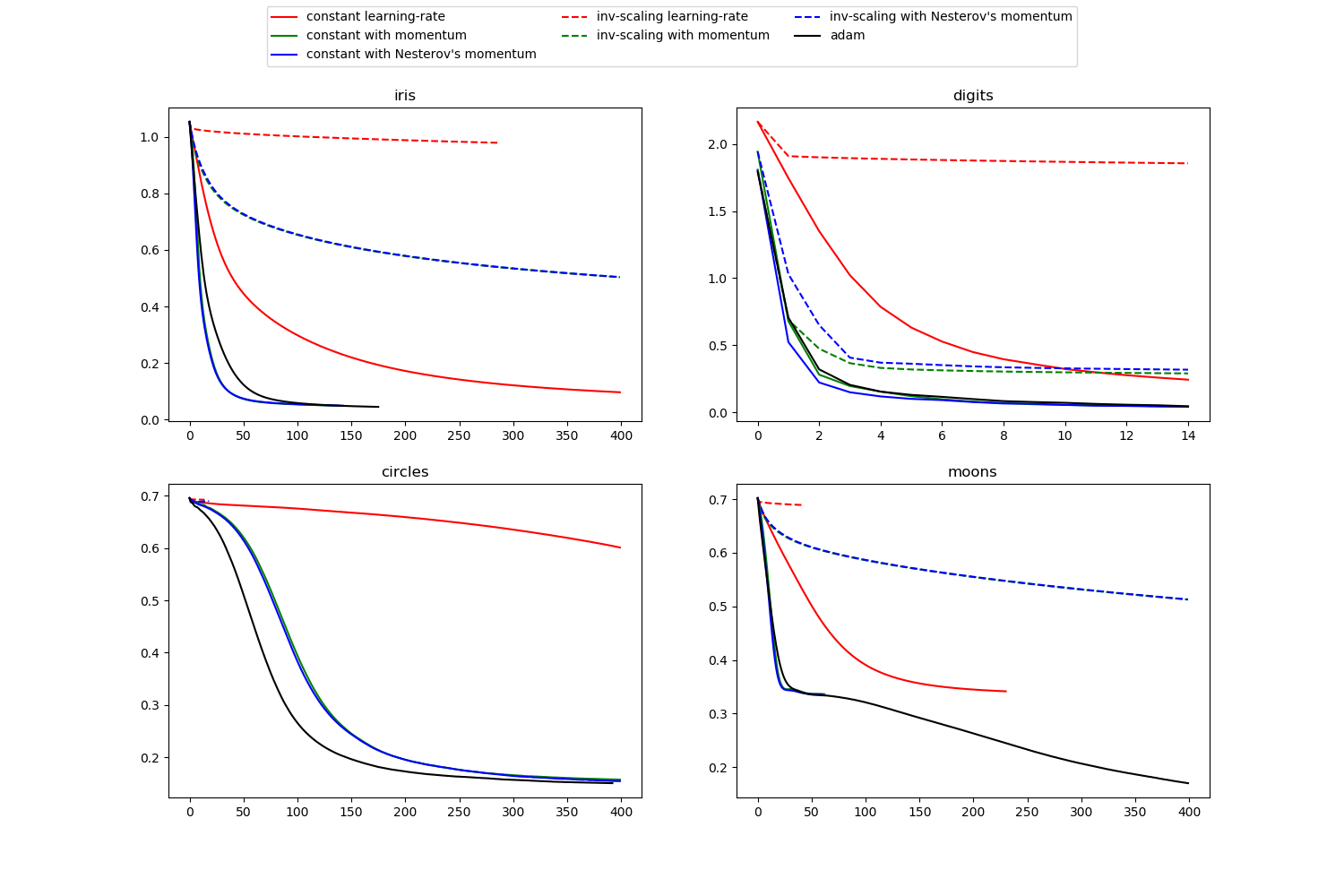
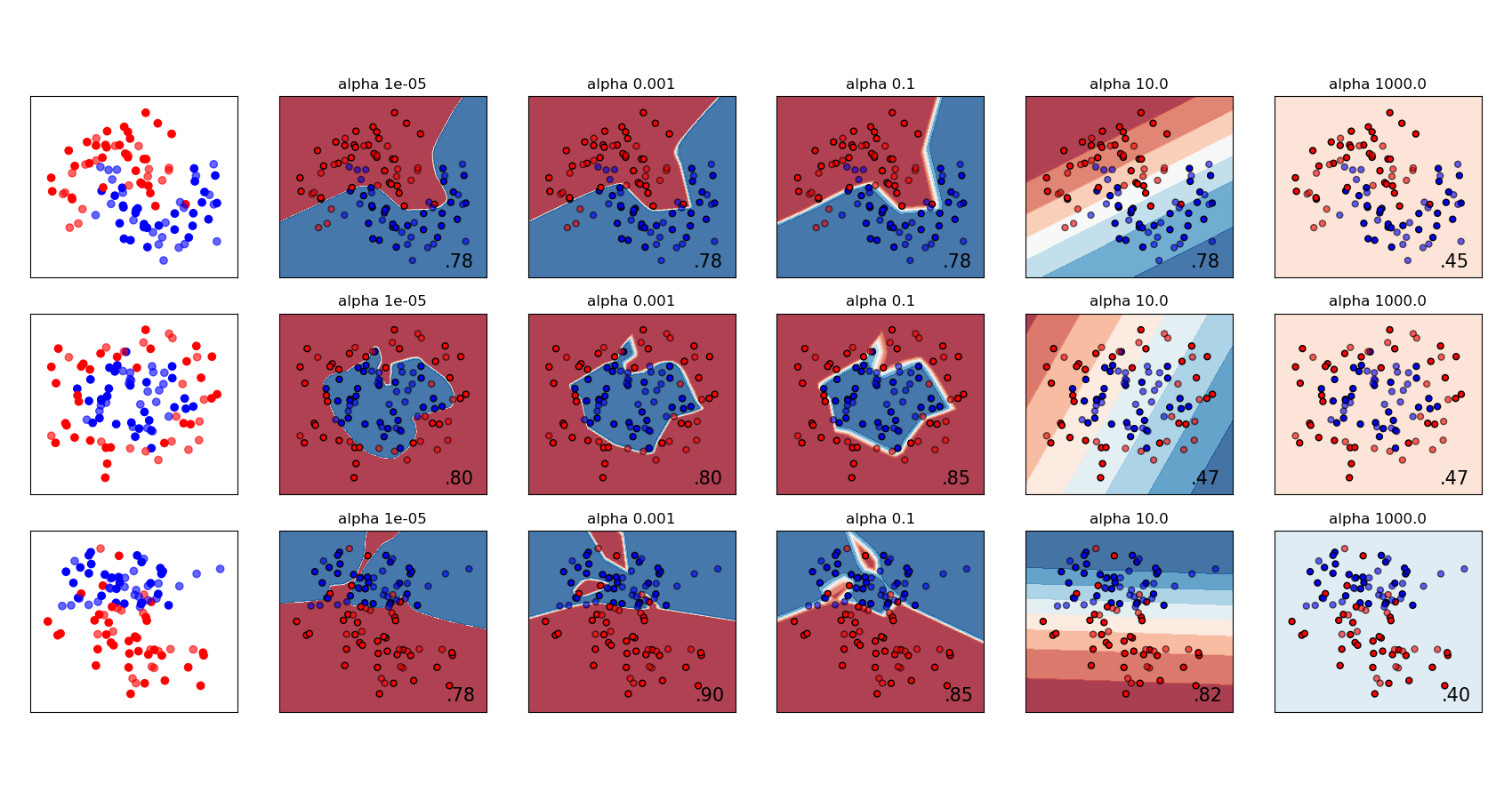
sklearn.neural_network.MLPClassifier¶
class sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100, ), activation='relu', *, solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10, max_fun=15000)
[源码]
多层感知器分类器。
这个模型使用LBFGS或随机梯度下降来优化对数损失函数。
版本0.18中的新功能。
| 参数 | 说明 |
|---|---|
| hidden_layer_sizes | tuple, length = n_layers - 2, default=(100,) 第i个元素代表第i个隐藏层中的神经元数量。 |
| activation | {‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, default=’relu’ 隐藏层的激活函数。 - 'identity',无操作激活,用于实现线性瓶颈,返回f(x)= x - 'logistic',logistic Sigmoid函数,返回f(x)= 1 / (1 + exp(x))。 - 'tanh',双曲tan函数,返回f(x)= tanh(x)。 - 'relu',整流线性单位函数,返回f(x)= max(0,x) |
| solver | {‘lbfgs’, ‘sgd’, ‘adam’}, default=’adam’ 权重优化的求解器。 - “ lbfgs”是quasi-Newton方法族的优化程序。 - “ sgd”是指随机梯度下降。 - “ adam”是指Kingma,Diederik和Jimmy Ba提出的基于随机梯度的优化器 注意:就训练时间和验证准确率而言,默认求解器“ adam”在相对较大的数据集(具有数千个训练样本或更多)上的效果很好。但是,对于小型数据集,“ lbfgs”可以收敛得更快并且性能更好。 |
| alpha | float, default=0.0001 L2惩罚(正则项)参数。 |
| batch_size | int, default=’auto’ 随机优化器的小批次的大小。如果求解器为“ lbfgs”,则分类器将不使用小批次批处理。设为“自动”时, batch_size=min(200, n_samples) |
| learning_rate | {‘constant’, ‘invscaling’, ‘adaptive’}, default=’constant’ 权重更新的学习速率表。 - ' constant '是一个恒定的学习速率,由' learning_rate_init '给出。 - “invscaling”通过使用“power_t”的缩放逆指数,逐步降低在每个时间步长“t”上的学习率。effective_learning_rate = learning_rate_init / pow(t, power_t) - 只要训练损失持续减少,‘adaptive’将学习率保持在‘learning_rate_init’不变。每次连续两个epoch不能减少至少tol的训练损失,或者如果“early_stop”开启,不能增加至少tol的验证分数,则当前学习率要除以5。 仅在 solver='sgd'时使用。 |
| learning_rate_init | double, default=0.001 使用的初始学习率。它控制更新权重的步长。仅在Solver ='sgd'或'adam'时使用。 |
| power_t | double, default=0.5 反比例学习率的指数。当learning_rate设置为“ invscaling”时,它用于更新有效学习率。仅在Solver ='sgd'时使用。 |
| max_iter | int, default=200 最大迭代次数。求解器迭代直到收敛(由“ tol”决定)或这个迭代次数。对于随机求解器(“ sgd”,“ adam”),请注意,这决定时期数(每个数据点将使用多少次),而不是梯度步数。 |
| shuffle | bool, default=True 是否在每次迭代中对样本进行打乱。仅在Solver ='sgd'或'adam'时使用。 |
| random_state | int, RandomState instance, default=None 决定用于权重和偏差初始化的随机数生成,如果使用了提前停止,则切分测试集和训练集,并在solver ='sgd'或'adam'时批量采样。在多个函数调用之间传递一个int值以获得可重复的结果。请参阅词汇表。 |
| tol | float, default=1e-4 优化公差。当 n_iter_no_change连续迭代的损失或分数没有通过至少tol得到改善时,除非将learning_rate设置为‘adaptive’,否则将认为达到收敛并停止训练。 |
| verbose | bool, default=False 是否将进度消息打印到标准输出。 |
| warm_start | bool, default=False 设置为True时,请重用上一个调用的解决方案以拟合初始化,否则,只需擦除以前的解决方案即可。请参阅词汇表。 |
| momentum | float, default=0.9 梯度下降更新的动量。应该在0到1之间。仅在solver ='sgd'时使用。 |
| nesterovs_momentum | boolean, default=True 是否使用内Nesterov的动量。仅在Solver ='sgd'且momentum> 0时使用。 |
| early_stopping | bool, default=False 当验证准确率没有提高时,是否使用提前停止来终止训练。如果设置为true,它将自动预留10%的训练数据作为验证,并在 n_iter_no_change连续几个时期,验证准确率没有提高至少tol时终止训练 。除多标签设置外,这个切分是分层的。仅在Solver ='sgd'或'adam'时有效 |
| validation_fraction | float, default=0.1 预留的训练数据比例作为提前停止的验证集。必须在0到1之间。仅当early_stopping为True时使用 |
| beta_1 | float, default=0.9 adam第一矩向量估计的指数衰减率,应在[0,1)范围内。仅在solver ='adam'时使用 |
| beta_2 | float, default=0.999 adam第二矩向量估计的指数衰减率,应在[0,1)范围内。仅在solver ='adam'时使用 |
| epsilon | float, default=1e-8 adam中数值稳定性的值。仅在solver ='adam'时使用 |
| n_iter_no_change | int, default=10 不满足 tol改进的最大时期数。仅在Solver ='sgd'或'adam'时有效0.20版中的新功能。 |
| max_fun | int, default=15000 仅在Solver ='lbfgs'时使用。损失函数调用的最大次数。求解器迭代直到收敛(由“ tol”确定),迭代次数达到max_iter或这个损失函数调用的次数。请注意,损失函数调用的次数将大于或等于 MLPClassifier的迭代次数。0.22版中的新功能。 |
| 属性 | 说明 |
|---|---|
| classes_ | ndarray or list of ndarray of shape (n_classes,) 每个输出的类别标签。 |
| loss_ | float 用损失函数计算的当前损失。 |
| coefs_ | list, length n_layers - 1 列表中的第i个元素表示与第i层相对应的权重矩阵。 |
| intercepts_ | list, length n_layers - 1 列表中的第i个元素表示与层i + 1对应的偏差向量。 |
| n_iter_ | int, 求解程序已运行的迭代次数。 |
| n_layers_ | int 层数。 |
| n_outputs_ | int 输出数量。 |
| out_activation_ | string 输出激活函数的名称。 |
注
MLPClassifier进行迭代训练,因为在每个时间步长都计算了损失函数相对于模型参数的偏导数以更新参数。
它还可以在损失函数中添加正则项,缩小模型参数以防止过拟合。
这个实现适用于表示为浮点值的密集numpy数组或稀疏矩阵数组的数据。
参考文献
Hinton, Geoffrey E.
“Connectionist learning procedures.” Artificial intelligence 40.1 (1989): 185-234.
Glorot, Xavier, and Yoshua Bengio. “Understanding the difficulty of
training deep feedforward neural networks.” International Conference on Artificial Intelligence and Statistics. 2010.
He, Kaiming, et al. “Delving deep into rectifiers: Surpassing human-level
performance on imagenet classification.” arXiv preprint arXiv:1502.01852 (2015).
Kingma, Diederik, and Jimmy Ba. “Adam: A method for stochastic
optimization.” arXiv preprint arXiv:1412.6980 (2014).
示例
>>> from sklearn.neural_network import MLPClassifier
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>> X, y = make_classification(n_samples=100, random_state=1)
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y,
... random_state=1)
>>> clf = MLPClassifier(random_state=1, max_iter=300).fit(X_train, y_train)
>>> clf.predict_proba(X_test[:1])
array([[0.038..., 0.961...]])
>>> clf.predict(X_test[:5, :])
array([1, 0, 1, 0, 1])
>>> clf.score(X_test, y_test)
0.8...
方法
| 方法 | 说明 |
|---|---|
fit(X,y) |
根据矩阵X和标签y的数据拟合模型 |
get_params([deep]) |
获取这个估计器的参数。 |
predict(X) |
使用多层感知器分类器进行预测 |
predict_log_proba(X) |
返回概率估计的对数。 |
predict_proba(X) |
概率估计。 |
score(X, y[, sample_weight]) |
返回给定测试数据和标签上的平均准确率。 |
set_params(**params) |
设置这个估计器的参数。 |
__init__(hidden_layer_sizes=(100, ), activation='relu', *, solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10, max_fun=15000)
[源码]
初始化self。详情可参阅 type(self)的帮助。
fit(X, y)
[源码]
根据矩阵X和标签y的数据拟合模型
| 参数 | 说明 |
|---|---|
| X | ndarray or sparse matrix of shape (n_samples, n_features) 输入数据。 |
| y | ndarray, shape (n_samples,) or (n_samples, n_outputs) 目标值(分类中的类别标签,回归中的实数)。 |
| 返回值 | 说明 |
|---|---|
| self | returns a trained MLP model. |
get_params(deep=True)
[源码]
获取这个估计器的参数。
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回这个估计器的参数和所包含的估计器子对象。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 参数名映射到其值 |
property partial_fit
使用给定数据的单次迭代更新模型。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix}, shape (n_samples, n_features) 输入数据。 |
| y | array-like, shape (n_samples,) 目标值。 |
| classes | array, shape (n_classes), default None 类越过所有对partial_fit的调用。可以通过 np.unique(y_all)获得,其中y_all是整个数据集的目标向量。第一次调用partial_fit时需要此参数,在后续调用中可以将其省略。请注意,y不需要包含classes中的所有标签。 |
| 返回值 | 说明 |
|---|---|
| self | returns a trained MLP model. |
predict(X)
[源码]
使用多层感知器分类器进行预测
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入数据。 |
| 返回值 | 说明 |
|---|---|
| y | ndarray, shape (n_samples,) or (n_samples, n_classes) 预测的类别。 |
predict_log_proba(X)
[源码]
返回概率估计的对数。
| 参数 | 说明 |
|---|---|
| X | ndarray of shape (n_samples, n_features) 输入数据。 |
| 返回值 | 说明 |
|---|---|
| log_y_prob | ndarray of shape (n_samples, n_classes) 模型中每个类别的样本的预期对数概率,类别按 self.classes_中的顺序排序 。等效于log(predict_proba(X)) |
predict_proba(X)
[源码]
概率估计。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix} of shape (n_samples, n_features) 输入数据。 |
| 返回值 | 说明 |
|---|---|
| y_prob | ndarray of shape (n_samples, n_classes) 模型中每个类别的样本的预测概率,类别按 self.classes_中的顺序排序。 |
score(X, y, sample_weight=None)
[源码]
返回给定测试数据和标签上的平均准确率。
在多标签分类中,这是子集准确性,这是一个严格的指标,因为您需要为每个样本正确预测每个标签集。
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 测试样本 |
| y | array-like of shape (n_samples,) or (n_samples, n_outputs) X的真实标签。 |
| sample_weight | array-like of shape (n_samples,), default=None 样本权重 |
| 返回值 | 说明 |
|---|---|
| score | float self.predict(X)关于y的平均准确率。 |
set_params(**params)
[源码]
设置这个估计器的参数。
该方法适用于简单的估计器以及嵌套对象(例如pipelines)。后者具有形式参数 <component>__<parameter>,以便可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估计器参数 |
| 返回值 | 说明 |
|---|---|
| self | object 估计器实例 |