

缓存最近邻¶
此案例演示了如何在KNeighborsClassifier类使用k个最近邻点之前对最近邻点进行预计算。 KNeighborsClassifier可以在内部计算最近邻,但是预计算它们可以带来很多好处,例如更好的参数控制,多次使用的缓存或自定义实现。
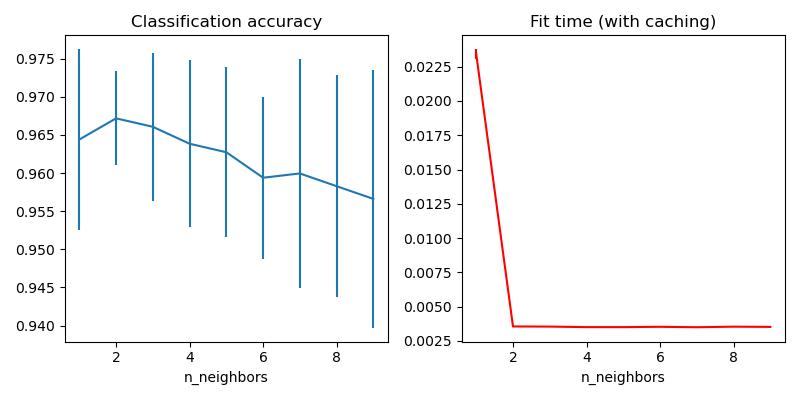
在这里,我们使用管道的缓存属性在KNeighborsClassifier的多个拟合之间缓存最近邻图。第一次调用很慢,因为它会计算邻居图,而随后的调用会更快,因为它们不需要重新计算图。 由于数据集较小,因此持续时间较小,但是当数据集变大或要搜索的参数网格较大时,增益可能会更大。
输出:
输入:
# 作者: Tom Dupre la Tour
#
# 执照: BSD 3 clause
from tempfile import TemporaryDirectory
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsTransformer, KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_digits
from sklearn.pipeline import Pipeline
print(__doc__)
X, y = load_digits(return_X_y=True)
n_neighbors_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 转换器使用网格搜索中所需的最大邻居数来计算最近邻图。分类器模型根据自己的n_neighbors参数的要求过滤最近的邻居图。
graph_model = KNeighborsTransformer(n_neighbors=max(n_neighbors_list),
mode='distance')
classifier_model = KNeighborsClassifier(metric='precomputed')
# 请注意,我们为"memory"提供了一个目录来缓存图计算,该图计算在调整分类器的超参数时将多次使用。
with TemporaryDirectory(prefix="sklearn_graph_cache_") as tmpdir:
full_model = Pipeline(
steps=[('graph', graph_model), ('classifier', classifier_model)],
memory=tmpdir)
param_grid = {'classifier__n_neighbors': n_neighbors_list}
grid_model = GridSearchCV(full_model, param_grid)
grid_model.fit(X, y)
# 绘制网格搜索的结果
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
axes[0].errorbar(x=n_neighbors_list,
y=grid_model.cv_results_['mean_test_score'],
yerr=grid_model.cv_results_['std_test_score'])
axes[0].set(xlabel='n_neighbors', title='Classification accuracy')
axes[1].errorbar(x=n_neighbors_list, y=grid_model.cv_results_['mean_fit_time'],
yerr=grid_model.cv_results_['std_fit_time'], color='r')
axes[1].set(xlabel='n_neighbors', title='Fit time (with caching)')
fig.tight_layout()
plt.show()
脚本的总运行时间:(0分钟5.569秒)

