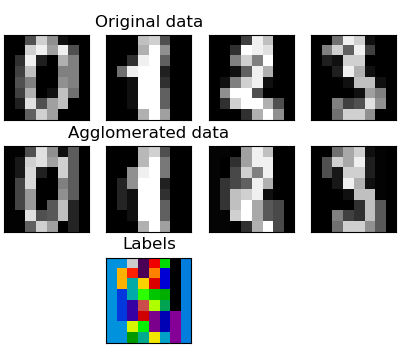
sklearn.cluster.FeatureAgglomeration¶
class sklearn.cluster.FeatureAgglomeration(n_clusters=2, *, affinity='euclidean', memory=None, connectivity=None, compute_full_tree='auto', linkage='ward', pooling_func=<function mean>, distance_threshold=None)
聚集特征
类似于聚合聚类,但递归合并特征而不是样本。
在用户指南中阅读更多内容。
| 参数 | 说明 |
|---|---|
| n_clusters | int, default=2 要查找的聚类数目。如果 distance_threshold 不是None, 它就必须是None。 |
| affinity | str or callable, default=’euclidean’ 用于计算连接的度量。可以是“euclidean”, “l1”, “l2”, “manhattan”, “cosine”, 或者“precomputed”。如果linkage是“ward”, 只有“euclidean”是被接受的。 |
| memory | str or object with the joblib.Memory interface, default=None 用于储存树计算的输出。默认情况下,不执行缓存。如果给出一个字符串,它就是缓存目录的路径。 |
| connectivity | array-like or callable, default=None 连接矩阵。为每个样本定义遵循给定数据结构的相邻样本。这可以是连接矩阵本身,也可以是可调用的,能将数据转换为连接矩阵,例如从kneighbors_graph派生的连接矩阵。默认为None,分层聚类算法是一种非结构化的聚类算法。 |
| compute_full_tree | ‘auto’ or bool, default=’auto’ 提前停止n_clusters树的构建。如果聚类的数量与样本数相比并不少,这对于减少计算时间是非常有用的。此选项仅在指定连接矩阵时才有用。还请注意,当改变聚类数量并使用缓存时,计算所有树可能更有利。如果 distance_threshold是None, 它必须是True。通过默认的compute_full_tree设置是“auto”, 当distance_threshold不是None的时候就等价于True,或者n_clusters的最大值在100~0.02 * n_samples之间。否则,“auto”等同False。 |
| linkage | {“ward”, “complete”, “average”, “single”}, default=”ward” 使用哪种联动标准。该算法将合并聚类,以最小化这一标准。 - Ward最小化会合并的聚类的差异。 - 平均使用两组每次观测的平均距离。 - 完全或最大连接使用两个集合的所有观测值之间的最大距离。 - 单次使用两组所有观测值之间的最小距离。 |
| pooling_func | callable, default=np.mean 这将聚集特征的值组合成一个值,并且应该接受一个形状为[M,N]的数组和关键字参数 axis=1,并将其缩小为一个大小为[M]的数组。 |
| distance_threshold | float, default=None 连接距离阈值高于该阈值,聚类将不会合并。如果不是None,则n_clusters必须为None,并且compute_full_tree必须为True。 |
| 属性 | 说明 |
|---|---|
| n_clusters_ | int 通过算法找到的聚类数。如果 distance_threshold=None=None,则它将等价于给定的n_clusters。 |
| labels_ | array-like of (n_features,) 每一特征的聚类标签 |
| n_leaves_ | int 层次树中的叶子节点数 |
| n_connected_components_ | int 图中连通分量的估计数 新版本0.21中: n_connected_components_被添加以代替n_components_ |
| children_ | array-like of shape (n_nodes-1, 2) 每个非叶节点的子节点。小于 n_features的值对应于原始样本树的叶子。大于或等于n_features的节点i是一个非叶节点,具有子节点children_[i - n_features]。或者,在第i次迭代时,将children[i][0]和children[i][1]合并成节点n_features + i。 |
示例
>>> import numpy as np
>>> from sklearn import datasets, cluster
>>> digits = datasets.load_digits()
>>> images = digits.images
>>> X = np.reshape(images, (len(images), -1))
>>> agglo = cluster.FeatureAgglomeration(n_clusters=32)
>>> agglo.fit(X)
FeatureAgglomeration(n_clusters=32)
>>> X_reduced = agglo.transform(X)
>>> X_reduced.shape
(1797, 32)
| 方法 | 说明 |
|---|---|
fit(self, X[, y]) |
对数据进行分层聚类 |
fit_transform(self, X[, y]) |
拟合数据,然后转换它。 |
get_params(self[, deep]) |
获取此估计器的参数 |
inverse_transform(self, Xred) |
逆变换 |
set_params(self, **params) |
设置此估计器的参数 |
transform(self, X) |
使用构建的聚类变换一个新的矩阵 |
__init__(self, n_clusters=2, *, affinity='euclidean', memory=None, connectivity=None, compute_full_tree='auto', linkage='ward', pooling_func=<function mean at 0x7f962a37d280>, distance_threshold=None)
初始化self。请参阅help(type(self))以获得准确的说明。
fit(self, X, y=None, **params)
对数据进行分层聚类
| 参数 | 说明 |
|---|---|
| X | array-like of shape (n_samples, n_features) 数据 |
| y | Ignored |
| 返回值 | 说明 |
|---|---|
| self | - |
property fit_predict
根据特征或距离矩阵拟合分层聚类,并返回聚类标签。
| 参数 | 说明 |
|---|---|
| X | array-like, shape (n_samples, n_features) or (n_samples, n_samples) 要聚类的训练实例,或实例之间的距离, 如果affinity='precomputed' |
| y | Ignored 未使用,在此按约定呈现为API一致性。 |
| 返回值 | 说明 |
|---|---|
| labels | ndarray, shape (n_samples,) 类标签 |
fit_transform(self, X, y=None, **fit_params)
拟合数据,然后转换它。
使用可选参数fit_params将转换器拟合到X和y,并返回转换版本的X。
| 参数 | 说明 |
|---|---|
| X | {array-like, sparse matrix, dataframe} of shape (n_samples, n_features) |
| y | ndarray of shape (n_samples,), default=None 目标值 |
| 返回值 | 说明 |
|---|---|
| **fit_params | dict 转换后的数组 |
get_params(self, deep=True)
获取此估计器的参数
| 参数 | 说明 |
|---|---|
| deep | bool, default=True 如果为True,则将返回此估计器的参数和所包含的作为估计量的子对象。 |
| 返回值 | 说明 |
|---|---|
| params | mapping of string to any 映射到其值的参数名称 |
inverse_transform(self, Xred)
逆变换。返回大小为nb_features的向量,其值为Xred,分配给每一组特征。
| 参数 | 说明 |
|---|---|
| Xred | array-like of shape (n_samples, n_clusters) or (n_clusters,) 要分配给每一组样本的值。 |
| 返回值 | 说明 |
|---|---|
| X | array, shape=[n_samples, n_features] or [n_features] 一个大小为n_samples的向量,其值为Xred,值分配给每一组样本。 |
set_params(self, **params)
设置此估计器的参数
该方法适用于简单估计器以及嵌套对象(例如pipelines)。后者具有表单的 <component>__<parameter>参数,这样就可以更新嵌套对象的每个组件。
| 参数 | 说明 |
|---|---|
| **params | dict 估计器参数 |
| 返回值 | 说明书 |
|---|---|
| self | object 估计器实例 |
transform(self, X)
使用构建的聚类变换一个新的矩阵
| 参数 | 列表 |
|---|---|
| X | array-like of shape (n_samples, n_features) or (n_samples,) 输入数据。 |
| 参数 | 说明 |
|---|---|
| X_trans | {array-like, sparse matrix} of shape (n_samples, n_clusters) N维观测的M×N阵或M一维观测的长度M阵 |
| 返回值 | 说明 |
|---|---|
| Y | array, shape = [n_samples, n_clusters] or [n_clusters] 每个特性簇的存储值 |