

高斯混合模型正弦曲线¶
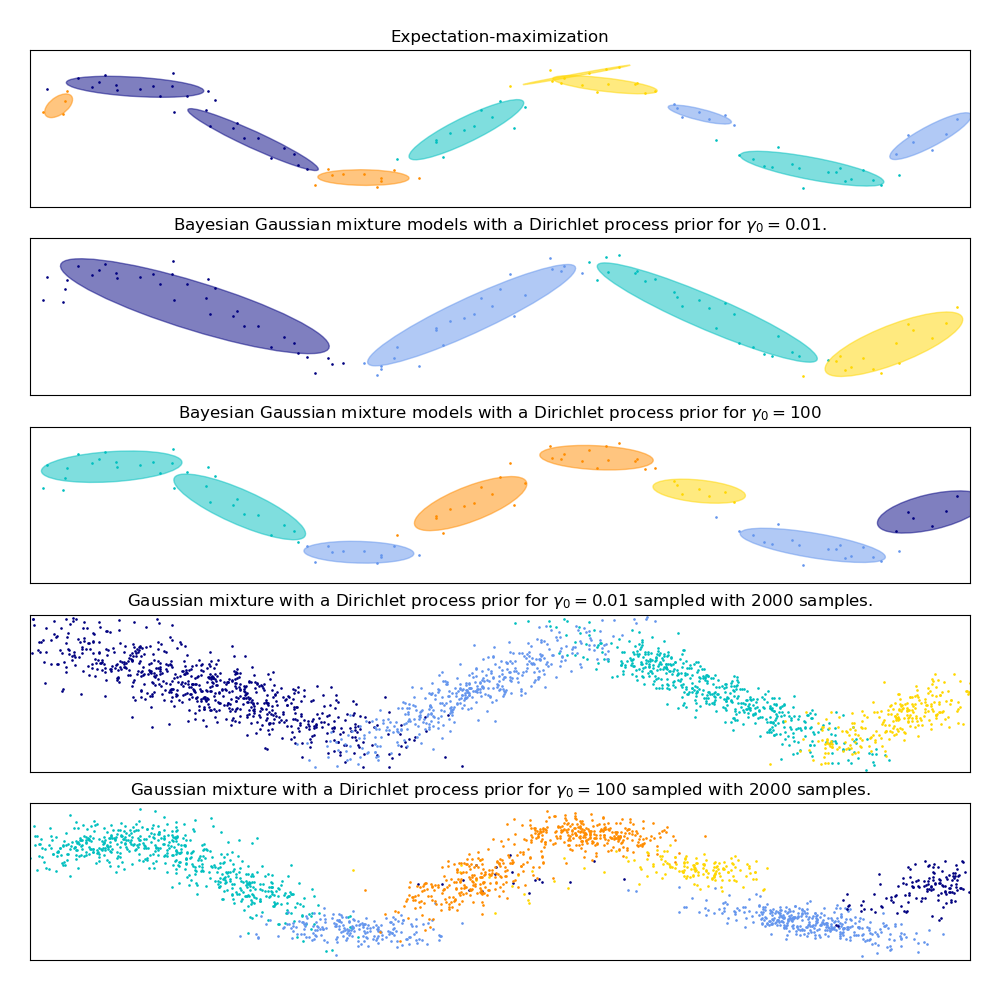
此示例演示了高斯混合模型的行为,该模型适合于未从混合高斯随机变量中取样的数据。该数据集由100个点按照噪声正弦曲线松散间隔形成。因此,高斯分量的数目不存在真正的值。
第一个模型是一个经典的高斯混合模型,它包含10个分量,拟合期望最大化算法。
第二个模型是带Dirichlet过程先验拟合和变分推理的贝叶斯高斯混合模型。聚集先验的低值使模型倾向于活跃成分的低值。该模型“决定”将其建模能力集中在数据集结构的总体图上:用非对角协方差矩阵建模的交替方向点群。这些交替方向大致捕捉原始正弦信号的交替性质。
第三种模型也是带有Dirichlet过程先验的贝叶斯高斯混合模型,但这一次的聚集先验值较高,给模型更多的自由度来对数据的细粒度结构进行建模。结果是一个具有更多活跃成分的混合体,类似于第一个模型,在第一个模型中,我们任意地将成分的数量固定为10。
哪一种模式是最好的,取决于主观判断:我们是更喜欢模型能够捕捉一个总体图, 以此来总结和解释绝大多数的数据结构, 并且或略细节, 还是喜欢这个模型与信号的高密度区域密切相关?
最后两个图片展示了我们如何从最后两个模型中取样。得到的样本分布看起来与原始数据分布不完全一样。这种差异主要来自于我们所使用的模型所产生的近似误差,该模型假设数据是由有限个高斯分量而不是连续的噪声正弦曲线生成的。
import itertools
import numpy as np
from scipy import linalg
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import mixture
print(__doc__)
color_iter = itertools.cycle(['navy', 'c', 'cornflowerblue', 'gold',
'darkorange'])
def plot_results(X, Y, means, covariances, index, title):
splot = plt.subplot(5, 1, 1 + index)
for i, (mean, covar, color) in enumerate(zip(
means, covariances, color_iter)):
v, w = linalg.eigh(covar)
v = 2. * np.sqrt(2.) * np.sqrt(v)
u = w[0] / linalg.norm(w[0])
# as the DP will not use every component it has access to
# unless it needs it, we shouldn't plot the redundant
# components.
if not np.any(Y == i):
continue
plt.scatter(X[Y == i, 0], X[Y == i, 1], .8, color=color)
# Plot an ellipse to show the Gaussian component
angle = np.arctan(u[1] / u[0])
angle = 180. * angle / np.pi # convert to degrees
ell = mpl.patches.Ellipse(mean, v[0], v[1], 180. + angle, color=color)
ell.set_clip_box(splot.bbox)
ell.set_alpha(0.5)
splot.add_artist(ell)
plt.xlim(-6., 4. * np.pi - 6.)
plt.ylim(-5., 5.)
plt.title(title)
plt.xticks(())
plt.yticks(())
def plot_samples(X, Y, n_components, index, title):
plt.subplot(5, 1, 4 + index)
for i, color in zip(range(n_components), color_iter):
# as the DP will not use every component it has access to
# unless it needs it, we shouldn't plot the redundant
# components.
if not np.any(Y == i):
continue
plt.scatter(X[Y == i, 0], X[Y == i, 1], .8, color=color)
plt.xlim(-6., 4. * np.pi - 6.)
plt.ylim(-5., 5.)
plt.title(title)
plt.xticks(())
plt.yticks(())
# Parameters
n_samples = 100
# Generate random sample following a sine curve
np.random.seed(0)
X = np.zeros((n_samples, 2))
step = 4. * np.pi / n_samples
for i in range(X.shape[0]):
x = i * step - 6.
X[i, 0] = x + np.random.normal(0, 0.1)
X[i, 1] = 3. * (np.sin(x) + np.random.normal(0, .2))
plt.figure(figsize=(10, 10))
plt.subplots_adjust(bottom=.04, top=0.95, hspace=.2, wspace=.05,
left=.03, right=.97)
# Fit a Gaussian mixture with EM using ten components
gmm = mixture.GaussianMixture(n_components=10, covariance_type='full',
max_iter=100).fit(X)
plot_results(X, gmm.predict(X), gmm.means_, gmm.covariances_, 0,
'Expectation-maximization')
dpgmm = mixture.BayesianGaussianMixture(
n_components=10, covariance_type='full', weight_concentration_prior=1e-2,
weight_concentration_prior_type='dirichlet_process',
mean_precision_prior=1e-2, covariance_prior=1e0 * np.eye(2),
init_params="random", max_iter=100, random_state=2).fit(X)
plot_results(X, dpgmm.predict(X), dpgmm.means_, dpgmm.covariances_, 1,
"Bayesian Gaussian mixture models with a Dirichlet process prior "
r"for $\gamma_0=0.01$.")
X_s, y_s = dpgmm.sample(n_samples=2000)
plot_samples(X_s, y_s, dpgmm.n_components, 0,
"Gaussian mixture with a Dirichlet process prior "
r"for $\gamma_0=0.01$ sampled with $2000$ samples.")
dpgmm = mixture.BayesianGaussianMixture(
n_components=10, covariance_type='full', weight_concentration_prior=1e+2,
weight_concentration_prior_type='dirichlet_process',
mean_precision_prior=1e-2, covariance_prior=1e0 * np.eye(2),
init_params="kmeans", max_iter=100, random_state=2).fit(X)
plot_results(X, dpgmm.predict(X), dpgmm.means_, dpgmm.covariances_, 2,
"Bayesian Gaussian mixture models with a Dirichlet process prior "
r"for $\gamma_0=100$")
X_s, y_s = dpgmm.sample(n_samples=2000)
plot_samples(X_s, y_s, dpgmm.n_components, 1,
"Gaussian mixture with a Dirichlet process prior "
r"for $\gamma_0=100$ sampled with $2000$ samples.")
plt.show()
脚本的总运行时间:(0分0.515秒)

