

SVM-Anova:具有单变量特征选择的SVM¶
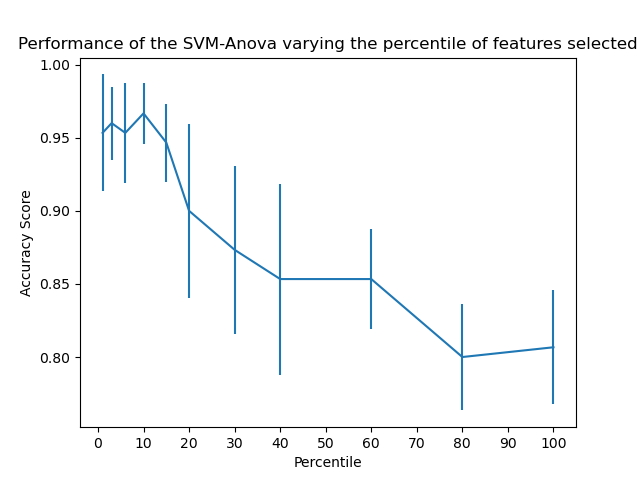
本案例说明如何在运行SVC(支持向量分类器)以改善分类评分之前执行单变量特征选择。 我们使用鸢尾花数据集(4个特征)并添加36个非信息特征。我们发现,当我们选择大约10%的特征时,我们的模型将获得最佳性能。
输入:
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectPercentile, chi2
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# #############################################################################
# 导入数据以备后续处理
X, y = load_iris(return_X_y=True)
# 增加非信息特征
np.random.seed(0)
X = np.hstack((X, 2 * np.random.random((X.shape[0], 36))))
# #############################################################################
# 创建一个特征选择变换类,一个标准化类和一个SVM实例,我们将它们组合在一起以得到一个成熟的估算器
clf = Pipeline([('anova', SelectPercentile(chi2)),
('scaler', StandardScaler()),
('svc', SVC(gamma="auto"))])
# #############################################################################
# 将交叉验证得分绘制为特征百分位数的函数
score_means = list()
score_stds = list()
percentiles = (1, 3, 6, 10, 15, 20, 30, 40, 60, 80, 100)
for percentile in percentiles:
clf.set_params(anova__percentile=percentile)
this_scores = cross_val_score(clf, X, y)
score_means.append(this_scores.mean())
score_stds.append(this_scores.std())
plt.errorbar(percentiles, score_means, np.array(score_stds))
plt.title(
'Performance of the SVM-Anova varying the percentile of features selected')
plt.xticks(np.linspace(0, 100, 11, endpoint=True))
plt.xlabel('Percentile')
plt.ylabel('Accuracy Score')
plt.axis('tight')
plt.show()
脚本的总运行时间:(0分钟0.358秒)

